Introduction
Fully Convolutional Neural Networks (FCNs) are often used for semantic segmentation. One challenge with using FCNs on images for segmentation tasks is that input feature maps become smaller while traversing through the convolutional & pooling layers of the network. This causes loss of information about the images and results in output where predictions are of low resolution and object boundaries are fuzzy.
The DeepLab model addresses this challenge by using Atrous convolutions and Atrous Spatial Pyramid Pooling (ASPP) modules. This architecture has evolved over several generations:
DeepLabV1: Uses Atrous Convolution and Fully Connected Conditional Random Field (CRF) to control the resolution at which image features are computed.
DeepLabV2: Uses Atrous Spatial Pyramid Pooling (ASPP) to consider objects at different scales and segment with much improved accuracy.
DeepLabV3: Apart from using Atrous Convolution, DeepLabV3 uses an improved ASPP module by including batch normalization and image-level features. It gets rid of CRF (Conditional Random Field) as used in V1 and V2.
DeepLabV3 Model Architecture
The DeepLabV3 model has the following architecture:
- Features are extracted from the backbone network (VGG, DenseNet, ResNet).
- To control the size of the feature map, atrous convolution is used in the last few blocks of the backbone.
- On top of extracted features from the backbone, an ASPP network is added to classify each pixel corresponding to their classes.
- The output from the ASPP network is passed through a 1 x 1 convolution to get the actual size of the image which will be the final segmented mask for the image.

Figure 1. DeepLabV3 Model Architecture
These improvements help in extracting dense feature maps for long-range contexts. This increases the receptive field exponentially without reducing/losing the spatial dimension and improves performance on segmentation tasks.
Details on Atrous Convolutions and Atrous Spatial Pyramid Pooling (ASPP) modules are given below.
Atrous Convoltion (Dilated Convolution)
Atrous Convolution is introduced in DeepLab as a tool to adjust/control effective field-of-view of the convolution. It uses a parameter called ‘atrous/dilation rate’ that adjusts field-of-view. It is a simple yet powerful technique to make field of view of filters larger, without impacting computation or number of parameters.
Atrous Convolution is similar to the traditional convolution except the filter is upsampled by inserting zeros between two successive filter values along each spatial dimension. r - 1 zeros are inserted where r is atrous/dilation rate. This is equivalent to creating r − 1 holes between two consecutive filter values in each spatial dimension.
In the diagram below, the filter of size 3 with a dilation rate of 2 is applied to calculate the output. We can visualize filter values are separated by one hole since the dilation rate is 2. If the dilation rate r is 1, it will be Standard convolution.
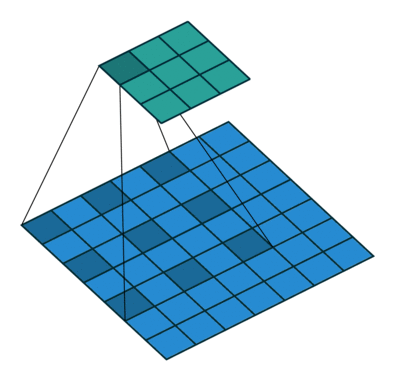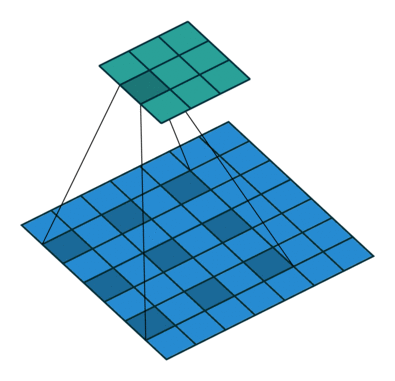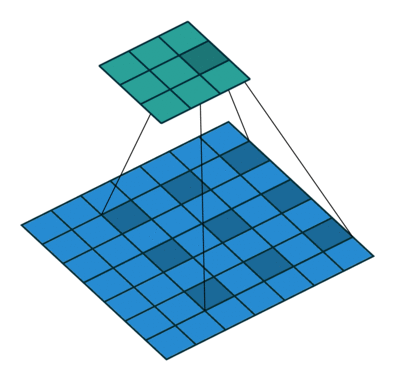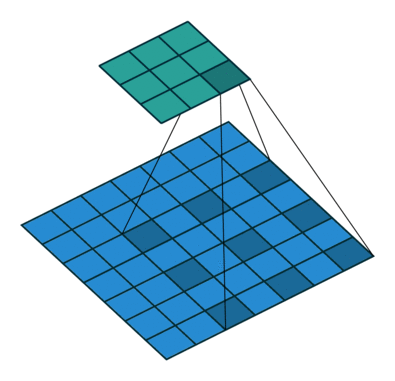
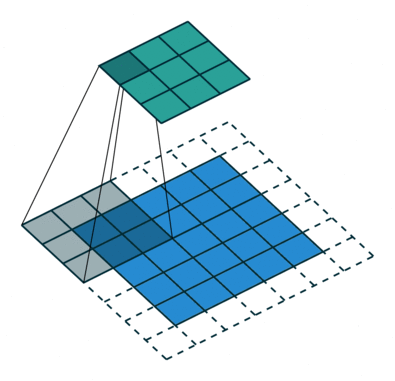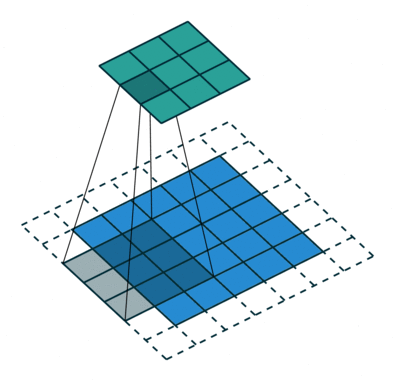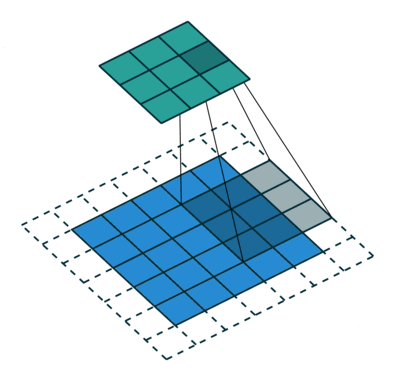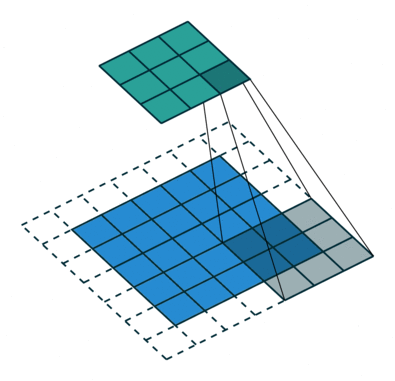
Figure 2. Animation of convolution with
dilation=2 (left)and
dilation=1(right). When dilation=1, it is just the standard convolution operation.

Figure 3. DCNN without Atrous Convolution & with Atrous Convolution
Figure (a) represents DCNN Without Atrous Conv. The network is constructed with standard convolution and pooling operations which make the output feature map smaller after each block operation. This type of network is very useful in capturing long-range information. For example in fig. (a), the final output of block 7 with a very small resolution feature map (256 times smaller than the original image) is summarizing the whole image feature. However, such a smaller resolution feature map is not useful for semantic segmentation tasks that require detailed spatial information.
By using the atrous conv as seen in figure (b), we can preserve spatial resolution and make a deeper network by capturing features at each scale. This is done by increasing dilation rare at each block. As a result, the field of view of the filter becomes wider which is required for better semantic segmentation results.
With a distinct dilation rate r, the filter will have a different field of view. As a result, we can compute the features in fully convolutional networks for multiple scale objects, without reducing the size of feature maps. This is done by applying strided convolution or pooling operation in standard deep convolutional networks.
Note: DeepLabV3 uses atrous convolution with rates 6, 12 & 18.
Atrous Spatial Pyramid Pooling (ASPP)
ASPP is used to obtain multi-scale context information. The prediction results are obtained by up-sampling. In the ASPP network, on top of the feature map extracted from backbone, four parallel atrous convolutions with different atrous rates are applied to handle segmenting the object at different scales. Image-level features are also applied to incorporate global context information by applying global average pooling on the last feature map of the backbone. After applying all the operations parallelly, the results of each operation along the channel is concatenated and 1 x 1 convolution is applied to get the output.
PointRend Enhancement
Segmentation models can tend to generate over-smooth boundaries which might not be precise for objects or scenes with irregular boundaries. To get a crisp segmentation boundary, a point-based rendering neural network module called PointRend has been added as an enhancement to the existing model. This module draws methodology from classical computer graphics and gives the perspective of rendering to a segmentation problem. Image segmentation models often predict labels on a low-resolution regular grid, for example, 1/8th of the input. These models use interpolation to upscale the predictions to original resolution. In contrast, PointRend uses iterative subdivision algorithm to upscale the predictions by predicting labels of points at selected locations by a trained small neural network. This method enables high-resolution output in an efficient way. [8]
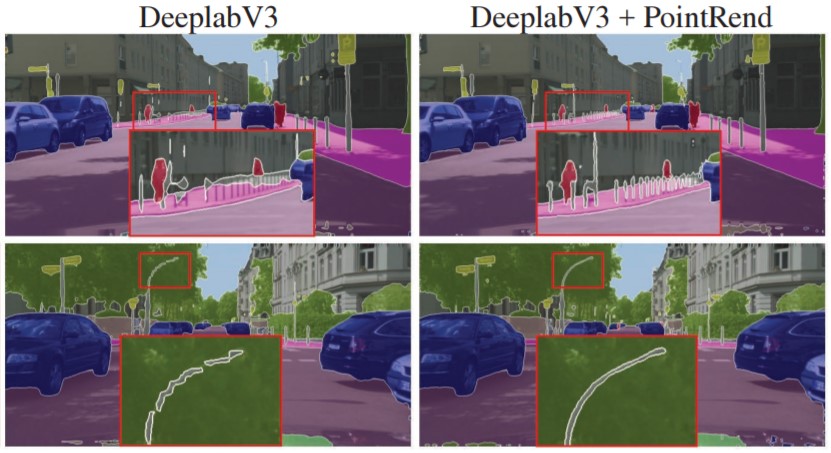
Figure 4. PointRend enhancement (right) over original segmentation model (left) [8]
To enable PointRend with DeepLabV3, initialize the model with parameter pointrend=True:
model = DeepLab(data=data, pointrend=True)
References:
[1] L Chen, G Papandreou, I Kokkinos, K Murphy, A Yuille Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs, arXiv:1412.7062 2016
[2] L Chen, G Papandreou, I Kokkinos, K Murphy, A Yuille DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs arXiv:1606.00915 2017
[3] L Chen, G Papandreou, F Schroff, H Adam Rethinking Atrous Convolution for Semantic Image Segmentation arXiv:1706.05587 2017
[4] Sik-Ho Tsang. Review: DilatedNet — Dilated Convolution (Semantic Segmentation). https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5. Accessed 10 November 2019.
[5] Beeren Sahu, The Evolution of Deeplab for Semantic Segmentation, https://towardsdatascience.com/the-evolution-of-deeplab-for-semantic-segmentation-95082b025571, Accessed 21 Februrary 2020
[6] Sik-Ho Tsang, Review: DeepLabv3 — Atrous Convolution (Semantic Segmentation), https://towardsdatascience.com/review-deeplabv3-atrous-convolution-semantic-segmentation-6d818bfd1d74, Accessed 21 Februrary 2020
[7] Saurabh Pal, Semantic Segmentation: Introduction to the Deep Learning Technique Behind Google Pixel’s Camera!, https://www.analyticsvidhya.com/blog/2019/02/tutorial-semantic-segmentation-google-deeplab/, Accessed 21 February 2020
[8] Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick: “PointRend: Image Segmentation as Rendering”, 2019; [http://arxiv.org/abs/1912.08193 arXiv:1912.08193].