Apache Parquet (.parquet) is an open-source type-aware columnar
data storage format that can store nested data in a flat columnar format. Parquet is commonly used in the Apache Spark
and Hadoop ecosystems as it is compatible with large data streaming and processing workflows. Parquet is highly
structured meaning it stores the schema and data type of each column with the data files.
To learn more about Parquet data format, see the Apache Parquet documentation.
To learn more about using Parquet files with Spark SQL, see Spark's documentation on the Parquet data source.
After you load one or more Parquet files as a Spark DataFrame, you can create a geometry column and define its spatial reference using GeoAnalytics for Microsoft Fabric SQL functions. For example, if you had polygons stored as WKT strings you could call ST_PointFromText to create a point column from a string column and set its spatial reference. For more information see Geometry.
After creating the geometry column and defining its spatial reference, you can perform spatial analysis and visualization using the SQL functions and tools available in GeoAnalytics for Microsoft Fabric. You can also export a Spark DataFrame to Parquet files for data storage or export to other systems.
Reading Parquet Files in Spark
The following examples demonstrate how to load Parquet files into Spark DataFrames using both Python and Scala.
# Option 1
df = spark.read.parquet("path/to/your/file.parquet")
# Option 2
df = spark.read.format("parquet").load("path/to/your/file.parquet")Here are some common options used in reading Parquet files -
| DataFrameReader option | Example | Description |
|---|---|---|
recursive | .option("recursive | Recursively look though Parquet files under the given directory. |
merge | .option("merge | Merge the schemas of a collection of Parquet datasets in the input directory. |
path | .option("path | Read in files with the specified name pattern under the given file path. |
For a complete list of options that can be used with the Parquet data source in Spark, see the Spark documentation.
Specifying a Schema
To define the schema explicitly, you can use Struct and Struct in both PySpark and Scala.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True),
StructField("city", StringType(), True)
])
df = spark.read.schema(schema).parquet("path/to/your/file.parquet")Reading multiple Parquet files
Spark can infer partition columns from directory names that follow the column=value format. For instance, if your Parquet
files are organized in subdirectories named District=0, District=2, etc., Spark will recognize district as a
partition column when reading the data. This allows Spark to optimize query performance by reading only the relevant partitions.
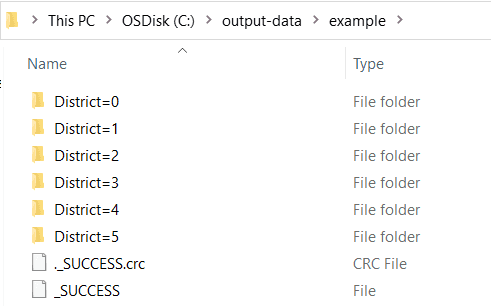
When reading a directory of Parquet data with subdirectories not named with column=, Spark won't read from the
subdirectories in bulk. You must add the glob pattern at the end of the root path.
Note that all subdirectories must contain Parquet files in order to be read in bulk.
df = spark.read.parquet("path/to/your/files/*.parquet")Writing DataFrames to Parquet
# Option 1
df.write.parquet("path/to/output/directory")
# Option 2
df.write.format("parquet").save("path/to/output/directory")Here are some common options used in writing Parquet files in Spark:
| DataFrameWriter option | Example | Description |
|---|---|---|
partition | .partition | Partition the output by the given column name. This example will partition the output Parquet files by values in the date column. |
overwrite | .mode("overwrite") | Overwrite existing data in the specified path. Other available options are append, error, and ignore. |
Usage notes
- The Parquet data source supports loading or saving DataFrames containing one or more geometry columns. These columns may not be understood as geometry columns by other systems that use Parquet.
- Spatial reference info will not be saved with geometry columns written to Parquet files. The spatial reference needs to be manually set on each geometry column when loading Parquet files.
- You can use
.coalesce(1)on the DataFrame to return a new DataFrame that has exactly one partition. Be cautious to use.coalesce(1)on a large dataset. - Consider explicitly saving the spatial reference in the Parquet as a column or in the schema in the geometry column name. To read more on the best practices of working with spatial references in DataFrames, see the documentation on Coordinate Systems and Transformations.
- Be careful when saving to one Parquet file using
.coalesce(1)with large data. Consider partitioning large data by a certain attribute column to read and filter subdirectories of data and to improve performance. - The schema of a nested geometry field may load differently from Parquet files depending on the Spark version.