Feature Input
All standard spatial analysis tools accept features as input. Features can be specified in one of the following ways:
Item (of type
Feature Layer CollectionorFeature Collection) - only the first feature layer is usedInstance of
Feature Layer,Feature Layer Collection, orFeature CollectionFeature Service URL as a string,
Python dict in the format outlined in the REST API featureCollection
For point feature layers, the following inputs may additonally be used for convenience:
(lat, long) pair for point feature layer
dict with ‘location’ as key (eg result from geocoding)
All the spatial analysis tools from the analyze_patterns, enrich_data, find_locations, manage_data, summarize_data and use_proximity submodules, in one place for convenience.
aggregate_points
-
arcgis.features.analysis.aggregate_points(point_layer, polygon_layer=None, keep_boundaries_with_no_points=True, summary_fields=[], group_by_field=None, minority_majority=False, percent_points=False, output_name=None, context=None, gis=None, estimate=False, future=False, bin_type=None, bin_size=None, bin_size_unit=None) 
The Aggregate Points task works with a layer of point features and a layer of polygon features. It first figures out which points fall within each polygon’s area. After determining this point-in-polygon spatial relationship, statistics about all points in the polygon are calculated and assigned to the area. The most basic statistic is the count of the number of points within the polygon, but you can get other statistics as well.
For example, if your points represented coffee shops and each point has a TOTAL_SALES attribute, you can get statistics like the sum of all TOTAL_SALES within the polygon, or the minimum or maximum TOTAL_SALES value, or the standard deviation of all sales within the polygon.
Parameter
Description
point_layer
Required point layer. The point features that will be aggregated into the polygons in the polygon_layer. See Feature Input.
polygon_layer
Optional polygon layer. The polygon features (areas) into which the input points will be aggregated. See Feature Input. The polygon_layer is required if the bin_type, bin_size and bin_size_unit are not specified.
keep_boundaries_with_no_points
Optional boolean. A Boolean value that specifies whether the polygons that have no points within them should be returned in the output. The default is true.
summary_fields
Optional list of strings. A list of field names and statistical summary type that you wish to calculate for all points within each polygon. Note that the count of points within each polygon is always returned. summary type is one of the following:
Sum - Adds the total value of all the points in each polygon
Mean - Calculates the average of all the points in each polygon.
Min - Finds the smallest value of all the points in each polygon.
Max - Finds the largest value of all the points in each polygon.
Stddev - Finds the standard deviation of all the points in each polygon.
Example [fieldName1 summaryType1,fieldName2 summaryType2].
group_by_field
Optional string. A field name in the point_layer. Points that have the same value for the group by field will have their own counts and summary field statistics. You can create statistical groups using an attribute in the analysis layer. For example, if you are aggregating crimes to neighborhood boundaries, you may have an attribute Crime_type with five different crime types. Each unique crime type forms a group, and the statistics you choose will be calculated for each unique value of Crime_type. When you choose a grouping attribute, two results are created: the result layer and a related table containing the statistics.
minority_majority
Optional boolean. This boolean parameter is applicable only when a group_by_field is specified. If true, the minority (least dominant) or the majority (most dominant) attribute values for each group field within each boundary are calculated. Two new fields are added to the aggregated_layer prefixed with Majority_ and Minority_. The default is false.
percent_points
Optional boolean. This boolean parameter is applicable only when a group_by_field is specified. If set to true, the percentage count of points for each unique group_by_field value is calculated. A new field is added to the group summary output table containing the percentages of each attribute value within each group.
If minority_majority is true, two additional fields are added to the aggregated_layer containing the percentages of the minority and majority attribute values within each group.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For aggregate_points, there are three settings (overwrite is required).
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
bin_type
Optional String. The type of bin that will be generated and points will be aggregated into. Bin options are as follows: Hexagon and Square. Square is the Default. When generating bins, for Square, the number and units specified determine the height and length of the square. For Hexagon, the number and units specified determine the distance between parallel sides. Either bin_type or polygon_layer must be specified. If bin_type is chosen, then bin_size and bin_size_unit specifying the size of the bins must be included.
bin_size
Optional Float. The distance for the bins of type bin_type that the point_layer will be aggregated into. When generating bins for Square the number and units specified determine the height and length of the square. For Hexagon, the number and units specified determine the distance between parallel sides.
bin_size_unit
Optional String. The linear unit to be used with the distance value specified in bin_size. Values: Meters, Kilometers, Feet, Miles, NauticalMiles, or Yards
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To find number of permits issued in each zip code of US. agg_result = aggregate_points(point_layer=permits, polygon_layer=zip_codes, keep_boundaries_with_no_points=False, summary_fields=["DeclValNu mean","DeclValNu2 mean"], group_by_field='Declared_V', minority_majority=True, percent_points=True, output_name="aggregated_permits", context={"extent":{"xmin":-8609738.077325115,"ymin":4743483.445485223,"xmax":-8594030.268012533,"ymax":4752206.821338257,"spatialReference":{"wkid":102100,"latestWkid":3857}}})
calculate_composite_index
-
arcgis.features.analysis.calculate_composite_index(input_layer, input_variables, index_method=None, output_index_reverse=False, output_index_min_max=None, output_name=None, context=None, gis=None, future=False) The Calculate Composite Index task combines multiple numeric variables to create a single index. This task is only available in ArcGIS Online and Enterprise 11.3+.
Parameter
Description
input_layer
Required layer. The input table or features containing the variables that will be combined into the index.
Syntax: As described in detail in the Feature input topic, this parameter can be one of the following:
A URL to a
feature service layerwith an optional filter to select specific features
#Example #1: Feature Layer with selection >>> output = calculate_composite_index( input_layer= { "url": <feature service layer url>, "filter": <where clause>}, ... ) #Example #2: Feature Collection >>> output = calculate_composite_index( input_layer= {" "layerDefinition": {}, "featureSet": {}, "filter": <where clause>}, ..., )
input_variables
Required list of dictionaries. The variables that will be combined to create the index. Provide at least two variables. For each variable, specify the following:
field is the numeric field from the inputLayer containing the variable. Any records in the field with missing values will not be included in the analysis.
reverseVariable specifies whether the values of the variable will be reversed. If no value is specified, the value will be set to False. When True the feature or record that originally had the highest value will have the lowest value, and vice versa. Values will be reversed after scaling. To create an index, variables must be on a compatible scale; reversing some variables may be required to ensure the meaning of low and high values in each variable is consistent.
weight is the relative influence of the variable on the index. If each variable should have equal contribution, set the value to 1. Increase or decrease the weight to reflect the relative importance of the variable. For example, if a variable is twice as important as the others, use a weight of 2.
#Example: >>> output = calculate_composite_index( ..., input_variables = [ {"field":"median_income", "reverseVariable": True, "weight": 2}, {"field": "pct_uninsured", "reverseVariable": False, "weight": 1}, {"field": "pct_unemployed", "reverseVariable": False, "weight": 1} ], ..., )
index_method
Optional string. The methods that will be used to scale the inputVariables and combine the scaled variables to create the index.
Scaling is a type of preprocessing that ensures the variables are on a compatible scale before they are combined. These scaled variables are then combined to create a single index value. The following options are available:
meanScaled the index by scaling the input variables between 0 and 1 (minimum-maximum scaling) and calculating the mean of the scaled values. This method is useful for creating an index that is easy to interpret. The shape of the distribution and outliers in the input variables will impact the index.
meanPercentile creates the index by scaling the ranks of the input variables between 0 and 1 (scaling by percentile) and calculating the mean of the scaled ranks. This option is useful when the rankings of the variable values are more important than the differences between values. The shape of the distribution and outliers in the input variables will not impact the index.
meanRaw creates the index by calculating the mean of the raw input variables. This option is useful when variables are already on a compatible scale.
geomeanScaled creates the index by scaling the input variables between 0 and 1 (minimum-maximum scaling) and calculating the geometric mean of the scaled values. High values will not cancel low values, so this option is useful for creating an index in which higher index values will occur only when there are high values in multiple variables.
geomeanPercentile creates the index by scaling the ranks of the input variables between 0 and 1 (scaling by percentile) and calculating the geometric mean of the scaled ranks. This option is useful when the rankings of the variable values are more important than the differences between values and when high variable values should not cancel out low variable values.
geomeanRaw creates the index by calculating the geometric mean of the raw input variables. This option is useful when variables are already on a compatible scale and when high variable values should not cancel out low variable values.
sumFlagsPercentile creates the index by counting the number of input variables with values greater than or equal to the 90th percentile. This method is useful for identifying locations that may be considered the most extreme or the most in need.
Values:
meanScaled
meanPercentile
meanRaw
geomeanScaled
geomeanPercentile
geomeanRaw
sumFlagsPercentile
Default: meanScaled
output_index_reverse
Optional boolean. Specifies whether the output index values will be reversed in direction. When checked, high index values will be treated as low index values and vice versa. Reversing is applied after combining the scaled variables. The default is False.
output_index_min_max
Optional list of one dictionary. The minimum and maximum of the output index values. Specifying a minimum and maximum value will apply minimum-maximum scaling to the combined variables.
# Example: >>> output = calculate_composite_index( ..., ouput_index_min_max= [ {'min': 0, 'max': 100} ], ..., )
output_name
Optional dictionary. If provided, the task will create a feature service of the results. You define the name of the service. If no argument is provided, the task will return a feature collection.
# Example #1: >>> output = calculate_composite_index( ..., output_name={ "serviceProperties": { "name": "<service name>" } }, ...
You can overwrite an existing feature service by providing the itemId value of the existing feature service and setting the overwrite property to True. Including the serviceProperties parameter is optional. As described in the Feature output topic, you must either be the owner of the feature service or have administrative privileges to perform the overwrite.
# Example #2: >>> output = calculate_composite_index( ..., ouput_name= { "itemProperties": { "itemId": "<itemID of existing service>", "overwrite": True } }, ) # Example #3: >>> output = calculate_composite_index( ..., ouput_name= { "serviceProperties": { "name": "<existing service name>" }, "itemProperties": { "itemId": "<itemID of the existing feature service>", "overwrite": True } }, ... )
context
Optional dict. The Context parameter contains the following additional settings that affect task operation:
Extent (extent)—A bounding box that defines the analysis area. Only input features that intersect the bounding box will be analyzed.
Output spatial reference (outSR)—The output features will be projected into the output spatial reference.
# Example: >>> output = calculate_composite_index( ..., context= { "extent" : {extent}, "outSR" : {spatial reference} }, ..., )
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.future
Optional boolean. If True, the task will be performed asynchronously.
- Returns
FeatureLayerif output_name is specified, else aFeatureCollectionobject.
# USAGE EXAMPLE: To create a social vulnerability index. index = calculate_composite_index( input_layer=demographicsLayer, input_variables=[ {'field':'pct_uninsured', 'reverseVariable': True, 'weight': 2}, {'field': 'pct_unemployed', 'reverseVariable': False, 'weight': 1} ], index_method='meanPercentile', output_index_reverse=True, output_index_min_max=[ {'min': 0, 'max': 100} ], output_name="Social vulnerability index")
calculate_density
-
arcgis.features.analysis.calculate_density(input_layer, field=None, cell_size=None, cell_size_units='Meters', radius=None, radius_units=None, bounding_polygon_layer=None, area_units=None, classification_type='EqualInterval', num_classes=10, output_name=None, context=None, gis=None, estimate=False, future=False) 
The calculate_density function creates a density map from point or line features by spreading known quantities of some phenomenon (represented as attributes of the points or lines) across the map. The result is a layer of areas classified from least dense to most dense.
For point input, each point should represent the location of some event or incident, and the result layer represents a count of the incident per unit area. A higher density value in a new location means that there are more points near that location. In many cases, the result layer can be interpreted as a risk surface for future events. For example, if the input points represent locations of lightning strikes, the result layer can be interpreted as a risk surface for future lightning strikes.
For line input, the line density surface represents the total amount of line that is near each location. The units of the calculated density values are the length of line per unit area. For example, if the lines represent rivers, the result layer will represent the total length of rivers that are within the search radius. This result can be used to identify areas that are hospitable to grazing animals.
Parameter
Description
input_layer
Required layer. The point or line features from which to calculate density. See Feature Input.
field
Optional string. A numeric field name specifying the number of incidents at each location. For example, if you have points that represent cities, you can use a field representing the population of the city as the count field, and the resulting population density layer will calculate larger population densities near cities with larger populations. If not specified, each location will be assumed to represent a single count.
cell_size
Optional float. This value is used to create a mesh of points where density values are calculated. The default is approximately 1/1000th of the smaller of the width and height of the analysis extent as defined in the context parameter. The smaller the value, the smoother the polygon boundaries will be. Conversely, with larger values, the polygon boundaries will be more coarse and jagged.
cell_size_units
Optional string. The units of the cell_size value. Choice list: [‘Miles’, ‘Feet’, ‘Kilometers’, ‘Meters’]
radius
Optional float. A distance specifying how far to search to find point or line features when calculating density values.
radius_units
Optional string. The units of the radius parameter. If no distance is provided, a default will be calculated that is based on the locations of the input features and the values in the count field (if a count field is provided). Choice list: [‘Miles’, ‘Feet’, ‘Kilometers’, ‘Meters’]
bounding_polygon_layer
Optional layer. A layer specifying the polygon(s) where you want densities to be calculated. For example, if you are interpolating densities of fish within a lake, you can use the boundary of the lake in this parameter and the output will only draw within the boundary of the lake. See Feature Input.
area_units
Optional string. The units of the calculated density values. Choice list: [‘areaUnits’, ‘SquareMiles’]
classification_type
Optional string. Determines how density values will be classified into polygons. Choice list: [‘EqualInterval’, ‘GeometricInterval’, ‘NaturalBreaks’, ‘EqualArea’, ‘StandardDeviation’]
EqualInterval - Polygons are created such that the range of density values is equal for each area.
GeometricInterval - Polygons are based on class intervals that have a geometric series. This method ensures that each class range has approximately the same number of values within each class and that the change between intervals is consistent.
NaturalBreaks - Class intervals for polygons are based on natural groupings of the data. Class break values are identified that best group similar values and that maximize the differences between classes.
EqualArea - Polygons are created such that the size of each area is equal. For example, if the result has more high density values than low density values, more polygons will be created for high densities.
StandardDeviation - Polygons are created based upon the standard deviation of the predicted density values.
num_classes
Optional int. This value is used to divide the range of predicted values into distinct classes. The range of values in each class is determined by the classification_type parameter.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For calculate_density, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. Is true, the number of credits needed to run the operation will be returned as a float.
future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To create a layer that shows density of collisions within 2 miles. The density is classified based upon the standard deviation. The range of density values is divided into 5 classes. collision_density = calculate_density(input_layer=collisions, radius=2, radius_units='Miles', bounding_polygon_layer=zoning_lyr, area_units='SquareMiles', classification_type='StandardDeviation', num_classes=5, output_name='density_of_incidents')
choose_best_facilities
-
arcgis.features.find_locations.choose_best_facilities(goal='Allocate', demand_locations_layer=None, demand=1, demand_field=None, max_travel_range=2147483647, max_travel_range_field=None, max_travel_range_units='Minutes', travel_mode=None, time_of_day=None, time_zone_for_time_of_day='GeoLocal', travel_direction='FacilityToDemand', required_facilities_layer=None, required_facilities_capacity=2147483647, required_facilities_capacity_field=None, candidate_facilities_layer=None, candidate_count=1, candidate_facilities_capacity=2147483647, candidate_facilities_capacity_field=None, percent_demand_coverage=100, output_name=None, context=None, gis=None, estimate=False, point_barrier_layer=None, line_barrier_layer=None, polygon_barrier_layer=None, future=False) 
The
choose_best_facilitiesmethod finds the set of facilities that will best serve demand from surrounding areas.Facilities might be public institutions that offer a service, such as fire stations, schools, or libraries, or they might be commercial ones such as drug stores or distribution centers for a parcel delivery service. Demand represents the need for a service that the facilities can meet. Demand is associated with point locations, with each location representing a given amount of demand.
Parameter
Description
goal
Optional string. Specify the goal that must be satisfied when allocating demand locations to facilities.
Choice list: [‘Allocate’, ‘MinimizeImpedance’, ‘MaximizeCoverage’, ‘MaximizeCapacitatedCoverage’, ‘PercentCoverage’]
Default value is ‘Allocate’.
demand_locations_layer
Required point feature layer. A point layer specifying the locations that have demand for facilities. See Feature Input.
demand
Optional float. The amount of demand available at every demand locations.
The default value is 1.0.
demand_field
Optional string. A numeric field on the
demand_locations_layerrepresenting the amount of demand available at each demand location. If specified, thedemandparameter is ignored.max_travel_range
Optional float. Specify the maximum travel time or distance allowed between a demand location and the facility it is allocated to.
The default is unlimited (2,147,483,647.0).
max_travel_range_field
Optional string. A numeric field on the
demand_locations_layerspecifying the maximum travel time or distance allowed between a demand location and the facility it is allocated to. If specified, themax_travel_rangeparameter is ignored.max_travel_range_units
Optional string. The units for the maximum travel time or distance allowed between a demand location and the facility it is allocated to.
Choice list: [‘Seconds’, ‘Minutes’, ‘Hours’, ‘Days’, ‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’].
The default is ‘Minutes’.
travel_mode
Specify the mode of transportation for the analysis.
Choice list: [‘Driving Distance’, ‘Driving Time’, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
time_of_day
Optional datetime.datetime. Specify whether travel times should consider traffic conditions. To use traffic in the analysis, set travel_mode to a travel mode object whose impedance_attribute_name property is set to travel_time and assign a value to time_of_day. (A travel mode with other impedance_attribute_name values don’t support traffic.) The
time_of_dayvalue represents the time at which travel begins, or departs, from the origin points. The time is specified as datetime.datetime.The service supports two kinds of traffic: ty pical and live. Typical traffic references travel speeds that are made up of historical averages for each five-minute interval spanning a week. Live traffic retrieves speeds from a traffic feed that processes phone probe records, sensors, and other data sources to record actual travel speeds and predict speeds for the near future.
The data coverage page shows the countries Esri currently provides traffic data for.
Typical Traffic:
To ensure the task uses typical traffic in locations where it is available, choose a time and day of the week, and then convert the day of the week to one of the following dates from 1990:
Monday - 1/1/1990
Tuesday - 1/2/1990
Wednesday - 1/3/1990
Thursday - 1/4/1990
Friday - 1/5/1990
Saturday - 1/6/1990
Sunday - 1/7/1990
Set the time and date as datetime.datetime.
For example, to solve for 1:03 p.m. on Thursdays, set the time and date to 1:03 p.m., 4 January 1990; and convert to datetime eg. datetime.datetime(1990, 1, 4, 1, 3).
Live Traffic:
To use live traffic when and where it is available, choose a time and date and convert to datetime.
Esri saves live traffic data for 4 hours and references predictive data extending 4 hours into the future. If the time and date you specify for this parameter is outside the 24-hour time window, or the travel time in the analysis continues past the predictive data window, the task falls back to typical traffic speeds.
Examples: from datetime import datetime
“time_of_day”: datetime(1990, 1, 4, 1, 3) # 13:03, 4 January 1990. Typical traffic on Thursdays at 1:03 p.m.
“time_of_day”: datetime(1990, 1, 7, 17, 0) # 17:00, 7 January 1990. Typical traffic on Sundays at 5:00 p.m.
“time_of_day”: datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. If the current time is between 8:00 p.m., 21 Oct. 2014 and 8:00 p.m., 22 Oct. 2014, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
“time_of_day”: datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015. If the current time is between 10:20 p.m., 17 Mar. 2015 and 10:20 p.m., 18 Mar. 2015, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
time_zone_for_time_of_day
Optional string. Specify the time zone or zones of the time_of_day parameter.
Choice list: [‘GeoLocal’, ‘UTC’]
GeoLocal-refers to the time zone in which the origins_layer points are located.
UTC-refers to Coordinated Universal Time.
travel_direction
Optional string. Specify whether to measure travel times or distances from facilities to demand locations or from demand locations to facilities.
Choice list: [‘FacilityToDemand’, ‘DemandToFacility’]
required_facilities_layer
Optional point feature layer. A point layer specifying one or more locations that act as facilities by providing some kind of service. Facilities specified by this parameter are required to be part of the output solution and will be used before any facilities from the
candidate_facilities_layerwhen allocating demand locations.required_facilities_capacity
Optional float. Specify how much demand every facility in the
required_facilities_layeris capable of supplying.The default value is unlimited (2,147,483,647).
required_facilities_capacity_field
Optional string. A field on the required_facilities_layer representing how much demand each facility in the
required_facilities_layeris capable of supplying. This parameter takes precedence whenrequired_facilities_capacityparameter is also specified.candidate_facilities_layer
Optional point layer. A point layer specifying one or more locations that act as facilities by providing some kind of service. Facilities specified by this parameter are not required to be part of the output solution and will be used only after all the facilities from the
candidate_facilities_layerhave been used when allocating demand locations.candidate_count
Optional integer. The number of candidate facilities to choose when allocating demand locations. Note that the sum of the features in the
required_facilities_capacityand the value specified forcandidate_countcannot exceed 100.The default value is 1.
candidate_facilities_capacity
Optional float. Specify how much demand every facility in the
candidate_facilities_layeris capable of supplying.The default value is unlimited (2,147,483,647.0).
candidate_facilities_capacity_field
Optional string. A field on the
candidate_facilities_layerrepresenting how much demand each facility in thecandidate_facilities_layeris capable of supplying. This parameter takes precedence whencandidate_facilities_capacityparameter is also specified.percent_demand_coverage
Optional float. Specify the percentage of the total demand that you want the chosen and required facilities to capture.
The default value is 100.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For choose_best_facilities, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. Is true, the number of credits needed to run the operation will be returned as a float.
point_barrier_layer
Optional layer. Specify one or more point features that act as temporary restrictions (in other words, barriers) when traveling on the underlying streets.
A point barrier can model a fallen tree, an accident, a downed electrical line, or anything that completely blocks traffic at a specific position along the street. Travel is permitted on the street but not through the barrier. See Feature Input.
line_barrier_layer
Optional layer. Specify one or more line features that prohibit travel anywhere the lines intersect the streets.
A line barrier prohibits travel anywhere the barrier intersects the streets. For example, a parade or protest that blocks traffic across several street segments can be modeled with a line barrier. See Feature Input.
polygon_barrier_layer
Optional layer. Specify one or more polygon features that completely restrict travel on the streets intersected by the polygons.
One use of this type of barrier is to model floods covering areas of the street network and making road travel there impossible. See Feature Input.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
When an output_name is specified, a
FeatureCollectionwith 3 layers is returned (see dictionary below for details), else a dict with the following keys:”allocated_demand_locations_layer” : layer (
FeatureCollection)”allocation_lines_layer” : layer (
FeatureCollection)”assigned_facilities_layer” : layer (
FeatureCollection)
USAGE EXAMPLE: To minimize overall distance travelled for travelling from esri offices to glider airports. best_facility = choose_best_facilities(goal="MinimizeImpedance", demand_locations_layer=esri_offices, travel_mode='Driving Distance', travel_direction="DemandToFacility", required_facilities_layer=gliderport_lyr, candidate_facilities_layer=balloonport_lyr, candidate_count=1, output_name="choose best facilities")
connect_origins_to_destinations
-
arcgis.features.analysis.connect_origins_to_destinations(origins_layer, destinations_layer, measurement_type=None, origins_layer_route_id_field=None, destinations_layer_route_id_field=None, time_of_day=None, time_zone_for_time_of_day='GeoLocal', output_name=None, context=None, gis=None, estimate=False, point_barrier_layer=None, line_barrier_layer=None, polygon_barrier_layer=None, future=False, route_shape='FollowStreets', include_route_layers=False) 
The Connect Origins to Destinations task measures the travel time or distance between pairs of points. Using this tool, you can
Calculate the total distance or time commuters travel on their home-to-work trips.
Measure how far customers are traveling to shop at your stores. Use this information to define your market reach, especially when targeting advertising campaigns or choosing new store locations.
Calculate the expected trip mileage for your fleet of vehicles. Afterward, run the Summarize Within tool to report mileage by state or other region.
You provide starting and ending points, and the tool returns a layer containing route lines, including measurements, between the paired origins and destinations.
Parameter
Description
origins_layer
Required layer. The starting point or points of the routes to be generated. See Feature Input.
destinations_layer
Required layer. The routes end at points in the destinations layer. See Feature Input.
measurement_type
Required string. The origins and destinations can be connected by measuring straight-line distance, or by measuring travel time or travel distance along a street network using various modes of transportation known as travel modes.
Valid values are a string, StraightLine, which indicates Euclidean distance to be used as distance measure or a Python dictionary representing settings for a travel mode.
When using a travel mode for the measurement_type, you need to specify a dictionary containing the settings for a travel mode supported by your organization. The code in the example section below generates a valid Python dictionary and then passes it as the value for the measurement_type parameter.
Supported travel modes: [‘Driving Distance’, ‘Driving Time’, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
origins_layer_route_id_field
Optional string. Specify the field in the origins layer containing the IDs that pair origins with destinations.
The ID values must uniquely identify points in the origins layer
Each ID value must also correspond with exactly one route ID value in the destinations layer. Route IDs that match across the layers create origin-destination pairs, which the tool connects together.
Specifying origins_layer_route_id_field is optional when there is exactly one point feature in the origins or destinations layer. The tool will connect all origins to the one destination or the one origin to all destinations, depending on which layer contains one point.
destinations_layer_route_id_field
Optional string. Specify the field in the destinations layer containing the IDs that pair origins with destinations.
The ID values must uniquely identify points in the destinations layer.
Each ID value must also correspond with exactly one route ID value in the origins layer. Route IDs that match across the layers create origin-destination pairs, which the tool connects together.
Specifying destinations_layer_route_id_field is optional when there is exactly one point feature in the origins or destinations layer. The tool will connect all origins to the one destination or the one origin to all destinations, depending on which layer contains one point.
time_of_day
Optional datetime.datetime. Specify whether travel times should consider traffic conditions. To use traffic in the analysis, set measurement_type to a travel mode object whose impedance_attribute_name property is set to travel_time and assign a value to time_of_day. (A travel mode with other impedance_attribute_name values don’t support traffic.) The time_of_day value represents the time at which travel begins, or departs, from the origin points. The time is specified as datetime.datetime.
The service supports two kinds of traffic: typical and live. Typical traffic references travel speeds that are made up of historical averages for each five-minute interval spanning a week. Live traffic retrieves speeds from a traffic feed that processes phone probe records, sensors, and other data sources to record actual travel speeds and predict speeds for the near future.
The data coverage page shows the countries Esri currently provides traffic data for.
Typical Traffic:
To ensure the task uses typical traffic in locations where it is available, choose a time and day of the week, and then convert the day of the week to one of the following dates from 1990:
Monday - 1/1/1990
Tuesday - 1/2/1990
Wednesday - 1/3/1990
Thursday - 1/4/1990
Friday - 1/5/1990
Saturday - 1/6/1990
Sunday - 1/7/1990
Set the time and date as datetime.datetime.
For example, to solve for 1:03 p.m. on Thursdays, set the time and date to 1:03 p.m., 4 January 1990; and convert to datetime eg. datetime.datetime(1990, 1, 4, 1, 3).
Live Traffic:
To use live traffic when and where it is available, choose a time and date and convert to datetime.
Esri saves live traffic data for 4 hours and references predictive data extending 4 hours into the future. If the time and date you specify for this parameter is outside the 24-hour time window, or the travel time in the analysis continues past the predictive data window, the task falls back to typical traffic speeds.
# Examples: from datetime import datetime
“time_of_day”: datetime(1990, 1, 4, 1, 3) # 13:03, 4 January 1990. Typical traffic on Thursdays at 1:03 p.m.
“time_of_day”: datetime(1990, 1, 7, 17, 0) # 17:00, 7 January 1990. Typical traffic on Sundays at 5:00 p.m.
“time_of_day”: datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. If the current time is between 8:00 p.m., 21 Oct. 2014 and 8:00 p.m., 22 Oct. 2014, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
“time_of_day”: datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015. If the current time is between 10:20 p.m., 17 Mar. 2015 and 10:20 p.m., 18 Mar. 2015, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
time_zone_for_time_of_day
Optional string. Specify the time zone or zones of the timeOfDay parameter. Choice list: [‘GeoLocal’, ‘UTC’]
GeoLocal-refers to the time zone in which the originsLayer points are located.
UTC-refers to Coordinated Universal Time.
include_route_layers
Optional Boolean. When include_route_layers is set to True, each route from the result is also saved as a route layer item. A route layer includes all the information for a particular route such as the stops assigned to the route as well as the travel directions. Creating route layers is useful if you want to share individual routes with other members in your organization. The route layers use the output feature service name provided in the
output_nameparameter as a prefix and the route name generated as part of the analysis is added to create a unique name for each route layer.Caution: Route layers cannot be created when the output is a feature collection. The task will raise an error if output_name is not specified (which indicates feature collection output) and include_route_layers is True.
The maximum number of route layers that can be created is 1,000. If the result contains more than 1,000 routes and include_route_layers is True, the task will only create the output feature service.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For connect_origins_to_destinations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. Is True, the number of credits needed to run the operation will be returned as a float.
point_barrier_layer
Optional layer. Specify one or more point features that act as temporary restrictions (in other words, barriers) when traveling on the underlying streets.
A point barrier can model a fallen tree, an accident, a downed electrical line, or anything that completely blocks traffic at a specific position along the street. Travel is permitted on the street but not through the barrier. See Feature Input.
line_barrier_layer
Optional layer. Specify one or more line features that prohibit travel anywhere the lines intersect the streets.
A line barrier prohibits travel anywhere the barrier intersects the streets. For example, a parade or protest that blocks traffic across several street segments can be modeled with a line barrier. See Feature Input.
polygon_barrier_layer
Optional string. Specify one or more polygon features that completely restrict travel on the streets intersected by the polygons.
One use of this type of barrier is to model floods covering areas of the street network and making road travel there impossible. See Feature Input.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
route_shape
Optional String. Specify the shape of the route that connects each origin to it’s destination when using a travel mode.
Values: FollowStreets or StraightLine
Default: FollowStreets
FollowStreets - The shape is based on the underlying street network. This option is best when you want to generate the routes between origins and destinations. This is the default value when using a travel mode.
StraightLine - The shape is a straight line connecting the origin-destination pair. This option is best when you want to g enerate spider diagrams or desire lines (for example, to show which stores customers are visiting). This is the default value when not using a travel mode.
The best route between an origin and it’s matched destination is always calculated based on the travel mode, regardless of which route shape is chosen.
- Returns
A dictionary with the following keys:
”routes_layer” : layer (
FeatureCollection)”unassigned_origins_layer” : layer (
FeatureCollection)”unassigned_destinations_layer” : layer (
FeatureCollection)
# USAGE EXAMPLE: To retrieve trvel modes and run connect_origins_to_destinations tool. This example creates route between esri regional offices to esri headquarter. routes = connect_origins_to_destinations(origins_layer=esri_regional, destinations_layer=dest_layer, measurement_type='Rural Driving Distance', time_of_day=datetime(1990, 1, 4, 1, 3), output_name="routes_from_offices_to_hq")
create_buffers
-
arcgis.features.analysis.create_buffers(input_layer, distances=[], field=None, units='Meters', dissolve_type='None', ring_type='Disks', side_type='Full', end_type='Round', output_name=None, context=None, gis=None, estimate=False, future=False) 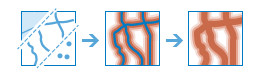
The
create_bufferstask creates polygons that cover a given distance from a point, line, or polygon feature. Buffers are typically used to create areas that can be further analyzed using a tool such asoverlay_layers. For example, if the question is “What buildings are within one mile of the school?”, the answer can be found by creating a one-mile buffer around the school and overlaying the buffer with the layer containing building footprints. The end result is a layer of those buildings within one mile of the school.Parameter
Description
input_layer
Required point, line or polygon feature layer. The input features to be buffered. See Feature Input.
distances
Optional list of floats to buffer the input features. The distance(s) that will be buffered. You must supply values for either the
distancesorfieldparameter. You can enter a single distance value or multiple values. The units of the distance values is suppied by the units parameter.field
Optional string. A field on the
input_layercontaining a buffer distance. Buffers will be created using field values. Unlike thedistancesparameter, multiple distances are not supported on field input.units
Optional string. The linear unit to be used with the distance value(s) specified in distances or contained in the field value.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘NauticalMiles’, ‘Yards’]
The default is ‘Meters’.
dissolve_type
Optional string. Determines how overlapping buffers are processed.
Choice list: [‘None’, ‘Dissolve’]

None-Overlapping areas are kept. This is the default.
Dissolve-Overlapping areas are combined.ring_type
Optional string. Determines how multiple-distance buffers are processed.
Choice list: [‘Disks’, ‘Rings’]

Disks-buffers are concentric and will overlap. For example, if your distances are 10 and 14, the result will be two buffers, one from 0 to 10 and one from 0 to 14. This is the default.
Ringsbuffers will not overlap. For example, if your distances are 10 and 14, the result will be two buffers, one from 0 to 10 and one from 10 to 14.side_type
Optional string. When buffering line features, you can choose which side of the line to buffer.
Typically, you choose both sides (Full, which is the default). Left and right are determined as if you were walking from the first x,y coordinate of the line (the start coordinate) to the last x,y coordinate of the line (the end coordinate). Choosing left or right usually means you know that your line features were created and stored in a particular direction (for example, upstream or downstream in a river network).
When buffering polygon features, you can choose whether the buffer includes or excludes the polygon being buffered.
Choice list: [‘Full’, ‘Left’, ‘Right’, ‘Outside’]

Full-both sides of the line will be buffered. This is the default for line featuress.
Left-only the right side of the line will be buffered.
Right-only the right side of the line will be buffered.
Outsidewhen buffering a polygon, the polygon being buffered is excluded in the result buffer.
If
side_typenot supplied, the polygon being buffered is included in the result buffer. This is the default for polygon features.end_type
Optional string. The shape of the buffer at the end of line input features. This parameter is not valid for polygon input features. At the ends of lines the buffer can be rounded (Round) or be straight across (Flat).
Choice list: [‘Round’, ‘Flat’]

Round-buffers will be rounded at the ends of lines. This is the default.
Flat-buffers will be flat at the ends of lines.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For create_buffers, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.
USAGE EXAMPLE: To create 5 mile buffer around US parks, within the specified extent. polygon_lyr_buffer = create_buffers(input_layer=parks_lyr, distances=[5], units='Miles', ring_type='Rings', end_type='Flat', output_name='create_buffers', context={"extent":{"xmin":-12555831.656684224,"ymin":5698027.566358956,"xmax":-11835489.102124758,"ymax":6104672.556836072,"spatialReference":{"wkid":102100,"latestWkid":3857}}})
create_drive_time_areas
-
arcgis.features.analysis.create_drive_time_areas(input_layer, break_values=[5, 10, 15], break_units='Minutes', travel_mode=None, overlap_policy='Overlap', time_of_day=None, time_zone_for_time_of_day='GeoLocal', output_name=None, context=None, gis=None, estimate=False, point_barrier_layer=None, line_barrier_layer=None, polygon_barrier_layer=None, future=False, travel_direction='AwayFromFacility', show_holes=False, include_reachable_streets=False) 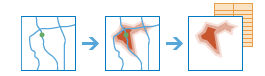
The
create_drive_time_areasmethod creates areas that can be reached within a given drive time or drive distance. It can help you answer questions such as:How far can I drive from here in five minutes?
What areas are covered within a three-mile drive distance of my stores?
What areas are within four minutes of our fire stations?
See Create Drive-Time Areas for details on the Spatial Analysis Service that runs this task.
Parameter
Description
input_layer
Required point feature layer. The points around which travel areas based on a mode of transportation will be drawn. See Feature Input.
travel_mode
Optional string or dict. Specify the mode of transportation for the analysis.
Choice list: [‘Driving Distance’, ‘Driving Time’, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
The default is ‘Driving Time’.
break_values
Optional list of floats. The size of the polygons to create. The units for break_values is specified with the break_units parameter.
By setting many unique values in the list, polygons of different sizes are generated around each input location.
The default is [5, 10, 15].
break_units
Optional string. The units of the break_values parameter.
To create areas showing how far you can go along roads or walkways within a given time, specify a time unit. Alternatively, specify a distance unit to generate areas bounded by a maximum travel distance.
When the travel_mode is time based, a time unit should be specified for the break_units. When the travel_mode is distance based, a distance unit should be specified for the break_units.
Choice list: [‘Seconds’, ‘Minutes’, Hours’, ‘Feet’, ‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Minutes’.
overlap_policy
Optional string. Determines how overlapping areas are processed.
Choice list: [‘Overlap’, ‘Dissolve’, ‘Split’]

Overlap-Overlapping areas are kept. This is the default.Dissolve-Overlapping areas are combined by break value. Because the areas are dissolved, use this option when you need to know the areas that can be reached within a given time or distance, but you don’t need to know which input points are nearest.
Split-Overlapping areas are split in the middle. Use this option when you need to know the one nearest input location to the covered area.The default is ‘Overlap’
time_of_day
Optional datetime.datetime. Specify whether travel times should consider traffic conditions. To use traffic in the analysis, set measurement_type to a travel mode object whose impedance_attribute_name property is set to travel_time and assign a value to time_of_day. (A travel mode with other impedance_attribute_name values don’t support traffic.) The time_of_day value represents the time at which travel begins, or departs, from the origin points. The time is specified as datetime.datetime.
The service supports two kinds of traffic: typical and live. Typical traffic references travel speeds that are made up of historical averages for each five-minute interval spanning a week. Live traffic retrieves speeds from a traffic feed that processes phone probe records, sensors, and other data sources to record actual travel speeds and predict speeds for the near future.
The data coverage page shows the countries Esri currently provides traffic data for.
Typical Traffic:
To ensure the task uses typical traffic in locations where it is available, choose a time and day of the week, and then convert the day of the week to one of the following dates from 1990:
Monday - 1/1/1990
Tuesday - 1/2/1990
Wednesday - 1/3/1990
Thursday - 1/4/1990
Friday - 1/5/1990
Saturday - 1/6/1990
Sunday - 1/7/1990
Set the time and date as datetime.datetime.
For example, to solve for 1:03 p.m. on Thursdays, set the time and date to 1:03 p.m., 4 January 1990; and convert to datetime eg. datetime.datetime(1990, 1, 4, 1, 3).
Live Traffic:
To use live traffic when and where it is available, choose a time and date and convert to datetime.
Esri saves live traffic data for 4 hours and references predictive data extending 4 hours into the future. If the time and date you specify for this parameter is outside the 24-hour time window, or the travel time in the analysis continues past the predictive data window, the task falls back to typical traffic speeds.
Examples: from datetime import datetime
“time_of_day”: datetime(1990, 1, 4, 1, 3) # 13:03, 4 January 1990. Typical traffic on Thursdays at 1:03 p.m.
“time_of_day”: datetime(1990, 1, 7, 17, 0) # 17:00, 7 January 1990. Typical traffic on Sundays at 5:00 p.m.
“time_of_day”: datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. If the current time is between 8:00 p.m., 21 Oct. 2014 and 8:00 p.m., 22 Oct. 2014, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
“time_of_day”: datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015. If the current time is between 10:20 p.m., 17 Mar. 2015 and 10:20 p.m., 18 Mar. 2015, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
time_zone_for_time_of_day
Optional string. Specify the time zone or zones of the time_of_day parameter.
Choice list: [‘GeoLocal’, ‘UTC’]
GeoLocal-refers to the time zone in which the originsLayer points are located.
UTC-refers to Coordinated Universal Time.
The default is ‘GeoLocal’.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For create_drive_time_areas, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
point_barrier_layer
Optional layer. Specify one or more point features that act as temporary restrictions (in other words, barriers) when traveling on the underlying streets.
A point barrier can model a fallen tree, an accident, a downed electrical line, or anything that completely blocks traffic at a specific position along the street. Travel is permitted on the street but not through the barrier. See Feature Input.
line_barrier_layer
Optional layer. Specify one or more line features that prohibit travel anywhere the lines intersect the streets.
A line barrier prohibits travel anywhere the barrier intersects the streets. For example, a parade or protest that blocks traffic across several street segments can be modeled with a line barrier. See Feature Input.
polygon_barrier_layer
Optional string. Specify one or more polygon features that completely restrict travel on the streets intersected by the polygons.
One use of this type of barrier is to model floods covering areas of the street network and making road travel there impossible. See Feature Input.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
travel_direction
Optiona String. Specify whether the direction of travel used to generate the travel areas is toward or away from the input locations.
Values: AwayFromFacility or TowardsFacility
The travel direction can influence how the areas are generated. CreateDriveTimeAreas will obey one-way streets, avoid illegal turns, and follow other rules based on the direction of travel. You should select the direction of travel based on the type of input locations and the context of your analysis. For example, the drive-time area for a pizza delivery store should be created away from the facility, whereas the drive-time area for a hospital should be created toward the facility.
show_holes
Optional boolean. When set to true, the output areas will include holes if some streets couldn’t be reached without exceeding the cutoff or due to travel restrictions imposed by the travel mode.
include_reachable_streets
Optional string. Only applicable if
output_nameis specified. When True (andoutput_nameis specified), a second layer named Reachable Streets is created in the outputFeature Layer.This layer contains the streets that were used to define the drive time area polygons. Set this to true if you want a potentially more accurate result of which streets are actually covered within a specific travel distance than what the drive-time areas would contain.
- Returns
result_layer :
FeatureLayerif output_name is specified, else Feature Collection.
USAGE EXAMPLE: To create drive time areas around USA airports, within the specified extent. target_area4 = create_drive_time_areas(airport_lyr, break_values=[2, 4], break_units='Hours', travel_mode='Trucking Time', overlap_policy='Split', time_of_day=datetime(2019, 5, 13, 7, 52), output_name='create_drive_time_areas', context={"extent":{"xmin":-11134400.655784884,"ymin":3368261.7800108367,"xmax":-10682810.692676282,"ymax":3630899.409198575,"spatialReference":{"wkid":102100,"latestWkid":3857}}})
create_route_layers
-
arcgis.features.analysis.create_route_layers(route_data_item, delete_route_data_item=False, tags=None, summary=None, route_name_prefix=None, folder_name=None, gis=None, estimate=False, future=False) The
create_route_layersmethod creates route layer items on the portal from the input route data.A route layer includes all the information for a particular route such as the stops assigned to the route as well as the travel directions. Creating route layers is useful if you want to share individual routes with other members in your organization.
Parameter
Description
route_data
Required item. The item id for the route data item that is used to create route layer items. Before running this task, the route data must be added to your portal as an item.
delete_route_data_item
Required boolean. Indicates if the input route data item should be deleted. You may want to delete the route data in case it is no longer required after the route layers have been created from it.
When
delete_route_data_itemis set to true and the task fails to delete the route data item, it will return a warning message but still continue execution.The default value is False.
tags
Optional string. Tags used to describe and identify the route layer items. Individual tags are separated using a comma. The route name is always added as a tag even when a value for this argument is not specified.
summary
Optional string. The summary displayed as part of the item information for the route layer item. If a value for this argument is not specified, a default summary text “Route and directions for <Route Name>” is used.
route_name_prefix
Optional string. A qualifier added to the title of every route layer item. This can be used to designate all routes that are shared for a specific purpose to have the same prefix in the title. The name of the route is always appended after this qualifier. If a value for the route_name_prefix is not specified, the title for the route layer item is created using only the route name.
folder_name
Optional string. The folder within your personal online workspace (My Content in your ArcGIS Online or Portal for ArcGIS organization) where the route layer items will be created. If a folder with the specified name does not exist, a new folder will be created. If a folder with the specified name exists, the items will be created in the existing folder. If a value for folder_name is not specified, the route layer items are created in the root folder of your online workspace.
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer : A list (items) or an
Item.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To create route layers from geodatabase item. route = create_route_layers(route_data_item=route_item, delete_route_data_item=False, tags="datascience", summary="example of create route layers method", route_name_prefix="santa_ana", folder_name="create route layers")
create_viewshed
-
arcgis.features.analysis.create_viewshed(input_layer, dem_resolution='Finest', maximum_distance=None, max_distance_units='Meters', observer_height=None, observer_height_units='Meters', target_height=None, target_height_units='Meters', generalize=True, output_name=None, context=None, gis=None, estimate=False, future=False) 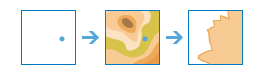
The create_viewshed method identifies visible areas based on the observer locations you provide. The results are areas where the observers can see the observed objects (and the observed objects can see the observers).
Parameter
Description
input_layer
Required point feature layer. The features to use as the observer locations. See Feature Input.
dem_resolution
Optional string. The approximate spatial resolution (cell size) of the source elevation data used for the calculation.
The resolution values are an approximation of the spatial resolution of the digital elevation model. While many elevation sources are distributed in units of arc seconds, the keyword is an approximation of those resolutions in meters for easier understanding.
Choice list: [‘FINEST’, ‘10m’, ‘24m’, ‘30m’, ‘90m’]
The default is the finest resolution available.
maximum_distance
Optional float. This is a cutoff distance where the computation of visible areas stops. Beyond this distance, it is unknown whether the analysis points and the other objects can see each other.
It is useful for modeling current weather conditions or a given time of day, such as dusk. Large values increase computation time.
Unless specified, a default maximum distance will be computed based on the resolution and extent of the source DEM. The allowed maximum value is 50 kilometers. Use max_distance_units to set the units for maximum_distance.
max_distance_units
Optional string. The units for the maximum_distance parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Meters’.
observer_height
Optional float. This is the height above the ground of the observer locations.
The default is 1.75 meters, which is approximately the average height of a person. If you are looking from an elevated location, such as an observation tower or a tall building, use that height instead.
Use observer_height_units to set the units for observer_height.
observer_height_units
Optional string. The units for the observer_height parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Meters’.
target_height
Optional float. This is the height of structures or people on the ground used to establish visibility. The result viewshed are those areas where an input point can see these other objects. The converse is also true; the other objects can see an input point.
If your input points represent wind turbines and you want to determine where people standing on the ground can see the turbines, enter the average height of a person (approximately 6 feet). The result is those areas where a person standing on the ground can see the wind turbines.
If your input points represent fire lookout towers and you want to determine which lookout towers can see a smoke plume 20 feet high or higher, enter 20 feet for the height. The result is those areas where a fire lookout tower can see a smoke plume at least 20 feet high.
If your input points represent scenic overlooks along roads and trails and you want to determine where wind turbines 400 feet high or higher can be seen, enter 400 feet for the height. The result is those areas where a person standing at a scenic overlook can see a wind turbine at least 400 feet high.
If your input points represent scenic overlooks and you want to determine how much area on the ground people standing at the overlook can see, enter zero. The result is those areas that can be seen from the scenic overlook.
Use target_height_units to set the units for target_height.
target_height_units
Optional string. The units for the target_height parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
The default is ‘Meters’.
generalize
Optional boolean. Determines whether or not the viewshed polygons are to be generalized.
The viewshed calculation is based on a raster elevation model that creates a result with stair-stepped edges. To create a more pleasing appearance and improve performance, the default behavior is to generalize the polygons. The generalization process smooths the boundary of the visible areas and may remove some single-cell visible areas.
The default value is True.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For create_viewshed, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.
USAGE EXAMPLE: To create viewshed around esri headquarter office. viewshed3 = create_viewshed(hq_lyr, maximum_distance=9, max_distance_units='Miles', target_height=6, target_height_units='Feet', output_name="create Viewshed")
create_watersheds
-
arcgis.features.analysis.create_watersheds(input_layer, search_distance=None, search_units='Meters', source_database='FINEST', generalize=True, output_name=None, context=None, gis=None, estimate=False, future=False) 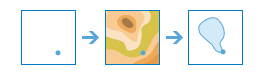
The
create_watershedsmethod determines the watershed, or upstream contributing area, for each point in your analysis layer. For example, suppose you have point features representing locations of waterborne contamination, and you want to find the likely sources of the contamination. Since the source of the contamination must be somewhere within the watershed upstream of the point, you would use this tool to define the watersheds containing the sources of the contaminant.Parameter
Description
input_layer
Required point feature layer. The point features used for calculating watersheds. These are referred to as pour points, because it is the location at which water pours out of the watershed. See Feature Input.
search_distance
Optional float. The maximum distance to move the location of an input point. Use search_units to set the units for search_distance.
If your input points are located away from a drainage line, the resulting watersheds are likely to be very small and not of much use in determining the upstream source of contamination. In most cases, you want your input points to snap to the nearest drainage line in order to find the watersheds that flows to a point located on the drainage line. To find the closest drainage line, specify a search distance. If you do not specify a search distance, the tool will compute and use a conservative search distance.
To use the exact location of your input point, specify a search distance of zero.
For analysis purposes, drainage lines have been precomputed by Esri using standard hydrologic models. If there is no drainage line within the search distance, the location containing the highest flow accumulation within the search distance is used.
search_units
Optional string. The linear units specified for the search distance.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Miles’, ‘Yards’]
source_database
Optional string. Keyword indicating the data source resolution that will be used in the analysis.
Choice list: [‘Finest’, ‘30m’, ‘90m’]
Finest (Default): Finest resolution available at each location from all possible data sources.
30m: The hydrologic source was built from 1 arc second - approximately 30 meter resolution, elevation data.
90m: The hydrologic source was built from 3 arc second - approximately 90 meter resolution, elevation data.
generalize
Optional boolean. Determines if the output watersheds will be smoothed into simpler shapes or conform to the cell edges of the original DEM.
True: The polygons will be smoothed into simpler shapes. This is the default.
False: The edge of the polygons will conform to the edges of the original DEM.
The default value is True.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For create_watersheds, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
:returns result_layer :
FeatureLayerif output_name is specified, elseFeatureCollection.USAGE EXAMPLE: To create watersheds for Chennai lakes. lakes_watershed = create_watersheds(lakes_lyr, search_distance=3, search_units='Kilometers', source_database='90m', output_name='create watersheds')
derive_new_locations
-
arcgis.features.analysis.derive_new_locations(input_layers=[], expressions=[], output_name=None, context=None, gis=None, estimate=False, future=False) 
The
derive_new_locationsmethod derives new features from the input layers that meet a query you specify. A query is made up of one or more expressions. There are two types of expressions: attribute and spatial. An example of an attribute expression is that a parcel must be vacant, which is an attribute of the Parcels layer (STATUS = ‘VACANT’). An example of a spatial expression is that the parcel must also be within a certain distance of a river (Parcels within a distance of 0.75 Miles from Rivers).The
derive_new_locationsmethod is very similar to thefind_existing_locationsmethod, the main difference is that the result ofderive_new_locationscan contain partial features.In both methods, the attribute expression
whereand the spatial relationshipswithinandcontainsreturn the same result. This is because these relationships return entire features.When
intersectsorwithin_distanceis used,derive_new_locationscreates new features in the result. For example, when intersecting a parcel feature and a flood zone area that partially overlap each other,find_existing_locationswill return the entire parcel whereasderive_new_locationswill return just the portion of the parcel that is within the flood zone.
Parameter
Description
input_layers
Required list of feature layers. A list of layers that will be used in the expressions parameter. Each layer in the list can be:
a feature service layer with an optional filter to select specific features, or
a feature collection
expressions
Required dict. There are two types of expressions, attribute and spatial.
Example attribute expression:
{“operator”: “and”,“layer”: 0,“where”: “STATUS = ‘VACANT’”}Note
operator can be either
andororlayer is the index of the layer in the
input_layersparameter.The where clause must be surrounded by double quotes.
When dealing with text fields, values must be single-quoted (‘VACANT’).
Date fields support all queries except LIKE. Dates are strings in YYYY:MM:DD hh:mm:ss format. Here’s an example using the date field ObsDate:
“where”: “ObsDate >= ‘1998-04-30 13:30:00’ “
=
Equal
>
Greater than
<
Less than
>=
Greater than or equal to
<=
Less than or equal to
<>
Not equal
LIKE ‘% <string>’
A percent symbol (%) signifies a wildcard, meaning that anything is acceptable in its place-one character, a hundred characters, or no character. This expression would select Mississippi and Missouri among USA state names: STATE_NAME LIKE ‘Miss%’
BETWEEN <value1> AND <value2>
Selects a record if it has a value greater than or equal to <value1> and less than or equal to <value2>. For example, this expression selects all records with an HHSIZE value greater than or equal to 3 and less than or equal to 10:
HHSIZE BETWEEN 3 AND 10
The above is equivalent to:
HHSIZE >= 3 AND HHSIZE <= 10 This operator applies to numeric or date fields. Here is an example of a date query on the field ObsDate:
ObsDate BETWEEN ‘1998-04-30 00:00:00’ AND ‘1998-04-30 23:59:59’
Time is optional.
NOT BETWEEN <value1> AND <value2>
Selects a record if it has a value outside the range between <value1> and less than or equal to <value2>. For example, this expression selects all records whose HHSIZE value is less than 5 and greater than 7.
HHSIZE NOT BETWEEN 5 AND 7
The above is equivalent to:
HHSIZE < 5 OR HHSIZE > 7 This operator applies to numeric or date fields.
You can use the contains relationship with points and lines. For example, you have a layer of street centerlines (lines) and a layer of manhole covers (points), and you want to find streets that contain a manhole cover. You could use contains to find streets that contain manhole covers, but in order for a line to contain a point, the point must be exactly on the line (that is, in GIS terms, they are snapped to each other). If there is any doubt about this, use the withinDistance relationship with a suitable distance value.
Example spatial expression:
{“operator”: “and”,“layer”: 0,“spatialRel”: “withinDistance”,“selectingLayer”: 1,“distance”: 10,“units”: “miles”}operator can be either
andororlayer is the index of the layer in
the input_layersparameter. The result of the expression is features in this layer.spatialRel is the spatial relationship. There are nine spatial relationships.
distance is the distance to use for the
withinDistanceandnotWithinDistancespatial relationship.units is the units for distance. Units choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’]
spatialRel
Description
intersects
notIntersects

A feature in layer passes the intersect test if it overlaps any part of a feature in selectingLayer, including touches (where features share a common point).
intersects - If a feature in layer intersects a feature in selectingLayer, the portion of the feature in layer that intersects the feature in selectingLayer is included in the output.
notintersects - If a feature in layer intersects a feature in selectingLayer, the portion of the feature in layer that intersects the feature in selectingLayer is excluded from the output.
withinDistance
notWithinDistance
The within a distance relationship uses the straight-line distance between features in layer to those in selectingLayer.
withinDistance - The portion of the feature in layer that is
within the specified distance of a feature in selectingLayer is included in the output. * notwithinDistance - The portion of the feature in layer that is within the specified distance of a feature in selectingLayer is excluded from output. You can think of this relationship as “is farther away than”.
contains
notContains

A feature in layer passes this test if it completely surrounds a feature in selectingLayer. No portion of the containing feature an be outside the containing feature; however, the contained feature is allowed to touch the containing feature (that is, share a common point along its boundary).
contains - If a feature in layer contains a feature in
selectingLayer, the feature in layer is included in the output. * notcontains - If a feature in layer contains a feature in selectingLayer, the feature in the first layer is excluded.
within
notWithin

A feature in layer passes this test if it is completely surrounded by a feature in selectingLayer. The entire feature layer must be within the containing feature; however, the two features are allowed to touch (that is, share a common point along its boundary).
within - If a feature in layer is completely within a feature in selectingLayer, the feature in layer is included in the output.
notwithin - If a feature in layer is completely within a feature in selectingLayer, the feature in layer is excluded from the output.
Note: You can use the within relationship for points and lines, just as you can with the contains relationship. For example, your first layer contains points representing manhole covers and you want to find the manholes that are on street centerlines (as opposed to parking lots or other non-street features). You could use within to find manhole points within street centerlines, but in order for a point to contain a line, the point must be exactly on the line (that is, in GIS terms, they are snapped to each other). If there is any doubt about this, use the withinDistance relationship with a suitable distance value.
| relationship with a suitable distance value. |An expression may be a list, which denotes a group. The first operator in the group indicates how the group expression is added to the previous expression. Grouping expressions is only necessary when you need to create two or more distinct sets of features from the same layer. One way to think of grouping is that without grouping, you would have to execute
derive_new_locationsmultiple times and merge the results.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For derive_new_locations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits needed to run the operation will be returned as a float.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is specified, elseFeatureCollection.
USAGE EXAMPLE: To identify areas that are suitable cougar habitat using the criteria defined by experts. new_location = derive_new_locations(input_layers=[slope, vegetation, streams, highways], expressions=[{"operator":"","layer":0,"selectingLayer":1,"spatialRel":"intersects"}, {"operator":"and","layer":0,"selectingLayer":2,"spatialRel":"withinDistance","distance":500,"units":"Feet"}, {"operator":"and","layer":0,"selectingLayer":3,"spatialRel":"notWithinDistance","distance":1500,"units":"Feet"}, {"operator":"and","layer":0,"where":"GRIDCODE = 1"}], output_name='derive_new_locations')
dissolve_boundaries
-
arcgis.features.analysis.dissolve_boundaries(input_layer, dissolve_fields=[], summary_fields=[], output_name=None, context=None, gis=None, estimate=False, multi_part_features=True, future=False) 
The dissolve_boundaries method finds polygons that overlap or share a common boundary and merges them together to form a single polygon.
You can control which boundaries are merged by specifying a field. For example, if you have a layer of counties, and each county has a State_Name attribute, you can dissolve boundaries using the State_Name attribute. Adjacent counties will be merged together if they have the same value for State_Name. The end result is a layer of state boundaries.
Parameter
Description
input_layer
Required layer. The layer containing polygon features that will be dissolved. See Feature Input.
dissolve_fields
Optional list of strings. One or more fields on the input_layer that control which polygons are merged. If you don’t supply dissolve_fields , or you supply an empty list of fields, polygons that share a common border (that is, they are adjacent) or polygon areas that overlap will be dissolved into one polygon.
If you do supply values for the dissolve_fields parameter, polygons that share a common border and contain the same value in one or more fields will be dissolved. For example, if you have a layer of counties, and each county has a State_Name attribute, you can dissolve boundaries using the State_Name attribute. Adjacent counties will be merged together if they have the same value for State_Name. The end result is a layer of state boundaries.If two or more fields are specified, the values in these fields must be the same for the boundary to be dissolved.
summary_fields
Optional list of strings. A list of field names and statistical summary types that you wish to calculate from the polygons that are dissolved together:
[“fieldName summaryType”, “fieldName2 summaryType”]
fieldName is the name of one of the numeric fields found in the input_layer. summary type is one of the following:
Sum- Adds the total value of all the points in each polygonMean- Calculates the average of all the points in each polygon.Min- Finds the smallest value of all the points in each polygon.Max- Finds the largest value of all the points in each polygon.Stddev- Finds the standard deviation of all the points in each polygon.
For example, if you are dissolving counties based on State_Name, and each county has a Population field, you can sum the Population for all the counties sharing the same State_Name attribute. The result would be a layer of state boundaries with total population.
# Usage Example >>> dissolve_boundaries(input_layer="US_Counties", dissolve_fields="State_Name", summary_fields=["Population Sum"], output_name="US_States")
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For calculate_density, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 11+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. If True, the number of credits to run the operation will be returned.
multi_part_features
Optional boolean. Specifies whether multipart features (i.e. features which share a common attribute table but are not visibly connected) are allowed in the output feature class.
Choice list: [
True,False]True: Specifies multipart features are allowed.False: Specifies multipart features are not allowed. Instead of creating multipart features, individual features will be created for each part.
The default value is
True.future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeature Collection. Iffuture = True, then the result is aFutureobject. Callresult()to get the response.
USAGE EXAMPLE: To dissolve boundaries of polygons with same state name. The dissolved polygons are summarized using population as summary field and standard deviation as summary type. diss_counties = dissolve_boundaries(input_layer=usa_counties, dissolve_fields=["STATE_NAME"], summary_fields=["POPULATION Stddev"], output_name="DissolveBoundaries")
enrich_layer
-
arcgis.features.analysis.enrich_layer(input_layer, data_collections=[], analysis_variables=[], country=None, buffer_type=None, distance=None, units=None, output_name=None, context=None, gis=None, estimate=False, return_boundaries=False, future=False) 
The
enrich_layermethod enriches your data by getting facts about the people, places, and businesses that surround your data locations. For example: What kind of people live here? What do people like to do in this area? What are their habits and lifestyles? What kind of businesses are there in this area?The result will be a new layer of input features that includes all demographic and geographic information from given data collections.
Parameter
Description
input_layer
Required layer. The features to enrich with new data. See Feature Input.
data_collections
Optional list of strings. This optional parameter defines the collections of data you want to use to enrich your features. Its value is a list of strings. If you don’t provide this parameter, you must provide the analysis_variables parameter.
For more information about data collections and the values for this parameter, visit the Esri Demographics site.
analysis_variables
Optional list of strings. The parameter defines the specific variables within a data collection you want to use to your features. Its value is a list of strings in the form of “dataCollection.VariableName”. If you don’t provide this parameter, you must provide the dataCollections parameter. You can provide both parameters. For example, if you want all variables in the KeyGlobalFacts data collection, specify it in the dataCollections parameter and use this parameter for specific variables in other collections.
For more information about variables in data collections, visit the Esri Demographics site. Each data collection has a PDF file describing variables and their names.
country
Optional string. This optional parameter further defines what is returned from data collection. For example, your input features may be countries in Western Europe, and you want to enrich them with the KeyWEFacts data collection. However, you only want data for France, not every country in your input layer. The value is the two-character country code.
For more information about data collections and the values for this parameter, visit the Esri Demographics site.
buffer_type (Required if input_layer contains point or line features)
Optional string. If your input features are points or lines, you must define an area around your features that you want to enrich. Features that are within (or equal to) the distances you enter will be enriched.
Choice list: [‘StraightLine’, ‘Driving Distance’, ‘Driving Time ‘, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
distance (Required if input_layer contains point or line features)
Optional float. A value that defines the search distance or time. The units of the distance value is supplied by the units parameter.
units
Optional string. The linear unit to be used with the distance value(s) specified in the distance parameter.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’, ‘Seconds’, ‘Minutes’. ‘Hours’]
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For enrich_layer, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 11+
# Example Usage "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.return_boundaries
Optional boolean. Applies only for point and line input features. If True, a result layer of areas is returned. The returned areas are defined by the specified buffer_type. For example, if using a buffer_type of StraightLine with a distance of 5 miles, your result will contain areas with a 5 mile radius around the input features and requested analysis_variables variables. If False, the resulting layer will return the same features as the input layer with analysis_variables variables.
The default value is False.
future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
:returns
FeatureLayerif output_name is specified, elseFeatureCollection. Iffuture = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To enrich US block groups with population as analysis variable. blkgrp_enrich = enrich_layer(block_groups, analysis_variables=["AtRisk.MP27002A_B"], country='US', output_name='enrich layer')
extract_data
-
arcgis.features.analysis.extract_data(input_layers, extent=None, clip=False, data_format=None, output_name=None, gis=None, estimate=False, future=False, context=None) 
The
extract_datamethod is used to extract data from one or more layers within a given extent. The extracted data format can be a file geodatabase, shapefiles, csv, or kml. File geodatabases and shapefiles are added to a zip file that can be downloaded.Parameter
Description
input_layers
Required list of feature layers and tables. A list of input layers to be extracted. See Feature Input.
extent
Optional feature layer. The extent is the area of interest used to extract the input features. If not specified, all features from each input layer are extracted. See Feature Input.
clip
Optional boolean. A Boolean value that specifies whether the features within the input layer are clipped within the extent. By default, features are not clipped and all features intersecting the extent are returned.
The default is false.
data_format
Optional string. A keyword defining the output data format for your extracted data.
Choice list: [‘FileGeodatabase’, ‘ShapeFile’, ‘KML’, ‘CSV’]
The default is ‘CSV’.
If FileGeodatase is specified and the input layer has attachments:
if clip=False, the attachments will be extracted to the output file
if clip=True, the attachments will not be extracted
output_name
Optional string or dict.
When
output_nameis a string, the output item in your My contents page will be named by the value. Other item properties will receive default values.output_name = "my_extracted_item"
To explicitly provide other item properties, use a dict with the following Syntax.
output_name = {"title": "<title>", "tag": "<tags>", "snippet": "<snippet>", "description": "<description>"}
For more information on these and other item properties, see the Item resource page in the ArcGIS REST API.
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
context
Optional dict. Additional settings such as processing extent and output spatial reference. For extract_data, there are two settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}}
- Returns
resulting item :
Itemif output_name is specified, elseFeature Collection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.# USAGE EXAMPLE: To extract data from highways layer with the extent of a state boundary. ext_state_highway = extract_data(input_layers=[highways.layers[0]], extent=state_area_boundary.layers[0], clip=True, data_format='shapefile', output_name='state highway extracted')
find_existing_locations
-
arcgis.features.analysis.find_existing_locations(input_layers=None, expressions=None, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
find_existing_locationsmethod selects features in the input layer that meet a query you specify. A query is made up of one or more expressions. There are two types of expressions: attribute and spatial. An example of an attribute expression is that a parcel must be vacant, which is an attribute of the Parcels layer (where STATUS = ‘VACANT’). An example of a spatial expression is that the parcel must also be within a certain distance of a river (Parcels within a distance of 0.75 Miles from Rivers).Parameter
Description
input_layers
Required list of feature layers. A list of layers that will be used in the expressions parameter. Each layer in the list can be:
a feature service layer with an optional filter to select specific features, or
a feature collection
See Feature Input.
expressions
Required list of dicts. There are two types of expressions, attribute and spatial.
Example attribute expression:
[{“operator”: “and”,“layer”: 0,“where”: “STATUS = ‘VACANT’”}]Note
operator can be either
andororlayer is the index of the layer in the
input_layersparameter.The where clause must be surrounded by double quotes.
When dealing with text fields, values must be single-quoted (‘VACANT’).
Date fields support all queries except LIKE. Dates are strings in YYYY:MM:DD hh:mm:ss format.
Here’s an example using the date field ObsDate:
“where”: “ObsDate >= ‘1998-04-30 13:30:00’ “
=
Equal
>
Greater than
<
Less than
>=
Greater than or equal to
<=
Less than or equal to
<>
Not equal
LIKE ‘% <string>’
A percent symbol (%) signifies a wildcard, meaning that anything is acceptable in its place-one character, a hundred characters, or no character. This expression would select Mississippi and Missouri among USA state names: STATE_NAME LIKE ‘Miss%’
BETWEEN <value1> AND <value2>
Selects a record if it has a value greater than or equal to <value1> and less than or equal to <value2>. For example, this expression selects all records with an HHSIZE value greater than or equal to 3 and less than or equal to 10:
HHSIZE BETWEEN 3 AND 10
The above is equivalent to:
HHSIZE >= 3 AND HHSIZE <= 10 This operator applies to numeric or date fields. Here is an example of a date query on the field ObsDate:
ObsDate BETWEEN ‘1998-04-30 00:00:00’ AND ‘1998-04-30 23:59:59’
Time is optional.
NOT BETWEEN <value1> AND <value2>
Selects a record if it has a value outside the range between <value1> and less than or equal to <value2>. For example, this expression selects all records whose HHSIZE value is less than 5 and greater than 7.
HHSIZE NOT BETWEEN 5 AND 7
The above is equivalent to:
HHSIZE < 5 OR HHSIZE > 7 This operator applies to numeric or date fields.
Note You can use the
containsrelationship with points and lines. For example, you have a layer of street centerlines (lines) and a layer of manhole covers (points), and you want to find streets that contain a manhole cover. You could usecontainsto find streets that contain manhole covers, but in order for a line to contain a point, the point must be exactly on the line (that is, in GIS terms, they are snapped to each other). If there is any doubt about this, use thewithinDistancerelationship with a suitable distance value.Example spatial expression:
{“operator”: “and”,“layer”: 0,“spatialRel”: “withinDistance”,“selectingLayer”: 1,“distance”: 10,“units”: “miles”}Note
operator can be either
andororlayer is the index of the layer in
the input_layersparameter. The result of the expression is features in this layer.spatialRel is the spatial relationship. There are nine spatial relationships.
distance is the distance to use for the
withinDistanceandnotWithinDistancespatial relationship.units is the units for distance. Units choice list: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’]
An expression may be a list, which denotes a group. The first operator in the group indicates how the group expression is added to the previous expression. Grouping expressions is only necessary when you need to create two or more distinct sets of features from the same layer. One way to think of grouping is that without grouping, you would have to execute
find_existing_locationsmultiple times and merge the results.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_existing_locations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is specified, elseFeatureCollection.
#USAGE EXAMPLE: To find busy (where SEGMENT_TY is 1 and where ARTERIAL_C is 1) streets from the existing seattle streets layer. arterial_streets = find_existing_locations(input_layers=[bike_route_streets], expressions=[{"operator":"","layer":0,"where":"SEGMENT_TY = 1"}, {"operator":"and","layer":0,"where":"ARTERIAL_C = 1"}], output_name='ArterialStreets')
find_hot_spots
-
arcgis.features.analysis.find_hot_spots(analysis_layer, analysis_field=None, divided_by_field=None, bounding_polygon_layer=None, aggregation_polygon_layer=None, output_name=None, context=None, gis=None, estimate=False, shape_type=None, cell_size=None, cell_size_unit=None, distance_band=None, distance_band_unit=None, future=False) 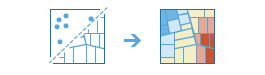
The
find_hot_spotsmethod analyzes point data (such as crime incidents, traffic accidents, or trees) or field values associated with points or area features (such as the number of people in each census tract or the total sales for retail stores). It finds statistically significant spatial clusters of high values (hot spots) and low values (cold spots). For point data when no field is specified, hot spots are locations with lots of points and cold spots are locations with very few points.The result map layer shows hot spots in red and cold spots in blue. The darkest red features indicate the strongest clustering of high values or point densities; you can be 99 percent confident that the clustering associated with these features could not be the result of random chance. Similarly, the darkest blue features are associated with the strongest spatial clustering of low values or the lowest point densities. Features that are beige are not part of a statistically significant cluster; the spatial pattern associated with these features could very likely be the result of random processes and random chance.
Parameter
Description
analysis_layer
Required layer. The point or polygon feature layer for which hot spots will be calculated. See Feature Input.
analysis_field
Optional string. Required if the analysis_layer contains polygons. The numeric field that will be analyzed. The field you select might represent:
counts (such as the number of traffic accidents)
rates (such as the number of crimes per square mile)
averages (such as the mean math test score)
indices (such as a customer satisfaction score)
If an
analysis_fieldis not supplied, hot spot results are based on point densities only.divided_by_field
Optional string. The numeric field in the
analysis_layerthat will be used to normalize your data. For example, if your points represent crimes, dividing by total population would result in an analysis of crimes per capita rather than raw crime counts.You can use esriPopulation to geoenrich each area feature with the most recent population values, which will then be used as the attribute to divide by. This option will use credits.
bounding_polygon_layer
Optional layer. When the analysis layer is points and no
analysis_fieldis specified, you can provide polygons features that define where incidents could have occurred. For example, if you are analyzing boating accidents in a harbor, the outline of the harbor might provide a good boundary for where accidents could occur. When no bounding areas are provided, only locations with at least one point will be included in the analysis. See Feature Input.aggregation_polygon_layer
Optional layer. When the
analysis_layercontains points and noanalysis_fieldis specified, you can provide polygon features into which the points will be aggregated and analyzed, such as administrative units. The number of points that fall within each polygon are counted, and the point count in each polygon is analyzed. See Feature Input.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_hot_spots, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online and ArcGIS Enterprise 11.1+.# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. Is true, the number of credits needed to run the operation will be returned as a float.
shape_type
Optional string. The shape of the polygon mesh the input features will be aggregated into.
Fishnet-The input features will be aggregated into a grid of square (fishnet) cells.Hexagon-The input features will be aggregated into a grid of hexagonal cells.
cell_size
Optional float. The size of the grid cells used to aggregate your features. When aggregating into a hexagon grid, this distance is used as the height to construct the hexagon polygons.
cell_size_unit
Optional string. The units of the
cell_sizevalue. You must provide a value ifcell_sizehas been set.Choice list: [‘Meters’, ‘Miles’, ‘Feet’, ‘Kilometers’]
distance_band
Optional float. The spatial extent of the analysis neighborhood. This value determines which features are analyzed together in order to assess local clustering.
distance_band_unit
Optional string. The units of the
distance_bandvalue. You must provide a value ifdistance_bandhas been set.future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerif output_name is specified, else a dictionary with aFeatureCollectionand processing messages.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To find significant hot ot cold spots of collisions involving a bicycle within a specific boundary. collision_hot_spots = find_hot_spots(collisions, bounding_polygon_layer=boundry_lyr, output_name='collision_hexagon_hot_spots', shape_type='hexagon')
find_nearest
-
arcgis.features.analysis.find_nearest(analysis_layer, near_layer, measurement_type='StraightLine', max_count=100, search_cutoff=2147483647, search_cutoff_units=None, time_of_day=None, time_zone_for_time_of_day='GeoLocal', output_name=None, context=None, gis=None, estimate=False, include_route_layers=None, point_barrier_layer=None, line_barrier_layer=None, polygon_barrier_layer=None, future=False) 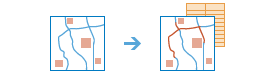
The
find_nearestmethod measures the straight-line distance, driving distance, or driving time from features in the analysis layer to features in the near layer, and copies the nearest features in the near layer to a new layer. Connecting lines showing the measured path are returned as well.find_nearestalso reports the measurement and relative rank of each nearest feature. There are options to limit the number of nearest features to find or the search range in which to find them. The results from this method can help you answer the following kinds of questions:What is the nearest park from here?
Which hospital can I reach in the shortest drive time? And how long would the trip take on a Tuesday at 5:30 p.m. during rush hour?
What are the road distances between major European cities?
Which of these patients reside within two miles of these chemical plants?
Find Nearest returns a layer containing the nearest features and a line layer that links the start locations to their nearest locations. The connecting line layer contains information about the start and nearest locations and the distances between.
Parameter
Description
analysis_layer
Required layer. The features from which the nearest locations are found. This layer can have point, line, or polygon features. See Feature Input.
near_layer
Required layer. The nearest features are chosen from this layer. This layer can have point, line, or polygon features. See Feature Input.
measurement_type
Required string. Specify the mode of transportation for the analysis.
Choice list: [‘StraightLine’, ‘Driving Distance’, ‘Driving Time ‘, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
The default is ‘StraightLine’.
max_count
Optional string. The maximum number of nearest locations to find for each feature in
analysis_layer. The default is the maximum cutoff allowed by the service, which is 100.Note that setting a maxCount for this parameter doesn’t guarantee that many features will be found. The
search_cutoffand other constraints may also reduce the number of features found.search_cutoff
Optional float. The maximum range to search for nearest locations from each feature in the
analysis_layer. The units for this parameter is always minutes whenmeasurement_typeis set to a time based travel mode; otherwise the units are set in thesearch_cutoff_unitsparameter.The default is to search without bounds.
search_cutoff_units
The units of the
search_cutoffparameter. This parameter is ignored whenmeasurement_typeis set to a time based travel mode because the units forsearch_cutoffare always minutes in those cases. Ifmeasurement_typeis set to StraightLine or another distance-based travel mode, and a value forsearch_cutoffis specified, set the cutoff units using this parameter.Choice list: [‘Kilometers’, ‘Meters’, ‘Miles’, ‘Feet’, ‘’]
The default value is null, which causes the service to choose either miles or kilometers according to the units property of the user making the request.
time_of_day
Optional datetime.datetime. Specify whether travel times should consider traffic conditions. To use traffic in the analysis, set
measurement_typeto a travel mode object whose impedance_attribute_name property is set to travel_time and assign a value totime_of_day. (A travel mode with other impedance_attribute_name values don’t support traffic.) Thetime_of_dayvalue represents the time at which travel begins, or departs, from the origin points. The time is specified as datetime.datetime.The service supports two kinds of traffic: typical and live. Typical traffic references travel speeds that are made up of historical averages for each five-minute interval spanning a week. Live traffic retrieves speeds from a traffic feed that processes phone probe records, sensors, and other data sources to record actual travel speeds and predict speeds for the near future.
The data coverage page shows the countries Esri currently provides traffic data for.
Typical Traffic:
To ensure the task uses typical traffic in locations where it is available, choose a time and day of the week, and then convert the day of the week to one of the following dates from 1990:
Monday - 1/1/1990
Tuesday - 1/2/1990
Wednesday - 1/3/1990
Thursday - 1/4/1990
Friday - 1/5/1990
Saturday - 1/6/1990
Sunday - 1/7/1990
Set the time and date as datetime.datetime.
For example, to solve for 1:03 p.m. on Thursdays, set the time and date to 1:03 p.m., 4 January 1990; and convert to datetime eg. datetime.datetime(1990, 1, 4, 1, 3).
Live Traffic:
To use live traffic when and where it is available, choose a time and date and convert to datetime.
Esri saves live traffic data for 4 hours and references predictive data extending 4 hours into the future. If the time and date you specify for this parameter is outside the 24-hour time window, or the travel time in the analysis continues past the predictive data window, the task falls back to typical traffic speeds.
Examples: from datetime import datetime
“time_of_day”: datetime(1990, 1, 4, 1, 3) # 13:03, 4 January 1990. Typical traffic on Thursdays at 1:03 p.m.
“time_of_day”: datetime(1990, 1, 7, 17, 0) # 17:00, 7 January 1990. Typical traffic on Sundays at 5:00 p.m.
“time_of_day”: datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. If the current time is between 8:00 p.m., 21 Oct. 2014 and 8:00 p.m., 22 Oct. 2014, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
“time_of_day”: datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015. If the current time is between 10:20 p.m., 17 Mar. 2015 and 10:20 p.m., 18 Mar. 2015, live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
time_zone_for_time_of_day
Optional string. Specify the time zone or zones of the
time_of_dayparameter.Choice list: [‘GeoLocal’, ‘UTC’]
GeoLocal-refers to the time zone in which the origins_layer points are located.UTC-refers to Coordinated Universal Time.include_route_layers
Optional boolean. When
include_route_layersis set to True, each route from the result is also saved as a route layer item. A route layer includes all the information for a particular route such as the stops assigned to the route as well as the travel directions. Creating route layers is useful if you want to share individual routes with other members in your organization. The route layers use the output feature service name provided in theoutput_nameparameter as a prefix and the route name generated as part of the analysis is added to create a unique name for each route layer.Caution:
Route layers cannot be created when the output is a feature collection. The task will raise an error if
output_nameis not specified (which indicates feature collection output) andinclude_route_layersis True.The maximum number of route layers that can be created is 1,000. If the result contains more than 1,000 routes and
include_route_layersis True, the task will only create the output feature service.point_barrier_layer
Optional layer. Specify one or more point features that act as temporary restrictions (in other words, barriers) when traveling on the underlying streets.
A point barrier can model a fallen tree, an accident, a downed electrical line, or anything that completely blocks traffic at a specific position along the street. Travel is permitted on the street but not through the barrier.
line_barrier_layer
Optional layer. Specify one or more line features that prohibit travel anywhere the lines intersect the streets.
A line barrier prohibits travel anywhere the barrier intersects the streets. For example, a parade or protest that blocks traffic across several street segments can be modeled with a line barrier.
polygon_barrier_layer
Optional layer. Specify one or more polygon features that completely restrict travel on the streets intersected by the polygons.
One use of this type of barrier is to model floods covering areas of the street network and making road travel there impossible.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_nearest, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
A dictionary with the following keys:
”nearest_layer” : layer (
FeatureCollection)”connecting_lines_layer” : layer (
FeatureCollection)
#USAGE EXAMPLE: To find which regional office can be reached in the shortest drive time from esri headquarter. result1 = find_nearest(analysis_layer=esri_hq_lyr, near_layer=regional_offices_lyr, measurement_type="Driving Time", output_name="find nearest office", include_route_layers=True, point_barrier_layer=road_closures_lyr))
find_point_clusters
-
arcgis.features.analysis.find_point_clusters(analysis_layer, min_features_cluster, search_distance=None, search_distance_unit=None, output_name=None, context=None, gis=None, estimate=False, future=False, method=None, sensitivity=None, time_field=None, search_time_interval=None, search_time_unit=None) 
The
find_point_clustersmethod finds clusters of point features within surrounding noise based on their spatial distribution.This method uses unsupervised machine learning clustering algorithms to detect patterns of point features based purely on spatial location and, optionally, the distance to a specified number of features.
The result map shows each cluster identified as well as features considered noise. Multiple clusters will be assigned each color. Colors will be assigned and repeated so that each cluster is visually distinct from its neighboring clusters.
This method uses the DBSCAN, HDBSCAN, or OPTICS method to find clusters. If the method is not specified and the search_distance value is not provided, the HDBSCAN method will be used. If the method is not specified and search_distance value is provided, the DBSCAN algorithm will be used. DBSCAN will use distance, and optionally time, to return clusters with similar densities. It is only appropriate if there is a clear search distance to use for the analysis. HDBSCAN will use a range of distances to separate clusters of varying densities from sparser noise resulting in more data-driven clusters. OPTICS will use the distances, and optionally time, between neighboring features to create a reachability plot, and use it to separate clusters of varying densities from noise.
Parameter
Description
analysis_layer
Required layer. The point feature layer for which density-based clustering will be calculated. See Feature Input.
min_features_cluster
Required integer. The minimum number of features to be considered a cluster. Any cluster with fewer features than the number provided will be considered noise.
search_distance
Optional float. The maximum distance to consider. The Minimum Features per Cluster specified must be found within this distance for cluster membership. Individual clusters will be separated by at least this distance. If a feature is located further than this distance from the next closest feature in the cluster, it will not be included in the cluster.
search_distance_unit
Optional string. The linear unit to be used with the distance value specified for
search_distance. You must provide a value ifsearch_distancehas been set.Choice list: [‘Feet’, ‘Miles’, ‘Meters’, ‘Kilometers’]
The default is ‘Miles’.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_point_clusters, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 11+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the GIS on which this tool runs. If not specified, the active GIS is used.
estimate
Optional Boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, the result will be a GPJob object and results will be returned asynchronously.
method
Optional string. Specifies the method that will be used to find clusters. If the method is not specified and the search_distance value is not provided, the HDBSCAN algorithm will be used. If the method is not specified and the search_distance value is provided, the DBSCAN algorithm will be used.
This parameter is available in ArcGIS Enterprise 11.2 or higher.
Values: “DBSCAN” | “HDBSCAN” | “OPTICS”
sensitivity
Optional float. A double value between 0 and 100 that determines the compactness of the clusters.
This parameter is available in ArcGIS Enterprise 11.2 or higher.
time_field
Optional string. Specifies the field in the analysis_layer value that contains a timestamp for each feature. This parameter is only available in ArcGIS Online.
Example: time_field = “start_time”
Note
Time related parameters can only be used when the method is DBSCAN or OPTICS.
search_time_interval
Optional float. A value that will be used to determine whether features form a space-time cluster. The search time interval spans before and after the time of each feature. This parameter is only available in ArcGIS Online.
Example: search_time_interval = 4
search_time_unit
Optional string. The unit that will be used with the time value specified for search_time_interval. You must provide a value if search_time_interval has been set. This parameter is only available in ArcGIS Online.
Values: “Seconds” | “Minutes” | “Hours” | “Days” | “Weeks” | “Months” | “Years”
Example: search_time_unit = “Minutes”
- Returns
FeatureLayerifoutput_nameis specified, elseFeatureCollection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.USAGE EXAMPLE: To find patterns of traffic accidents purely on spatial location. clusters= find_point_clusters(collision, min_features_cluster=200, search_distance=2, search_distance_unit='Kilometers', output_name='find point clusters')
find_similar_locations
-
arcgis.features.analysis.find_similar_locations(input_layer, search_layer, analysis_fields=None, input_query=None, number_of_results=0, output_name=None, context=None, gis=None, estimate=False, future=False, criteria_fields=None) 
The
find_similar_locationsmethod measures the similarity of candidate locations to one or more reference locations.Based on criteria you specify,
find_similar_locationscan answer questions such as the following:Which of your stores are most similar to your top performers with regard to customer profiles?
Based on characteristics of villages hardest hit by the disease, which other villages are high risk?
To answer questions such as these, you provide the reference locations (the
input_layerparameter), the candidate locations (thesearch_layerparameter), and the fields representing the criteria you want to match. For example, theinput_layermight be a layer containing your top performing stores or the villages hardest hit by the disease. Thesearch_layercontains your candidate locations to search. This might be all of your stores or all other villages. Finally, you supply a list of fields to use for measuring similarity.find_similar_locationswill rank all of the candidate locations by how closely they match your reference locations across all of the fields you have selected.Parameter
Description
input_layer
Required feature layer. The
input_layercontains one or more reference locations against which features in thesearch_layerwill be evaluated for similarity. For example, theinput_layermight contain your top performing stores or the villages hardest hit by a disease. It is not uncommon that theinput_layerandsearch_layerare the same feature service. For example, the feature service contains locations of all stores, one of which is your top performing store. If you want to rank the remaining stores from most to least similar to your top performing store, you can provide a filter for both the inputLayer and thesearch_layer. The filter on theinput_layerwould select the top performing store while the filter on thesearch_layerwould select all stores except for the top performing store. You can also use the optionalinput_queryparameter to specify reference locations.If there is more than one reference location, similarity will be based on averages for the fields you specify in the
analysis_fieldsparameter. So, for example, if there are two reference locations and you are interested in matching population, the task will look for candidate locations in thesearch_layerwith populations that are most like the average population for both reference locations. If the values for the reference locations are 100 and 102, for example, the method will look for candidate locations with populations near 101. Consequently, you will want to use fields for the reference locations fields that have similar values. If, for example, the population values for one reference location is 100 and the other is 100,000, the tool will look for candidate locations with population values near the average of those two values: 50,050. Notice that this averaged value is nothing like the population for either of the reference locations. See Feature Input.search_layer
Required feature layer. The layer containing candidate locations that will be evaluated against the reference locations. See Feature Input.
analysis_fields
Optional list of strings. A list of fields whose values are used to determine similarity. They must be numeric fields and the fields must exist on both the
input_layerand thesearch_layer. The method will find features in thesearch_layerthat have field values closest to those of the features in yourinput_layer.input_query
Optional string. In the situation where the
input_layerand thesearch_layerare the same feature service, this parameter allows you to input a query on theinput_layerto specify which features are the reference locations. The reference locations specified by this query will not be analyzed as candidates. The syntax ofinput_queryis the same as a filter.number_of_results
Optional int. The number of ranked candidate locations output to the
similar_result_layer. Ifnumber_of_resultsis not specified, or set to zero, all candidate locations will be ranked and output.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_similar_locations, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online and ArcGIS Enterprise 11.1+.
# Example Usage >>> locations_output = find_similar_locations( ... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857} }, "outSR": {"wkid": 3857}, "overwrite": True} ... )
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
criteria_fields
Optional list of dicts. The fields in the inputLayer value that correspond to the fields in the search_layer value that will be used to determine similarity. All fields must be numeric fields. The task will rank the features in the search_layer value based on the similarity of their field values to the corresponding field values in the input_layer value. Either an analysis_fields or criteria_fields value must be provided.
This parameter is available in ArcGIS Enterprise 11.2 or higher.
Examples:
[{“referenceField”:”population”, “candidateField”:”pop”}] # (single criteria field)
- [
{“referenceField”:”population”, “candidateField”:” pop”}, {“referenceField”:”age”, “candidateField”:”age”}, {“referenceField”:”edu”, “candidateField”:”education”}
] # (multiple criteria field)
- Returns
FeatureLayerifoutput_nameis specified, else Python dictionary with the following keys:similar_result_layer :
FeatureCollectionprocess_info : list of messages
#USAGE EXAMPLE: To find top 4 most locations from the candidates layer that are similar to the target location. >>> top_4_most_similar_locations = find_similar_locations( target_lyr, candidates_lyr, analysis_fields=['THH17','THH35','THH02','THH05','POPDENS14','FAMGRW10_14','UNEMPRT_CY'], output_name = "top 4 similar locations", number_of_results=4 )
find_centroids
-
arcgis.features.analysis.find_centroids(input_layer, point_location=False, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
find_centroidsmethod that finds and generates points from the representative center (centroid) of each input multipoint, line, or polygon feature. Finding the centroid of a feature is very common for many analytical workflows where the resulting points can then be used in other analytic workflows.For example, polygon features that contain demographic data can be converted to centroids that can be used in network analysis.
Parameter
Description
input_layer
Required feature layer. The multipoint, line, or polygon features that will be used to generate centroid point features. See Feature Input.
point_location
Optional boolean. A Boolean value that determines the output location of the points.
True - Output points will be the nearest point to the actual centroid, but located inside or contained by the bounds of the input feature.
False - Output point locations will be determined by the calculated geometric center of each input feature. This is the default.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service.If overwrite is True in *contextI, new layer will overwrite existing layer.
If output_name not provided, a new
FeatureCollectionis created.
context
Optional dict. Additional settings such as processing extent and output spatial reference. For find_centroids, there are three context settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+.
# Example Usage centroids_res = find_centroids( ... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857 } }, "outSR": {"wkid": 3857}, "overwrite": True } ... )
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean.
If True, a future object will be returned which can be queried for results. The process will return control to user.
If False, the process completes before returning control to the user. The default is False.
- Returns
FeatureLayerifoutput_nameis specifiedFeatureCollectionifoutput_namenot specified
# USAGE EXAMPLE: To find centroids of madison fields nearest to the actual centroids. centroid = find_centroids(madison_fields, point_location=True, output_name='find centroids')
generate_tessellation
-
arcgis.features.analysis.generate_tessellation(extent_layer=None, bin_size=1, bin_size_unit='SquareKilometers', bin_type='SQUARE', intersect_study_area=False, output_name=None, context=None, gis=None, estimate=False, future=False, bin_resolution=None) Generates a tessellated grid of regular polygons.
Parameter
Description
extent_layer
Optional layer. A layer defining the processing extent.
bin_size
Optional Float. The size of each individual shape that makes up the tessellation.
bin_size_unit
Optional String. Size unit of each individual shape. The allowed values are: ‘SquareKilometers’, ‘Hectares’, ‘SquareMeters’, ‘SquareMiles’, ‘Acres’, ‘SquareYards’, ‘SquareFeet’, ‘SquareInches’, ‘Miles’, ‘Yards’, ‘Feet’, ‘Kilometers’, ‘Meters’, and ‘NauticalMiles’.
bin_type
Optional String. The type of shape to tessellate. Allowed values are: ‘SQUARE’, ‘HEXAGON’, ‘TRIANGLE’, ‘DIAMOND’, ‘TRANSVERSEHEXAGON’, or H3_HEXAGON.
intersect_study_area
Optional Boolean. A boolean defines whether to keep only tessellations intersect with the study area.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For generate_tesselation, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional Boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
bin_resolution
Optional Integer. This becomes required when H3_HEXAGON is used. The H3 resolution of the hexagons. Resolution ranges from 0 to 15. With each increasing resolution size, the area of the polygons will be one seventh the size.
Note
The tool requires either an ‘extent’ given in the context or an extent_layer.
- Returns
FeatureLayerif out_put name specified or aFeatureLayerCollection. Iffuture = True, then the result is aFutureobject. Callresult()to get the response.
interpolate_points
-
arcgis.features.analysis.interpolate_points(input_layer, field, interpolate_option='5', output_prediction_error=False, classification_type='GeometricInterval', num_classes=10, class_breaks=[], bounding_polygon_layer=None, predict_at_point_layer=None, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
interpolate_pointsmethod allows you to predict values at new locations based on measurements from a collection of points. The method takes point data with values at each point and returns areas classified by predicted values. For example:An air quality management district has sensors that measure pollution levels.
interpolate_pointscan be used to predict pollution levels at locations that don’t have sensors, such as locations with at-risk populations, schools, or hospitals, for example.Predict heavy metal concentrations in crops based on samples taken from individual plants.
Predict soil nutrient levels (nitrogen, phosphorus, potassium, and so on) and other indicators (such as electrical conductivity) in order to study their relationships to crop yield and prescribe precise amounts of fertilizer for each location in the field.
Meteorological applications include prediction of temperatures, rainfall, and associated variables (such as acid rain).
interpolate_pointsuses the Empirical Bayesian Kriging geoprocessing tool to perform the interpolation. The parameters that are supplied to the Empirical Bayesian Kriging tool are controlled by theinterpolate_optionrequest parameter.If a value of 1 is provided for
interpolate_option, empirical Bayesian kriging will use the following parameters:transformation_type - NONE
semivariogram_model_type - POWER
max_local_points - 50
overlap_factor - 1
number_semivariograms - 30
nbrMin - 8
nbrMax - 8
If a value of 5 is provided for
interpolate_option, empirical Bayesian kriging will use the following parameters:transformation_type - NONE
semivariogram_model_type - POWER
max_local_points 75
overlap_factor - 1.5
number_semivariograms - 100
nbrMin - 10
nbrMax - 10
If a value of 9 is provided for
interpolate_option, empirical Bayesian kriging will use the following parameters:transformation_type - EMPIRICAL
semivariogram_model_type - K_BESSEL
max_local_points - 200
overlap_factor - 3
number_semivariograms - 200
nbrMin - 15
nbrMax - 15
Parameter
Description
input_layer
Required layer. The point layer whose features will be interpolated. See Feature Input.
field
Required string. Name of the numeric field containing the values you wish to interpolate.
interpolate_option
Optional integer. Integer value declaring your preference for speed versus accuracy, from 1 (fastest) to 9 (most accurate). More accurate predictions take longer to calculate.
Choice list: [1, 5, 9].
The default is 5.
output_prediction_error
Optional boolean. If True, a polygon layer of standard errors for the interpolation predictions will be returned in the
prediction_erroroutput parameter.Standard errors are useful because they provide information about the reliability of the predicted values. A simple rule of thumb is that the true value will fall within two standard errors of the predicted value 95 percent of the time. For example, suppose a new location gets a predicted value of 50 with a standard error of 5. This means that this task’s best guess is that the true value at that location is 50, but it reasonably could be as low as 40 or as high as 60. To calculate this range of reasonable values, multiply the standard error by 2, add this value to the predicted value to get the upper end of the range, and subtract it from the predicted value to get the lower end of the range.
classification_type
Optional string. Determines how predicted values will be classified into areas.
EqualArea- Polygons are created such that the number of data values in each area is equal.
For example, if the data has more large values than small values, more areas will be created for large values.
EqualInterval- Polygons are created such that the range of predicted values is equal for each area.GeometricInterval- Polygons are based on class intervals that have a geometrical series. This method ensures that each class range has approximately the same number of values within each class and that the change between intervals is consistent.Manual- You to define your own range of values for areas. These values will be entered in theclass_breaksparameter below.
Choice list: [‘EqualArea’, ‘EqualInterval’, ‘GeometricInterval’, ‘Manual’]
The default is ‘GeometricInterval’.
num_classes
Optional integer. This value is used to divide the range of interpolated values into distinct classes. The range of values in each class is determined by the
classification_typeparameter. Each class defines the boundaries of the result polygons.The default is 10. The maximum value is 32.
class_breaks
Optional list of floats. If
classification_typeis Manual, supply desired class break values separated by spaces. These values define the upper limit of each class, so the number of classes will equal the number of entered values. Areas will not be created for any locations with predicted values above the largest entered break value. You mst enter at least two values and no more than 32.bounding_polygon_layer
Optional layer. A layer specifying the polygon(s) where you want values to be interpolated. For example, if you are interpolating densities of fish within a lake, you can use the boundary of the lake in this parameter and the output will only contain polygons within the boundary of the lake. See Feature Input.
predict_at_point_layer
Optional layer. An optional layer specifying point locations to calculate prediction values. This allows you to make predictions at specific locations of interest. For example, if the
input_layerrepresents measurements of pollution levels, you can use this parameter to predict the pollution levels of locations with large at-risk populations, such as schools or hospitals. You can then use this information to give recommendations to health officials in those locations.If supplied, the output
predicted_point_layerwill contain predictions at the specified locations. See Feature Input.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For interpolate_points, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage >>> context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100, "latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional, If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerifoutput_nameis specified, else Python dictionary with the following keys:”result_layer” : layer (
FeatureCollection)”prediction_error” : layer (
FeatureCollection)”predicted_point_layer” : layer (
FeatureCollection)If
future = True, then the result is aFutureobject. Callresult()to get the response.
#USAGE EXAMPLE: To predict mine production in US at new locations. >>> interpolated = interpolate_points(coal_mines_us, field='Total_Prod', interpolate_option=5, output_prediction_error=True, classification_type='GeometricInterval', num_classes=10, output_name='interpolate coal mines production')
join_features
-
arcgis.features.analysis.join_features(target_layer, join_layer, spatial_relationship=None, spatial_relationship_distance=None, spatial_relationship_distance_units=None, attribute_relationship=None, join_operation='JoinOneToOne', summary_fields=None, output_name=None, context=None, gis=None, estimate=False, future=False, join_type='INNER', records_to_match=None) 
The
join_featuresmethod works with two layers and joins the attributes from one feature to another based on spatial and attribute relationships.Parameter
Description
target_layer
Required layer. The point, line, polygon or table layer that will have attributes from the
join_layerappended to its table. See Feature Input.join_layer
Required layer. The point, line, polygon or table layer that will be joined to the
target_layer. See Feature Input.spatial_relationship
Required string if inputs are not table layers. Defines the spatial relationship used to spatially join features.
Choice list:
identicalto
intersects
completelycontains
completelywithin
withindistance
spatial_relationship_distance
Optional float. Required if spatial_relationship is withindistance. A value used for the search distance to determine if the target features are near or within a specified distance of the join features.
Note
Only applied if withindistance is the spatial_relationship argument.
You can only enter a single distance value.
spatial_relationship_distance_units
Optional string. Required if spatial_relationship argument is withindistance. The linear unit to be used with the distance value specified as the spatial_relationship_distance argument.
Choice list:
Miles
Yards
Feet
NauticalMiles
Meters
Kilometers
attribute_relationship
Optional list of dicts. Defines an attribute relationship used to join features. Features are matched when the field values in the join layer are equql to field values in the target layer.
join_operation
Optional string. A string representing the type of join that will be applied
Choice list:
JoinOneToOne - If multiple join features are found that have the same relationships with a single target feature, the attributes from the multiple join features will be aggregated using the specified summary statistics. For example, if a point target feature is found within two separate polygon join features, the attributes from the two polygons will be aggregated before being transferred to the output point feature class. If one polygon has an attribute value of 3 and the other has a value of 7, and a SummaryField of sum is selected, the aggregated value in the output feature class will be 10. There will always be a Count field calculated, with a value of 2, for the number of features specified. This is the default.
JoinOneToMany - If multiple join features are found that have the same relationship with a single target feature, the output feature class will contain multiple copies (records) of the target feature. For example if a single point target feature is found within two separate polygon join features, the output feature class will contain two copies of the target feature: one record with the attributes of the first polygon, and another record with the attributes of the second polygon. There are no summary statistics calculated with this method.
summary_fields
Optional list of dicts. A list of field names and statistical summary types that you want to calculate. Note that the count is always returned by default.
Format of argument:
>>> join_features(... summary_fields= [ {"onStatisticField": "fieldName", "statisticType": "statisticName"}, {"onStatisticField": "fieldName", "statisticType": "statisticName"} ], ...)
statisticType name is one of the following:
SUM- Adds the total value of all the points in each polygonMEAN- Calculates the average of all the points in each polygonMIN- Finds the smallest value of all the points in each polygonMAX- Finds the largest value of all the points in each polygonSTDDEV- Finds the standard deviation of all the points in each polygonCOUNT- Finds the number of non-null values, used on numeric fields or strings.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service.If overwrite is True in context, new layer will overwrite existing layer.
If output_name not indicated then a new
FeatureCollectionis created.
context
Optional dict. Additional settings such as processing extent and output spatial reference. For join_features, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage >>> join_res = join_features(... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857} }, "outSR": {"wkid": 3857}, "overwrite": True }. ... )
estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean.
If True, a future object will be returned and the process returns control to the user.
If False, the process waits for the results to complete before returning control to the user. The default is False.
join_type
Optional String. Determines the type of join performed on the datasets. The allowed values are;
INNER
LEFT
records_to_match
Optional Dict. Defines how two features are joined.
Example:
{“groupByFields”:””,“orderByFields”:”objectid ASC”,“topCount”:1}- Returns
FeatureLayerif output_name is specified, elseFeatureCollection.
USAGE EXAMPLE: To summarize traffic accidents within each parcel using spatial relationship. >>> accident_count_in_each_parcel = join_features( target_layer=parcel_lyr, join_layer=traffic_accidents_lyr, spatial_relationship='intersects', summary_fields=[ {"statisticType": "Mean", "onStatisticField": "Population"} ], output_name='join features', context={ "extent":{ "xmin":-9375809.87305117, "ymin":4031882.3806860778, "xmax":-9370182.196843527, "ymax":4034872.9794178144, "spatialReference":{ "wkid":102100, "latestWkid":3857 } } })
USAGE EXAMPLE: To summarize into count using spatial relationship. >>> accident_count_in_each_parcel = join_features( target_layer=FeatureLayer(fs_url), join_layer=lyr_to_join, spatial_relationship='intersects', summary_fields = [ {"statisticType":"COUNT", "onStatisticField":None} ], output_name='return join features in count')
merge_layers
-
arcgis.features.analysis.merge_layers(input_layer, merge_layer, merging_attributes=[], output_name=None, context=None, gis=None, estimate=False, future=False) 
The
merge_layersmethod copies features from two layers into a new layer. The layers to be merged must all contain the same feature types (points, lines, or polygons). You can control how the fields from the input layers are joined and copied. For example:I have three layers for England, Wales, and Scotland and I want a single layer of Great Britain.
I have two layers containing parcel information for contiguous townships. I want to join them together into a single layer, keeping only the fields that have the same name and type on the two layers.
Parameter
Description
input_layer
Required feature layer. The point, line or polygon features with the
merge_layer. See Feature Input.merge_layer
Required feature layer. The point, line, or polygon features to merge with the
input_layer. Themerge_layermust contain the same feature type (point, line, or polygon) as theinput_layer. See Feature Input.merge_attributes
Optional list. Defines how the fields in
merge_layerwill be modified. By default, all fields from both inputs will be included in the output layer.If a field exists in one layer but not the other, the output layer will still contain the field. The output field will contain null values for the input features that did not have the field. For example, if the
input_layercontains a field named TYPE but themerge_layerdoes not contain TYPE, the output will contain TYPE, but its values will be null for all the features copied from themerge_layer.You can control how fields in the
merge_layerare written to the output layer using the following merge types that operate on a specifiedmerge_layerfield:Remove- The field in themerge_layerwill be removed from the output layer.Rename- The field in themerge_layerwill be renamed in the output layer. You cannot rename a field in themerge_layerto a field in theinput_layer. If you want to make field names equivalent, use Match.Match- A field in themerge_layeris made equivalent to a field in theinput_layerspecified by merge value. For example, theinput_layerhas a field named CODE and themerge_layerhas a field named STATUS. You can match STATUS to CODE, and the output will contain the CODE field with values of the STATUS field used for features copied from themerge_layer. Type casting is supported (for example, float to integer, integer to string) except for string to numeric.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For merge_layers, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the estimated number of credits required to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerifoutput_nameis specified, else Feature Collection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.#USAGE EXAMPLE: To merge two layers into a new layer using merge attributes. merged = merge_layers(input_layer=esri_offices, merge_layer=satellite_soffice_lyr, merging_attributes=["State Match Place_Name"], output_name="merge layers")
overlay_layers
-
arcgis.features.analysis.overlay_layers(input_layer, overlay_layer, overlay_type='Intersect', snap_to_input=False, output_type='Input', tolerance=None, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
overlay_layersmethod combines two or more layers into one single layer. You can think of overlay as peering through a stack of maps and creating a single map containing all the information found in the stack. In fact, before the advent of GIS, cartographers would literally copy maps onto clear acetate sheets, overlay these sheets on a light table, and hand draw a new map from the overlaid data. Overlay is much more than a merging of line work; all the attributes of the features taking part in the overlay are carried through to the final product. Overlay is used to answer one of the most basic questions of geography, “what is on top of what?” For example:What parcels are within the 100-year floodplain? (Within is just another way of saying on top of.)
What roads are within what counties?
What land use is on top of what soil type?
What wells are within abandoned military bases?
Parameter
Description
input_layer
Required layer. The point, line, or polygon features that will be overlayed with the
overlay_layer. See Feature Input.overlay_layer
Required layer. The features that will be overlaid with the
input_layerfeatures. See Feature Input.overlay_type
Optional string. The type of overlay to be performed.
Choice list: [‘Intersect’, ‘Union’, ‘Erase’]

Intersect-Computes a geometric intersection of the input layers. Features or portions of features which overlap in both theinput_layerandoverlay_layerlayer will be written to the output layer. This is the default.
Union-Computes a geometric union of the input layers. All features and their attributes will be written to the output layer. This option is only valid if both theinput_layerand theoverlay_layercontain polygon features.
Erase-Only those features or portions of features in theoverlay_layerthat are not within the features in theinput_layerlayer are written to the output.The default value is ‘Intersect’.
snap_to_input
Optional boolean. A Boolean value indicating if feature vertices in the
input_layerare allowed to move. The default is false and means if the distance between features is less than thetolerancevalue, all features from both layers can move to allow snapping to each other. When set to true, only features inoverlay_layercan move to snap to theinput_layerfeatures.output_type
Optional string. The type of intersection you want to find. This parameter is only valid when the
overlay_typeis Intersect.Choice list: [‘Input’, ‘Line’, ‘Point’]
Input- The features returned will be the same geometry type as theinput_layeroroverlay_layerwith the lowest dimension geometry. If all inputs are polygons, the output will contain polygons. If one or more of the inputs are lines and none of the inputs are points, the output will be line. If one or more of the inputs are points, the output will contain points. This is the default.Line- Line intersections will be returned. This is only valid if none of the inputs are points.Point- Point intersections will be returned. If the inputs are line or polygon, the output will be a multipoint layer.
tolerance
Optional float. A float value of the minimum distance separating all feature coordinates as well as the distance a coordinate can move in X or Y (or both). The units of tolerance are the same as the units of the
input_layer.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For overlay_layers, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerifoutput_nameis specified, else Feature Collection.
If
future = True, then the result is aFutureobject. Callresult()to get the response.#USAGE EXAMPLE: To clip a buffer in the shape of Capitol hill neighborhood. cliped_buffer = overlay_layers(buffer, neighbourhood, output_name="Cliped buffer")
plan_routes
-
arcgis.features.analysis.plan_routes(stops_layer, route_count, max_stops_per_route, route_start_time, start_layer, start_layer_route_id_field=None, return_to_start=True, end_layer=None, end_layer_route_id_field=None, travel_mode=None, stop_service_time=0, max_route_time=525600, include_route_layers=False, output_name=None, context=None, gis=None, estimate=False, point_barrier_layer=None, line_barrier_layer=None, polygon_barrier_layer=None, future=False) 
The
plan_routesmethod determines how to efficiently divide tasks among a mobile workforce.You provide the input, which includes a set of stops and the number of vehicles available to visit the stops, and the tool assigns the stops to vehicles and returns routes showing how each vehicle can reach their assigned stops in the least amount of time.
With
plan_routes, mobile workforces reach more jobsites in less time, which increases productivity and improves customer service. Organizations often useplan_routesto:Inspect homes, restaurants, and construction sites
Provide repair, installation, and technical services
Deliver items and small packages
Make sales calls
Provide van transportation from spectators’ homes to events
The output from
plan_routesincludes a layer of routes showing the shortest paths to visit the stops; a layer of the stops assigned to routes, as well as any stops that couldn’t be reached due to the given parameter settings; and a layer of directions containing the travel itinerary for each route.Parameter
Description
stops_layer
Required feature layer. The points that the vehicles, drivers, or routes, should visit. The fields on the input stops are included in the output stops, so if your input layer has a field such as Name, Address, or ProductDescription, that information will be available in the results. See Feature Input.
route_count
Required integer. The number of vehicles that are available to visit the stops. The method supports up to 100 vehicles.
The default value is 0.
The method may be able to find and return a solution that uses fewer vehicles than the number you specify for this parameter. The number of vehicles returned also depends on four other parameters: the total number of stops in
stops_layer, the number of stops per vehicle you allow (max_stops_per_route), the travel time between stops, the time spent at each stop (stop_service_time), and any limit you set on the total route time per vehicle (max_route_time).max_stops_per_route
Required integer. The maximum number of stops a route, or vehicle, is allowed to visit. The largest value you can specify is 200. The default value is zero.
This is one of two parameters that balance the overall workload across routes. The other is
max_route_timeBy lowering the maximum number of stops that can be assigned to each vehicle, the vehicles are more likely to have an equal number of stops assigned to them. This helps balance workloads among drivers. The drawback, however, is that it may result in a solution that is less efficient.
By increasing the stops per vehicle, the tool has more freedom to find more efficient solutions; however, the workload may be unevenly distributed among drivers and vehicles. Note that you can balance workloads by time instead of number of stops by specifying a value for the
max_route_timeparameter.The following examples demonstrate the effects of limiting the maximum stops per vehicle or the total time per vehicle. In all of these examples, two routes start at the same location and visit a total of six stops.
Balanced travel times and stops per route:
The stops are more or less uniformly spread apart, so setting ``max_stops_per_route``=3 to evenly distribute the workload results in routes that are roughly the same duration.
Balanced stops per route but unbalanced travel times:
Five of the six stops are clustered near the starting location, but one stop is set apart and requires a much longer drive to be reached. Dividing the stops equally between the two routes (
max_stops_per_route=3) causes unbalanced travel times.
Unbalanced stops per route but balanced travel times:
The stops are in the same location as the previous graphic. By increasing the value of
max_stops_per_routeto 4, and limiting the total travel time per vehicle (max_route_time), the travel times are balanced even though one route visits more stops.route_start_time
Required datetime.datetime. Specify when the vehicles or people start their routes. The time is specified as datetime. The starting time value is the same for all routes; that is, all routes start at the same time.
Time zones affect what value you assign to
route_start_time. The time zone for the start time is based on the time zone in which the starting point is geographically located. For instance, if you have one route starting location and it is located in Pacific Standard Time (PST), the time you specify forroute_start_timeis in PST.There are a couple of scenarios to beware of given that starting times are based on where the starting points are located. One situation to be careful of is when you are located in one time zone but your starting locations are in another times zone. For instance, assume you are in Pacific Standard Time (UTC-8:00) and the vehicles you are routing are stationed in Mountain Standard Time (UTC-7:00). If it is currently 9:30 a.m. PST (10:30 a.m. MST) and your vehicles need to begin their routes in 30 minutes, you would set the start time to 11:00 a.m. That is, the starting locations for the routes are in the Mountain time zone, and it is currently 10:30 a.m. there, therefore, a starting time of 30 minutes from now is 11:00 a.m. Make sure you set the parameter according to the proper time zone.
The other situation that requires caution is where starting locations are spread across multiple time zones. The time you set for
route_start_timeis specific to the time zone in which the starting location is regardless of whether there are one or more starting locations in the problem you submit. For instance, if one route starts from a point in PST and another route starts from MST, and you enter 11:00 a.m. as the start time, the route in PST will start at 11:00 a.m. PST and the route in MST will start at 11:00 a.m. MST a one-hour difference. The starting times are the same in local time, but offset in actual time, or UTC.The service automatically determines the time zones of the input starting locations (
start_layer) for you.Examples:
datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. Routes will depart their starting locations at 8:00 a.m., 22 October. Any routes with starting points in Mountain Standard Time start at 8:00 a.m., 22 October 2014 MST; any routes with starting points in Pacific Standard Time start at 8:00 a.m. 22 October 2014 PST, and so on.
datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015.
start_layer
Required feature layer. Provide the locations where the people or vehicles start their routes. You can specify one or many starting locations.
If specifying one, all routes will start from the one location. If specifying many starting locations, each route needs exactly one predefined starting location, and the following criteria must be met:
The number of routes (
route_count) must equal the number of points instart_layer. (However, when only one point is included instart_layer, it is assumed that all routes start from the same location, and the two numbers can be different.) The starting location for each route must be identified with thestart_layer_route_id_fieldparameter. This implies that the input points instart_layerhave a unique identifier. Bear in mind that if you also have many ending locations, those locations need to be predetermined as well. The predetermined start and end locations of each route are paired together by matching route ID values. See the the section of this topic entitled Starting and ending locations of routes to learn more. See Feature Input.start_layer_route_id_field
Optional string. Choose a field that uniquely identifies points in start_layer. This parameter is required when
start_layerhas more than one point; it is ignored otherwise.The
start_layer_route_id_fieldparameter helps identify where routes begin and indicates the names of the output routes.See the the section of this topic entitled Starting and ending locations of routes to learn more.
return_to_start
Optional boolean. A True value indicates each route must end its trip at the same place where it started. The starting location is defined by the
start_layerandstart_layer_route_id_fieldparameters.The default value is True.
end_layer
Optional layer. Provide the locations where the people or vehicles end their routes.
If
end_layeris not specified,return_to_startmust be set to True.You can specify one or many ending locations.
If specifying one, all routes will end at the one location. If specifying many ending locations, each route needs exactly one predefined ending location, and the following criteria must be met:
The number of routes (
route_count) must equal the number of points inend_layer. (However, when only one point is included inend_layer, it is assumed that all routes end at the same location, and the two numbers can be different.)The ending location for each route must be identified with the
start_layer_route_id_fieldparameter. This implies that the input points in endLayer have a unique identifier. Bear in mind that if you also have many starting locations, those locations need to be predetermined as well. The predetermined start and end locations of each route are paired together by matching route ID values. See Feature Input.
end_layer_route_id_field
Optional string. Choose a field that uniquely identifies points in
end_layer. This parameter is required whenend_layerhas more than one point; it is ignored if there is one point or ifreturn_to_startis True.The
end_layer_route_id_fieldparameter helps identify where routes end and indicates the names of the output routes.See the the section of this topic entitled Starting and ending locations of routes to learn more.
travel_mode
Optional string. Optional string. Specify the mode of transportation for the analysis.
Choice list: [‘Driving Distance’, ‘Driving Time’, ‘Rural Driving Distance’, ‘Rural Driving Time’, ‘Trucking Distance’, ‘Trucking Time’, ‘Walking Distance’, ‘Walking Time’]
stop_service_time
Optional float. Indicates how much time, in minutes, is spent at each stop. The units are minutes. All stops are assinged the same service duration from this parameter unique values for individual stops cannot be specified with this service.
max_route_time
Optional float. The amount of time you specify here limits the maximum duration of each route. The maximum route time is an accumulation of travel time and the total service time at visited stops (
stop_service_time). This parameter is commonly used to prevent drivers from working too many hours or to balance workloads across routes or drivers.The units are ‘minutes’. The default value, which is also the maximum value, is 525600 minutes, or one year.
include_route_layers
Optional boolean. When
include_route_layersis set to True, each route from the result is also saved as a route layer item. A route layer includes all the information for a particular route such as the stops assigned to the route as well as the travel directions. Creating route layers is useful if you want to share individual routes with other members in your organization. The route layers use the output feature service name provided in theoutput_nameparameter as a prefix and the route name generated as part of the analysis is added to create a unique name for each route layer.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For plan_routes, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
gis
Optional, the
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
point_barrier_layer
Optional feature layer. Specify one or more point features that act as temporary restrictions (in other words, barriers) when traveling on the underlying streets.
A point barrier can model a fallen tree, an accident, a downed electrical line, or anything that completely blocks traffic at a specific position along the street. Travel is permitted on the street but not through the barrier. See Feature Input.
line_barrier_layer
Optional feature layer. Specify one or more line features that prohibit travel anywhere the lines intersect the streets.
A line barrier prohibits travel anywhere the barrier intersects the streets. For example, a parade or protest that blocks traffic across several street segments can be modeled with a line barrier. See Feature Input.
polygon_barrier_layer
Optional feature layer. Specify one or more polygon features that completely restrict travel on the streets intersected by the polygons.
One use of this type of barrier is to model floods covering areas of the street network and making road travel there impossible. See Feature Input.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
FeatureLayerifoutput_nameis specified, else dict with the following keys:”routes_layer” : layer (
FeatureCollection)”assigned_stops_layer” : layer (
FeatureCollection)”unassigned_stops_layer” : layer (
FeatureCollection)
# USAGE EXAMPLE: To plan routes to provide cab from employee residence to office. route = plan_routes(stops_layer=employee_residence, route_count=4, max_stops_per_route=4, route_start_time=datetime(2019, 6, 20, 6, 0), start_layer=office_location, start_layer_route_id_field='n_office', return_to_start=False, end_layer=office_location, end_layer_route_id_field='n_office', travel_mode='Driving Time', stop_service_time=5, include_route_layers=False, output_name='plan route for employees')
summarize_nearby
-
arcgis.features.analysis.summarize_nearby(sum_nearby_layer, summary_layer, near_type='StraightLine', distances=[], units='Meters', time_of_day=None, time_zone_for_time_of_day='GeoLocal', return_boundaries=True, sum_shape=True, shape_units=None, summary_fields=[], group_by_field=None, minority_majority=False, percent_shape=False, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
summarize_nearbymethod finds features that are within a specified distance of features in the input layer. Distance can be measured as a straight-line distance, a drive-time distance (for example, within 10 minutes), or a drive distance (within 5 kilometers). Statistics are then calculated for the nearby features. For example:Calculate the total population within five minutes of driving time of a proposed new store location.
Calculate the number of freeway access ramps within a one-mile driving distance of a proposed new store location to use as a measure of store accessibility.
Parameter
Description
sum_nearby_layer
Required
FeatureLayer. Point, line, or polygon features from which distances will be measured to features in thesummary_layer. See Feature Input.summary_layer
Required layer. Point, line, or polygon features. Features in this layer that are within the specified distance to features in the
sum_nearby_layerwill be summarized. See Feature Input.near_type
Optional string. Defines what kind of distance measurement you want to use, either straight-line distance, travel time or travel distance along a street network using various modes of transportation known as travel modes. The default is
StraightLine.Choice list:
StraightLineDriving DistanceDriving TimeRural Driving DistanceRural Driving TimeTrucking DistanceTrucking TimeWalking DistanceWalking Time
distances
Optional list of float values. Defines the search distance for
StraightLineand distance-based travel modes, or time duration for time-based travel modes. You can enter single or multiple values, separating each value with a space. Features that are within (or equal to) the distances you enter will be summarized. The unit for distances is supplied by the units parameter.units
Optional string. If
near_typeisStraightLineor a distance-based travel mode, this is the linear unit to be used with the distance value(s) specified in distances.Choice list: | [
Meters,Kilometers,Feet,Yards,Miles]If
near_typeis a time-based travel mode, the following values can be used as units:Choice list:
[Seconds,Minutes,Hours]The default is ‘Meters’.
time_of_day
Optional datetime.datetime. Specify whether travel times should consider traffic conditions. To use traffic in the analysis, set
near_typeto a travel mode object whose impedance_attribute_name property is set to travel_time and assign a value totime_of_day. (A travel mode with other impedance_attribute_name values don’t support traffic.) Thetime_of_dayvalue represents the time at which travel begins, or departs, from the origin points. The time is specified as datetime.datetime.The service supports two kinds of traffic: typical and live. Typical traffic references travel speeds that are made up of historical averages for each five-minute interval spanning a week. Live traffic retrieves speeds from a traffic feed that processes phone probe records, sensors, and other data sources to record actual travel speeds and predict speeds for the near future.
The data coverage page shows the countries Esri currently provides traffic data for.
Typical Traffic:
To ensure the task uses typical traffic in locations where it is available, choose a time and day of the week, and then convert the day of the week to one of the following dates from 1990:
Monday - 1/1/1990
Tuesday - 1/2/1990
Wednesday - 1/3/1990
Thursday - 1/4/1990
Friday - 1/5/1990
Saturday - 1/6/1990
Sunday - 1/7/1990
Set the time and date as datetime.datetime.
For example, to solve for 1:03 p.m. on Thursdays, set the time and date to 1:03 p.m., 4 January 1990; and convert to datetime eg. datetime.datetime(1990, 1, 4, 1, 3).
Live Traffic:
To use live traffic when and where it is available, choose a time and date and convert to datetime.
Esri saves live traffic data for 4 hours and references predictive data extending 4 hours into the future. If the time and date you specify for this parameter is outside the 24-hour time window, or the travel time in the analysis continues past the predictive data window, the task falls back to typical traffic speeds.
Examples: from datetime import datetime
“time_of_day”- datetime(1990, 1, 4, 1, 3) # 13:03, 4 January 1990. Typical traffic on Thursdays at 1:03 p.m.
“time_of_day”- datetime(1990, 1, 7, 17, 0) # 17:00, 7 January 1990. Typical traffic on Sundays at 5:00 p.m.
“time_of_day”- datetime(2014, 10, 22, 8, 0) # 8:00, 22 October 2014. If the current time is between 8:00 p.m., 21 Oct. 2014 and 8:00 p.m., 22 Oct. 2014,
Live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced. * “time_of_day”- datetime(2015, 3, 18, 10, 20) # 10:20, 18 March 2015. If the current time is between 10:20 p.m., 17 Mar. 2015 and 10:20 p.m., 18 Mar. 2015, Live traffic speeds are referenced in the analysis; otherwise, typical traffic speeds are referenced.
time_zone_for_time_of_day
Optional string. Specify the time zone or zones of the
time_of_dayparameter.Choice list: [‘GeoLocal’, ‘UTC’]
GeoLocal-refers to the time zone in which the originsLayer points are located.
UTC-refers to Coordinated Universal Time.
The default is ‘GeoLocal’.
return_boundaries
Optional boolean. If true, the
result_layerwill contain areas defined by the specifiednear_type. For example, if usingStraightLineof 5 miles, theresult_layerwill contain areas with a 5 mile radius around the inputsum_nearby_layerfeatures.If False, the
result_layerwill contain the same features as thesum_nearby_layer.The default is True.
sum_shape
Optional boolean. A boolean value that instructs the task to calculate statistics based on shape type of the
summary_layer, such as the length of lines or areas of polygons of thesummary_layerwithin each polygon insum_within_layer.The default is True.
shape_units
Optional string. If
sum_shapeis true, you must specify the units of the shape summary. Values:When
summary_layercontains polygons: Values: [‘Acres’, ‘Hectares’, ‘SquareMeters’, ‘SquareKilometers’, ‘SquareFeet’, ‘SquareYards’, ‘SquareMiles’]When
summary_layercontains lines: Values: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’]
summary_fields
Optional list of strings.A list of field names and statistical summary types that you want to calculate. Note that the count is always returned by default.
Format:
[“fieldName statisticType”, …]
fieldName is the name of one of the numeric fields found in the input join layer.
statisticType is one of the following:
SUM-Adds the total value of all the points in each polygonMEAN-Calculates the average of all the points in each polygonMIN-Finds the smallest value of all the points in each polygonMAX-Finds the largest value of all the points in each polygonSTDDEV-Finds the standard deviation of all the points in each polygon
# Example: >>> summ_output = summarize_nearby( ... summary_fields = ["Population MEAN","Households SUM"], ... )
group_by_field
Optional string. This is a field of the
summary_layerfeatures that you can use to calculate statistics separately for each unique attribute value. For example, suppose thesummary_layercontains point locations of businesses that store hazardous materials, and one of the fields is HazardClass containing codes that describe the type of hazardous material stored. To calculate summaries by each unique value of HazardClass, use HazardClass as thegroup_by_fieldfield.minority_majority
Optional boolean. This boolean parameter is applicable only when a
group_by_fieldis specified. If true, the minority (least dominant) or the majority (most dominant) attribute values for each group field within each nearby area are calculated. Two new fields are added to theresult_layerprefixed with Majority_ and Minority_.The default is False.
percent_shape
Optional boolean. This Boolean parameter is applicable only when a
group_by_fieldis specified. If set to true, the percentage of each uniquegroup_by_fieldvalue is calculated for eachsum_nearby_layerfeature.The default is False.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For summarize_nearby, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
estimate
Optional boolean. Returns the number of credit for the operation.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollectiondictionary.dict with the following keys:
”result_layer” : layer (
FeatureCollection)”group_by_summary” : layer (
FeatureCollection)
# USAGE EXAMPLE: To find hospital facilities that are within 5 miles of a school. summarize_nearby(sum_nearby_layer=item2.layers[0], summary_layer=item1.layers[0], near_type='StraightLine', distances=[5], units='Miles', time_zone_for_time_of_day='GeoLocal', return_boundaries=False, sum_shape=True, shape_units=None, output_name='nearest hospitals to schools')
summarize_center_and_dispersion
-
arcgis.features.analysis.summarize_center_and_dispersion(analysis_layer, summarize_type=['CentralFeature'], ellipse_size=None, weight_field=None, group_field=None, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
summarize_center_and_dispersionmethod finds central features and directional distributions. It can be used to answer questions such as:Where is the center?
Which feature is the most accessible from all other features?
How dispersed, compact, or integrated are the features?
Are there directional trends?
Parameter
Description
analysis_layer
Required
FeatureLayer. The point, line, or polygon features to be analyzed. See Feature Input.summarize_type
Required list of strings. The method with which to summarize the
analysis_layer.Choice list: [“CentralFeature”, “MeanCenter”, “MedianCenter”, “Ellipse”]
ellipse_size
Optional string. The size of the output ellipse in standard deviations.
Choice list: [‘1 standard deviation’, ‘2 standard deviations’, ‘3 standard deviations’]
The default ellipse size is ‘1 standard deviation’.
weight_field
Optional field. A numeric field in the
analysis_layerto be used to weight locations according to their relative importance.group_field
Optional field. The field used to group features for separate directional distribution calculations. The
group_fieldcan be of integer, date, or string type.output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For summarize_center_and_dispersion, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 11+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
- Returns
list of items if
output_nameis supplied else, a Python dictionary with the following keys:”central_feature_result_layer” : layer (FeatureCollection)”mean_feature_result_layer” : layer (FeatureCollection)”median_feature_result_layer” : layer (FeatureCollection)”ellipse_feature_result_layer” : layer (FeatureCollection)
# USAGE EXAMPLE: To find central features and mean center of earthquake over past months. central_features = summarize_center_and_dispersion(analysis_layer=earthquakes, summarize_type=["CentralFeature","MeanCenter"], ellipse_size='2 standard deviations', weight_field='mag', group_field='magType', output_name='find central features and mean center of earthquake over past months')
summarize_within
-
arcgis.features.analysis.summarize_within(sum_within_layer, summary_layer, sum_shape=True, shape_units=None, summary_fields=[], group_by_field=None, minority_majority=False, percent_shape=False, output_name=None, context=None, gis=None, estimate=False, future=False, bin_type='Square', bin_size=None, bin_size_unit=None) 
The
summarize_withinmethod finds the point, line, or polygon features (or portions of these features) that are within the boundaries of polygons in another layer. For example:Given a layer of watershed boundaries and a layer of land-use boundaries by land-use type, calculate total acreage of land-use type for each watershed.
Given a layer of parcels in a county and a layer of city boundaries, summarize the average value of vacant parcels within each city boundary.
Given a layer of counties and a layer of roads, summarize the total mileage of roads by road type within each county.
You can think of
summarize_withinas taking two layers and stacking them on top of each other. One of the layers, thesum_within_layermust be a polygon layer, and imagine that these polygon boundaries are all colored red. The other layer, thesummary_layer, can be any feature type point, line, or polygon. After stacking these layers on top of each other, you peer down through the stack and count the number of features in thesummary_layerthat fall within the polygons with the red boundaries (thesum_within_layer). Not only can you count the number of features, you can calculate simple statistics about the attributes of the features in thesummary_layer, such as sum, mean, minimum, maximum, and so on.Parameter
Description
sum_within_layer
Required
FeatureLayer. The polygon features. Features, or portions of features, in thesummary_layer(below) that fall within the boundaries of these polygons will be summarized. See Feature Input.summary_layer
Required
FeatureLayer. Point, line, or polygon features that will be summarized for each polygon in thesum_within_layer. See Feature Input.sum_shape
Optional boolean. A boolean value that instructs the task to calculate statistics based on shape type of the
summary_layer, such as the length of lines or areas of polygons of thesummary_layerwithin each polygon insum_within_layer.The default is True.
shape_units
Optional string. Specify units to summarize the length or areas when
sum_shapeis set to true. Units are not required to summarize points.When
summary_layercontains polygons: [‘Acres’, ‘Hectares’, ‘SquareMeters’, ‘SquareKilometers’, ‘SquareMiles’, ‘SquareYards’, ‘SquareFeet’]When
summary_layercontains lines: [‘Meters’, ‘Kilometers’, ‘Feet’, ‘Yards’, ‘Miles’]
summary_fields
Optional list of strings. A list of field names and statistical summary type that you wish to calculate for all features in the
summary_layerthat are within each polygon in thesum_within_layer.Example: [“fieldname1 summary”, “fieldname2 summary”]
group_by_field
Optional string. This is a field of the
summary_layerfeatures that you can use to calculate statistics separately for each unique attribute value. For example, suppose thesum_within_layercontains city boundaries and thesummary_layerfeatures are parcels. One of the fields of the parcels is Status which contains two values: VACANT and OCCUPIED. To calculate the total area of vacant and occupied parcels within the boundaries of cities, use Status as thegroup_by_fieldfield.minority_majority
Optional boolean. This boolean parameter is applicable only when a
group_by_fieldis specified. If true, the minority (least dominant) or the majority (most dominant) attribute values for each group field are calculated. Two new fields are added to theresult_layerprefixed with Majority_ and Minority_.The default is False.
percent_shape
Optional boolean. This Boolean parameter is applicable only when a
group_by_fieldis specified. If set to true, the percentage of each uniquegroup_by_fieldvalue is calculated for eachsum_within_layerpolygon.The default is False.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service. If overwrite is True in context, new layer will overwrite existing layer. If output_name not indicated then newFeatureCollectioncreated.context
Optional dict. Additional settings such as processing extent and output spatial reference. For summarize_within, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+# Example Usage context = {"extent": {"xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{"wkid":102100,"latestWkid":3857}}, "outSR": {"wkid": 3857}, "overwrite": True}
estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean. If True, a future object will be returned and the process will not wait for the task to complete. The default is False, which means wait for results.
bin_type
Required string. The type of bin used to calculate density.
Choice list: [‘Hexagon’, ‘Square’].
bin_size
Required float. The distance for the bins that the
input_layerwill be analyzed using. When generating bins, for Square, the number and units specified determine the height and length of the square. ForHexagon, the number and units specified determine the distance between parallel sides.bin_size_unit
Required string. The distance unit for the bins for which the density will be calculated. The linear unit to be used with the value specified in
bin_size.The default is ‘Meters’.
- Returns
result_layer :
FeatureLayerif output_name is specified, elseFeatureCollectiondictionary.dict with the following keys:
”result_layer” : layer (FeatureCollection)
”group_by_summary” : layer (FeatureCollection)
# USAGE EXAMPLE: To summarize traffic accidents within each county and group them by the day of accident. acc_within_county = summarize_within(sum_within_layer=boundaries, summary_layer=collision_lyr, sum_shape=True, group_by_field='Day', minority_majority=True, percent_shape=True, output_name='summarize accidents within each county', context={"extent":{"xmin":-13160690.837046918,"ymin":4041586.5461609075,"xmax":-13132466.464352652,"ymax":4058001.397985127,"spatialReference":{"wkid":102100,"latestWkid":3857}}})
trace_downstream
-
arcgis.features.analysis.trace_downstream(input_layer, split_distance=None, split_units='Kilometers', max_distance=None, max_distance_units='Kilometers', bounding_polygon_layer=None, source_database=None, generalize=True, output_name=None, context=None, gis=None, estimate=False, future=False) 
The
trace_downstreammethod determines the trace, or flow path, in a downstream direction from the points in your analysis layer.For example, suppose you have point features representing sources of contamination and you want to determine where in your study area the contamination will flow. You can use
trace_downstreamto identify the path the contamination will take. This trace can also be divided into individual line segments by specifying a distance value and units. The line being returned can be the total length of the flow path, a specified maximum trace length, or clipped to area features such as your study area. In many cases, if the total length of the trace path is returned, it will be from the source all the way to the ocean.Parameter
Description
input_layer
Required feature layer. The point features used for the starting location of a downstream trace. See Feature Input.
split_distance
Optional float. The trace line will be split into multiple lines where each line is of the specified length. The resulting trace will have multiple line segments, each with fields FromDistance and ToDistance.
split_units
Optional string. The units used to specify split distance.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’ ‘Yards’, ‘Miles’].
The default is Kilometers.
max_distance
Optional float. Determines the total length of the line that will be returned. If you provide a bounding_polygon_layer to clip the trace, the result will be clipped to the features in that layer regardless of the distance you enter here.
max_distance_units
Optional string. The units used to specify maximum distance.
Choice list: [‘Meters’, ‘Kilometers’, ‘Feet’ ‘Yards’, ‘Miles’].
The default is ‘Kilometers’.
bounding_polygon_layer
Optional feature layer. A polygon layer specifying the area(s) where you want the trace downstreams to be calculated in. For example, if you only want to calculate the trace downstream with in a county polygon, provide a layer containing the county polygon and the resulting trace lines will be clipped to the county boundary. See Feature Input.
source_database
Optional string. Keyword indicating the data source resolution that will be used in the analysis.
Choice list:
Finest: Finest resolution available at each location from all possible data sources.
30m: The hydrologic source was built from 1 arc second - approximately 30 meter resolution, elevation data.
90m: The hydrologic source was built from 3 arc second - approximately 90 meter resolution, elevation data.
The default is Finest.
generalize
Optional boolean. Determines if the output trace downstream lines will be smoothed into simpler lines or conform to the cell edges of the original DEM.
output_name
Optional string or
FeatureLayer. Existing feature layer will cause the new layer to be appended to the Feature Service.If overwrite is True in context, new layer will overwrite existing layer.
If output_name not indicated then new
FeatureCollectioncreated.
context
Optional dict. Additional settings such as processing extent and output spatial reference. For trace_downstream, there are three settings.
extent- a bounding box that defines the analysis area. Only those features in the input_layer that intersect the bounding box will be analyzed.outSR- the output features will be projected into the output spatial reference referred to by the wkid.overwrite- if True, then the feature layer in output_name will be overwritten with new feature layer. Available for ArcGIS Online or Enterprise 10.9.1+
# Example Usage >>> trace_res = trace_downstream( ... context = { "extent": { "xmin": 3164569.408035, "ymin": -9187921.892449, "xmax": 3174104.927313, "ymax": -9175500.875353, "spatialReference":{ "wkid":102100, "latestWkid":3857 } }, "outSR": {"wkid": 3857}, "overwrite": True} ... )
gis
Optional. The
GISon which this tool runs. If not specified, the active GIS is used.estimate
Optional boolean. If True, the number of credits to run the operation will be returned.
future
Optional boolean.
If True, a future object will be returned that can be queried for results. The process returns control to the user.
If False, the process waits for results until returning control to the user. The default is False.
- Returns
FeatureLayerifoutput_nameis set, elseFeatureCollection.
# USAGE EXAMPLE: To identify the path the water contamination will take. path = trace_downstream(input_layer=water_source_lyr, split_distance=2, split_units='Miles', max_distance=2, max_distance_units='Miles', source_database='Finest', generalize=True, output_name='trace downstream')