GeoJSON is an open standard geospatial data interchange format that represents simple geographic features and their nonspatial attributes. Based on JavaScript Object Notation (JSON), GeoJSON is a format for encoding a variety of geographic data structures. It uses a geographic coordinate reference system, World Geodetic System 1984, and units of decimal degrees. To learn more about GeoJSON, see the GeoJSON specification.
When loading GeoJSON data, a geometry column will be automatically created in the result DataFrame and its spatial
reference set. GeoJSON supports point, line, polygon, and multipart collections of point, line, or polygon geometries. After loading GeoJSON
files into a Spark DataFrame, you can perform analysis and visualize the data by using the SQL functions and tools available
in GeoAnalytics for Microsoft Fabric in addition to functions offered in Spark. Once you save a DataFrame
as GeoJSON, you can store the files or access and visualize them through other systems.
Reading GeoJSON Files in Spark
The following examples demonstrate how to load GeoJSON files into Spark DataFrames using both Python and Scala.
df = spark.read.format("geojson").load("path/to/your/file.geojson")Here are some common options used in reading GeoJSON files:
| DataFrameReader option | Example | Description |
|---|---|---|
sample | .option("sample | Specify the number of records to sample when inferring the schema. |
sampling | .option("sampling | Specify the ratio of records to sample when inferring the schema. It must be a number between 0 and 1. |
merge | .option("merge | Merge the schemas of a collection of GeoJSON datasets in the input directory. |
For a complete list of options that can be used with the JSON data source in Spark, see the Spark documentation.
Reading multiple GeoJSON files
Spark can infer partition columns from directory names that follow the column=value format. For instance, if your GeoJSON
files are organized in subdirectories named District=0, District=2, etc., Spark will recognize district as a
partition column when reading the data. This allows Spark to optimize query performance by reading only the relevant partitions.
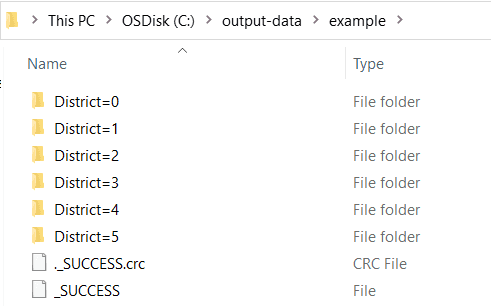
When reading a directory of GeoJSON data with subdirectories not named with column=, Spark won't read from the
subdirectories in bulk. You must add the glob pattern at the end of the root path.
Note that all subdirectories must contain GeoJSON files in order to be read in bulk.
df = spark.read.format("geojson").load("path/to/your/files/*.geojson")Writing DataFrames to GeoJSON
df.write.format("geojson").save("path/to/output/directory")Here are some common options used in writing GeoJSON files:
| DataFrameWriter option | Example | Description |
|---|---|---|
custom | .option("custom | When set to True, geometries will not be automatically transformed to World Geodetic System 1984. The default is False. |
ignore | .option("ignore | Specifies whether to ignore null fields when generating GeoJSON objects. The default is True. |
partition | .partition | Partition the output by the given column name. This example will partition the output GeoJSON files by values in the date column. |
overwrite | .mode("overwrite") | Overwrite existing data in the specified path. Other available options are append, error, and ignore. |
multiline | .option("multiline", True) | Writes the GeoJSON in multiline format. |
By default, GeoJSON uses World Geodetic System 1984 (SRID:4326) and decimal degrees when saving the DataFrame. If the DataFrame geometry is
in a different spatial reference, it will be automatically transformed into World Geodetic System 1984. In addition, GeoAnalytics for Microsoft Fabric
supports the option to save the DataFrame with a custom spatial reference using custom. To learn more about spatial
references, see Coordinate systems and transformations.
Usage notes
- GeoJSON doesn't support the generic
geometrydata type. Apoint,multipoint,line, orpolygoncolumn is required when writing to GeoJSON. - Writing to GeoJSON requires exactly one geometry field.
- When loading GeoJSON, if there is no spatial reference defined it will be assumed to be World Geodetic System 1984 (SRID:4326).
- Writing DataFrames to GeoJSON doesn't require a spatial reference to be set on the geometry column. However, it is recommended to always set and check the spatial reference of a DataFrame before writing to GeoJSON if the data is not in World Geodetic System 1984.