In the "Data Visualization - Construction permits, part 1/2" notebook, we explored your data and learned a little about the spatial and temporal trends of permit activity in Montgomery County. In this lesson, we'll move beyond exploration and run spatial analysis tools to answer specific questions that can't be answered by the data itself. In particular, we want to know why permits spiked in Germantown in 2011 and predict where future permit spikes - and, by extension, future growth - are likely to occur.
First, we'll aggregate the points by ZIP Code. We'll enrich each ZIP Code with demographic information and learn more about the demographic conditions that led to such rapid growth in such a short time. Once you determine why growth occurred where and when it did, we'll locate other ZIP Codes with similar demographic characteristics to predict future growth.
Aggregate points
from datetime import datetime as dt
import pandas as pd
from arcgis.features.enrich_data import enrich_layer
from arcgis.features.summarize_data import aggregate_points
from arcgis.gis import GISgis = GIS("home")permits = gis.content.search(
"Commercial_Permits_since_2010 owner:api_data_owner",
item_type="Feature layer",
outside_org=True)[0]
permits
permits_layer = permits.layers[0]Use authoritative data from Living Atlas to assign a variable to the item.
zip_boundaries = gis.content.search(
"title:'USA ZIP Code Boundaries'",
item_type="Feature layer",
outside_org=True,
)[0]
zip_boundaries
Since the item is a feature layer collection, using the layers property will give us a list of layers.
zip_layer = zip_boundaries.layers[0]Next, you'll use this layer to aggregate permit points. By default, the parameters are set to use the ZIP Codes as the area layer, the permits as the layer to be aggregated, and the layer style to be based on permit count. These parameters are exactly what you want.
permits_agg_by_zip = aggregate_points(
permits_layer,
zip_layer,
keep_boundaries_with_no_points=False,
output_name=f"permits_aggregated_by_zip_{dt.now().strftime('%Y%m%d%H%M%S')}"
)
permits_agg_layer = permits_agg_by_zip.layers[0]{"cost": 43.492}
Aggregation results
map_agg = gis.map("Montgomery County, Maryland")
map_agg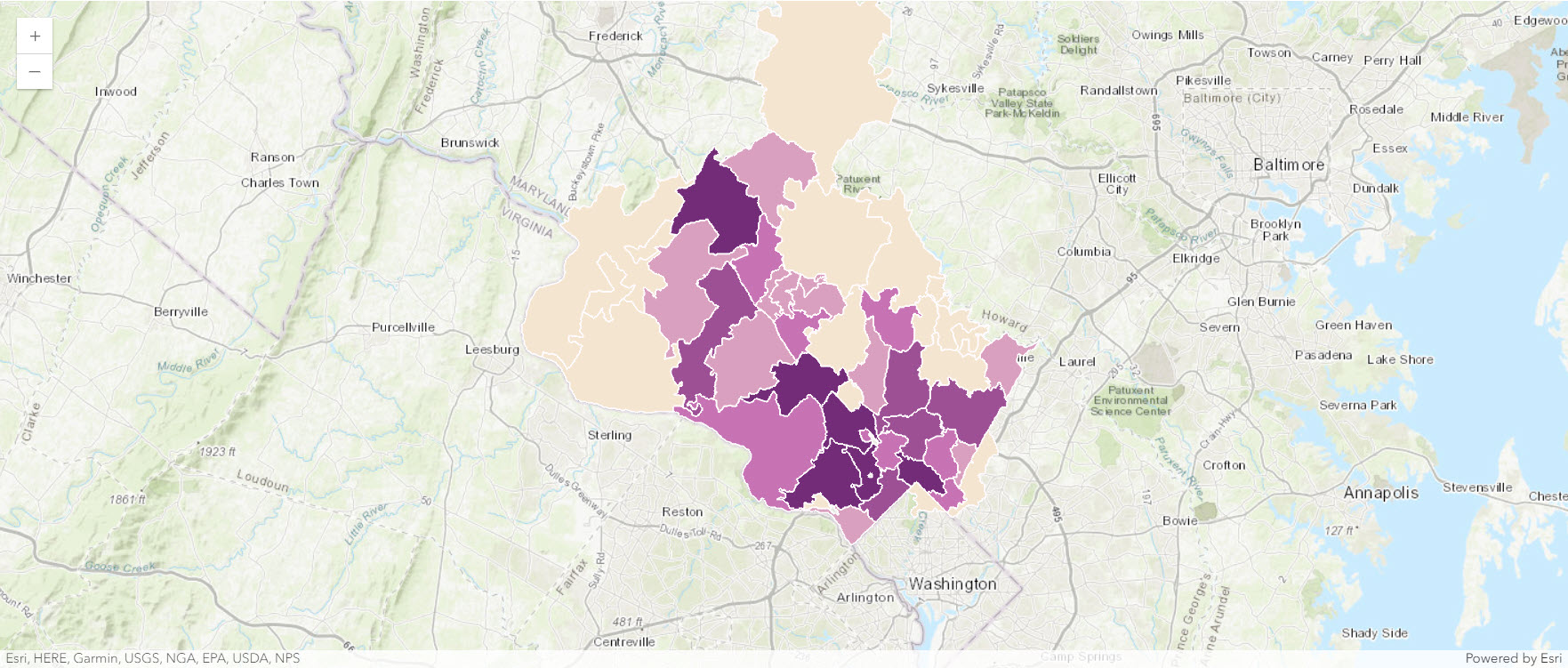
map_agg.content.add(permits_agg_by_zip)The new layer looks like a point layer, but it's actually a polygon layer with a point symbology. Each point represents the number of permits per ZIP Code area. Larger points indicate ZIP Codes with more permits.
permits_agg_sdf = pd.DataFrame.spatial.from_layer(permits_agg_layer)
permits_agg_sdf.columns = [x if x == "SHAPE" else x.lower()
for x in permits_agg_sdf.columns]permits_agg_sdf.head(10)| objectid | zip_code | po_name | state | population | pop_sqmi | sqmi | point_count | analysisarea | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 20012 | Washington | DC | 16069 | 6808.9 | 2.36 | 6 | 2.356958 | {"rings": [[[-8577435.61330738, 4719746.347215... |
| 1 | 2 | 20783 | Hyattsville | MD | 50387 | 8061.92 | 6.25 | 1 | 6.252594 | {"rings": [[[-8571874.52570738, 4716758.150415... |
| 2 | 3 | 20814 | Bethesda | MD | 33669 | 6588.85 | 5.11 | 1143 | 5.109396 | {"rings": [[[-8586356.31200737, 4725395.745915... |
| 3 | 4 | 20815 | Chevy Chase | MD | 30893 | 5774.39 | 5.35 | 584 | 5.354012 | {"rings": [[[-8584098.68600737, 4717919.800115... |
| 4 | 5 | 20816 | Bethesda | MD | 16512 | 3581.78 | 4.61 | 155 | 4.608462 | {"rings": [[[-8591590.85510738, 4717142.631815... |
| 5 | 6 | 20817 | Bethesda | MD | 39114 | 2815.98 | 13.89 | 734 | 13.891985 | {"rings": [[[-8595385.97030737, 4718600.340215... |
| 6 | 7 | 20818 | Cabin John | MD | 1882 | 1920.41 | 0.98 | 13 | 0.980814 | {"rings": [[[-8591561.56690738, 4717346.303815... |
| 7 | 8 | 20832 | Olney | MD | 26083 | 2768.9 | 9.42 | 212 | 9.424987 | {"rings": [[[-8584094.06620738, 4748044.991815... |
| 8 | 9 | 20833 | Brookeville | MD | 7944 | 347.35 | 22.87 | 40 | 22.868169 | {"rings": [[[-8584384.49880738, 4760043.003015... |
| 9 | 10 | 20837 | Poolesville | MD | 6890 | 163.66 | 42.1 | 51 | 42.101676 | {"rings": [[[-8627670.41480738, 4738184.291215... |
Review some basic statistics about the data.
permits_agg_sdf["point_count"].describe()count 45.0 mean 249.422222 std 303.014438 min 1.0 25% 27.0 50% 137.0 75% 316.0 max 1143.0 Name: point_count, dtype: Float64
Although most of the large point symbols on the map are in the southeast corner, near Washington, D.C., there are a few large points in the northwest. In particular, there is a very large circle in the ZIP Code located in Clarksburg. (If you're using different ZIP Code data, this area may be identified as ZIP Code 20871 instead.) The ZIP code has 948 permits. Additionally, this area geographically corresponds to the hot spot you identified in the previous lesson. This ZIP Code is one that you'll focus on when you enrich your layer with demographic data.
Enrich the data
Are there demographic characteristics about the Clarksburg ZIP Code that contributed to its high growth? If so, are there other areas with those characteristics that may experience growth in the future? To answer these questions, you'll use the Enrich Data analysis tool. This tool adds demographic attributes of your choice to your data. Specifically, you'll add Tapestry information to each ZIP Code. Tapestry is a summary of many demographic and socioeconomic variables, including age groups and lifestyle choices. It'll teach you more about the types of people who live in your area of interest and help you better understand the reasons why growth happened where it did.
Note: Organizations should review the data attributions and Master Agreement to make sure they are in compliance when geoenriching data and making it available to other systems.
The analysis variable TSEGNAME is 2022 Dominant Tapestry Segment Name such as Exurbanites, City Lights, Metro Renters, etc. The detailed summary of various segments can be found in here.
zip_enriched = enrich_layer(
permits_agg_layer,
analysis_variables=["AtRisk.TSEGNAME"],
output_name=f"zip_enriched_{dt.now().strftime('%Y%m%d%H%M%S')}"
)
zip_enriched_layer = zip_enriched.layers[0]{"cost": -1}
zip_enriched_sdf = pd.DataFrame.spatial.from_layer(zip_enriched_layer)
zip_enriched_sdf.columns = [x if x == "SHAPE" else x.lower()
for x in zip_enriched_sdf.columns]zip_enriched_sdf.head()| objectid | zip_code | po_name | state | population | pop_sqmi | sqmi | point_count | analysisarea | id | sourcecountry | enrich_fid | aggregationmethod | populationtopolygonsizerating | apportionmentconfidence | hasdata | tsegname | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 20012 | Washington | DC | 16069 | 6808.9 | 2.36 | 6 | 2.356958 | 0 | US | 1 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | City Lights | {"rings": [[[-8577435.6133, 4719746.3472], [-8... |
| 1 | 2 | 20783 | Hyattsville | MD | 50387 | 8061.92 | 6.25 | 1 | 6.252594 | 1 | US | 2 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | NeWest Residents | {"rings": [[[-8571874.5257, 4716758.1504], [-8... |
| 2 | 3 | 20814 | Bethesda | MD | 33669 | 6588.85 | 5.11 | 1143 | 5.109396 | 2 | US | 3 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | Metro Renters | {"rings": [[[-8586356.312, 4725395.7459], [-85... |
| 3 | 4 | 20815 | Chevy Chase | MD | 30893 | 5774.39 | 5.35 | 584 | 5.354012 | 3 | US | 4 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | Top Tier | {"rings": [[[-8584098.686, 4717919.8001], [-85... |
| 4 | 5 | 20816 | Bethesda | MD | 16512 | 3581.78 | 4.61 | 155 | 4.608462 | 4 | US | 5 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | Top Tier | {"rings": [[[-8591590.8551, 4717142.6318], [-8... |
map_enriched = gis.map("Montgomery County, Maryland")
map_enriched
map_enriched.content.add(zip_enriched_layer) # visualizing boundariesmap_enriched.content.add(zip_enriched_layer) # visualizing populationzip_enriched_layer_sm = map_enriched.content.renderer(1).smart_mapping()
zip_enriched_layer_sm.class_breaks_renderer(
break_type="size",
field="population"
)Click some of the ZIP Codes.
The Tapestry segment is displayed when you click a ZIP Code. The Tapestry segments have names such as Enterprising Professionals and Savvy Suburbanites. You can look up more information about each segment, including its specific demographic characteristics, on the Tapestry Segmentation help page.
What Tapestry segment is dominant for the Clarksburg ZIP Code where major growth occurred? Click the Clarksburg ZIP Code to find out. According to the pop-up, Boomburbs is the dominant Tapestry segment for the ZIP Code. Boomburbs have many young professionals with families living in affordable new housing. This description may explain why the area saw such rapid residential growth in 2011. It's possible that other ZIP Codes with similar demographic profiles may experience rapid growth in the near future.
Click the ZIP Code directly southwest of Clarksburg.
This ZIP Code is in Boyds. It also has the Boomburbs Tapestry segment. However, its number of permits has been relatively low since 2010. The county may be able to anticipate a similar spike in permit activity in this area.
Although Tapestry segments are based on several demographic characteristics, you could also perform this analysis with other variables. For instance, you could determine if there is a correlation between high permit activity and high population growth. Is a young population or a high income level a stronger indicator of growth? You can answer these questions and others with the analysis tools at your disposal. For the purposes of this lesson, however, your results are satisfactory.
Share your work
We've analyzed your data and come to a couple conclusions about your data. Next, we'll share your results online. Currently, our result layers are layers that are accessible only to you. Sharing our data will make it easier for county officials to use your data in other ArcGIS applications and communicate key information to the public. In particular, we'll share your work to ArcGIS Online. We'll share your enriched ZIP Codes dataset as feature layers that can be added to any web map.
The layer contains fields for both the count of permits per ZIP Code and the dominant Tapestry segment—basically all of the result data we created in your analysis. We'll only need to share this layer, not the original aggregation layer.
Using the sharing_level property, you can share your work with others.
zip_enriched.sharing.sharing_level = "EVERYONE"In this notebook, we used ArcGIS API for Python to explore and analyze permit data for Montgomery County, Maryland. You answered questions about your data's spatial and temporal trends and located areas of the county with rapid growth. We compared your findings with demographic data, came to conclusions about the possible causes of growth, and even predicted an area that may experience similar growth in the future based on shared demographic characteristics. With ArcGIS API for Python, we can perform a similar workflow on any of your data to better understand what it contains and what questions it can answer.