Introduction
Airbnb properties across cities are a great alternative for travellers to find comparatively cheaper accommodation. It also provides homeowners opportunities to utilize spare or unused rooms as an additional income source. However in recent times the alarming spread of Airbnb properties has become a topic of debate among the public and the city authorities across the world.
Considering the above, a study is carried out in this sample notebook to understand the factors that are fuelling widespread growth in the number of Airbnb listings. These might include location characteristics of concerned neighbourhoods (which in this case, NYC census tracts) and as well as qualitative information about the inhabitants residing in them. The goal is to help city planners deal with the negative externalities of the Airbnb phenomenon (and similar short term rentals) by making informed decision on framing suitable policies.
The primary data is downloaded from the Airbnb website for the city of New York. Other data includes 2019 and 2017 census data using Esri's enrichment services, and various other datasets from the NYCOpenData portal.
Note: We need to install pillow version 9.0.0, seaborn and scikit-learn for this notebook
Necessary Imports
if you have pillow version 9.0.0, seaborn and scikit-learn installed you can skip running the next three cells
pip install pillow==9.0.0pip install seabornpip install scikit-learn%matplotlib inline
import matplotlib.pyplot as plt
from datetime import datetime as dt
import pandas as pd
import numpy as np
from IPython.display import display, HTML
from IPython.core.pylabtools import figsize
import seaborn as sns
# Machine Learning models
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import sklearn.metrics as metrics
from sklearn import preprocessing
# Arcgis api imports
import arcgis
from arcgis.geoenrichment import Country
from arcgis.features import summarize_data
from arcgis.features.enrich_data import enrich_layer
from arcgis.features import use_proximity
from arcgis.gis import GIS
from arcgis.features import summarize_datagis = GIS(profile='your_online_profile')Access the NYC Airbnb and Tracts dataset
Airbnb Data - It contains information about 48,000 Airbnb properties available in New York as of 2019. These include location of the property, its neighbourhood characters and transit facilities available, information about the owner, details of the room including number of bedrooms etc., and rental price per night.
NYC Tracts - It is a polygon shapefile consisting 2167 tracts of New York City, including area of the tracts along with unique id for each tract.
# Accessing NYCTracts
nyc_tract_full = gis.content.search('NYCTractData owner:api_data_owner', 'feature layer')[0]
nyc_tract_full
nyc_tracts_layer = nyc_tract_full.layers[0]# Accessing airbnb NYC
airbnb_nyc2019 = gis.content.search('AnBNYC2019 owner:api_data_owner', 'feature layer')[0]
airbnb_nyc2019
airbnb_layer = airbnb_nyc2019.layers[0]Visualizing dataset
# NYC Tracts
m1 = gis.map('New York City')
m1.add_layer(nyc_tracts_layer)
m1
# NYC Airbnb Properties
m = gis.map('Springfield Gardens, NY')
m.add_layer(airbnb_layer)
m
# extracting the dataframe from the layer and visualize it as a pandas dataframe
pd.set_option('display.max_columns', 110)
sdf_airbnb_layer = pd.DataFrame.spatial.from_layer(airbnb_layer)
sdf_airbnb_layer.head(2)| FID | id | scrape_id | last_scrap | name | summary | space | descriptio | experience | neighborho | notes | transit | access | interactio | house_rule | host_since | host_locat | host_respo | host_res_1 | host_accep | host_is_su | host_neigh | host_listi | host_total | host_has_p | host_ident | street | neighbourh | neighbou_1 | neighbou_2 | city | state | zipcode | market | smart_loca | country_co | country | latitude | longitude | is_locatio | property_t | room_type | accommodat | bathrooms | bedrooms | beds | bed_type | amenities | square_fee | price | weekly_pri | monthly_pr | security_d | cleaning_f | guests_inc | extra_peop | minimum_ni | maximum_ni | minimum_mi | maximum_mi | minimum_ma | maximum_ma | minimum__1 | maximum__1 | calendar_u | has_availa | availabili | availabi_1 | availabi_2 | availabi_3 | calendar_l | number_of_ | number_of1 | first_revi | last_revie | review_sco | review_s_1 | review_s_2 | review_s_3 | review_s_4 | review_s_5 | review_s_6 | requires_l | license | jurisdicti | instant_bo | is_busines | cancellati | require_gu | require__1 | calculated | calculat_1 | calculat_2 | calculat_3 | reviews_pe | airbnb | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 121861 | 20200000000000.0 | 2019-06-03 | Park Slope Apt:, Spacious 2 bedroom | Imagine a quiet, spacious apartment, with beau... | Imagine a quiet, spacious apartment, with beau... | none | No pets, no smoking. The $25/night for each gu... | 2011-05-22 | New York, New York, United States | within a day | 100% | N/A | t | Park Slope | 2 | 2 | t | t | Brooklyn, NY, United States | Brooklyn | Park Slope | Brooklyn | Brooklyn | NY | 11215 | New York | Brooklyn, NY | US | United States | 40.67644 | -73.98082 | t | Apartment | Entire home/apt | 4 | 2.0 | 2 | 2 | Real Bed | {TV,"Cable TV",Internet,Wifi,"Air conditioning... | 1500 | 165.0 | $1,050.00 | $250.00 | $60.00 | 2 | $0.00 | 2 | 730 | 2 | 2 | 730 | 730 | 2.0 | 730.0 | 4 weeks ago | t | 0 | 0 | 0 | 0 | 2019-06-03 | 23 | 0 | 2011-05-29 | 2016-05-02 | 99 | 10 | 10 | 10 | 10 | 10 | 10 | f | f | f | moderate | f | f | 2 | 1 | 1 | 0 | 0.24 | 1 | {'x': -8235507.210868829, 'y': 4964733.1453062... | |||||||||
| 1 | 2 | 123784 | 20200000000000.0 | 2019-06-03 | NYC Studio for Rent in Townhouse | Comfortable, spacious studio in one of the mos... | This is a large studio room with a private bat... | Comfortable, spacious studio in one of the mos... | none | The new restaurants, stores and cafes. Everyth... | 45.00 dollar fee for air-conditioner in the su... | Everything in the studio is for their use. | As much as the guest would like. | no loud music no pets no children $300 dollar... | 2011-05-23 | New York, New York, United States | within an hour | 100% | N/A | f | Harlem | 2 | 2 | t | f | New York, NY, United States | Harlem | Harlem | Manhattan | New York | NY | 10027 | New York | New York, NY | US | United States | 40.80481 | -73.94794 | t | Apartment | Entire home/apt | 3 | 1.0 | 0 | 2 | Real Bed | {TV,"Cable TV",Wifi,"Air conditioning","Paid p... | 0 | 110.0 | $735.00 | $3,200.00 | $500.00 | $60.00 | 1 | $25.00 | 2 | 365 | 2 | 2 | 365 | 365 | 2.0 | 365.0 | 7 months ago | t | 8 | 28 | 43 | 296 | 2019-06-03 | 138 | 42 | 2011-05-30 | 2019-05-17 | 94 | 10 | 9 | 10 | 10 | 10 | 9 | f | t | f | strict_14_with_grace_period | t | t | 2 | 1 | 1 | 0 | 1.41 | 1 | {'x': -8231847.026011546, 'y': 4983593.6741002... |
Aggregating number of Airbnb properties by Tracts for NYC
Number of Airbnb properties per tract is to be estimated using the polygon tract layer and the Airbnb point layer.
The Aggregate Points tool uses area features to summarize a set of point features. The boundaries from the area feature are used to collect the points within each area and use them to calculate statistics. The resulting layer displays the count of points within each area. Here, the polygon tract layer is used as the area feature, and the Airbnb point layer is used as the point feature.
agg_result = summarize_data.aggregate_points(point_layer=airbnb_layer,
polygon_layer=nyc_tracts_layer,
output_name='airbnb_counts'+ str(dt.now().microsecond)){"cost": 50.968}
agg_result
# mapping the aggregated airbnb data with darker areas showing more airbnb properties per tract
aggr_map = gis.map('NY', zoomlevel=10)
aggr_map.add_layer(agg_result,{"renderer":"ClassedColorRenderer", "field_name": "Point_Count"})
aggr_map
airbnb_count_by_tract = agg_result.layers[0]sdf_airbnb_count_by_tract = airbnb_count_by_tract.query().sdfsdf_airbnb_count_by_tract = sdf_airbnb_count_by_tract.sort_values('geoid')
sdf_airbnb_count_by_tract.head()| OBJECTID | statefp | countyfp | tractce | geoid | name | namelsad | mtfcc | funcstat | aland | awater | intptlat | intptlon | Point_Count | AnalysisArea | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2095 | 2096 | 36 | 005 | 000100 | 36005000100 | 1 | Census Tract 1 | G5020 | S | 1579361 | 1125765 | +40.7934921 | -073.8835318 | 0 | 2.705062 | {"rings": [[[-8226256.9418, 4982172.581], [-82... |
| 2059 | 2060 | 36 | 005 | 000200 | 36005000200 | 2 | Census Tract 2 | G5020 | S | 455322 | 926899 | +40.8045733 | -073.8568585 | 0 | 1.382228 | {"rings": [[[-8222638.612, 4985024.3226], [-82... |
| 2067 | 2068 | 36 | 005 | 000400 | 36005000400 | 4 | Census Tract 4 | G5020 | S | 912392 | 602945 | +40.8089152 | -073.8504884 | 15 | 1.515336 | {"rings": [[[-8222012.885, 4985135.2266], [-82... |
| 1668 | 1669 | 36 | 005 | 001600 | 36005001600 | 16 | Census Tract 16 | G5020 | S | 485079 | 0 | +40.8188478 | -073.8580764 | 1 | 0.485076 | {"rings": [[[-8222181.7567, 4986069.1354], [-8... |
| 2127 | 2128 | 36 | 005 | 001900 | 36005001900 | 19 | Census Tract 19 | G5020 | S | 1643654 | 1139660 | +40.8009990 | -073.9093729 | 24 | 2.783331 | {"rings": [[[-8230028.8927, 4984061.5402], [-8... |
Here the Point_Count field from the above aggregated dataframe returns the number of Airbnb properties per tract. This would form the target variable for this problem.
Enriching tracts with demographic data using geoenrichment service from Esri
The feature data is now created using selected demographics information for each tracts. This is accomplished accessing the geoenrichment services from Esri, which consists the latest census data. The entire data repository is first visualized, out of which the relevant variables are finalized from a literature study. These selected variables are searched for adding in the feature set.
# Displaying the various data topic available for geoenrichment for USA in the Esri database
usa = Country.get('US')
type(usa)
usa_data = usa.data_collections
df_usa_data = pd.DataFrame(usa_data)
df_usa_data.head()| analysisVariable | alias | fieldCategory | vintage | |
|---|---|---|---|---|
| dataCollectionID | ||||
| 1yearincrements | 1yearincrements.AGE0_CY | 2023 Population Age <1 | 2023 Age: 1 Year Increments (Esri) | 2023 |
| 1yearincrements | 1yearincrements.AGE1_CY | 2023 Population Age 1 | 2023 Age: 1 Year Increments (Esri) | 2023 |
| 1yearincrements | 1yearincrements.AGE2_CY | 2023 Population Age 2 | 2023 Age: 1 Year Increments (Esri) | 2023 |
| 1yearincrements | 1yearincrements.AGE3_CY | 2023 Population Age 3 | 2023 Age: 1 Year Increments (Esri) | 2023 |
| 1yearincrements | 1yearincrements.AGE4_CY | 2023 Population Age 4 | 2023 Age: 1 Year Increments (Esri) | 2023 |
All the data topics are visualized that are available in the geoenrichment services.
# Filtering the unique topic under dataCollectionID
df_usa_data.reset_index(inplace=True)
list(df_usa_data.dataCollectionID.unique())['1yearincrements', '5yearincrements', 'Age', 'agebyracebysex', 'agebyracebysex2010', 'agebyracebysex2020', 'AgeDependency', 'AtRisk', 'AutomobilesAutomotiveProducts', 'BabyProductsToysGames', 'basicFactsForMobileApps', 'businesses', 'CivicActivitiesPoliticalAffiliation', 'classofworker', 'clothing', 'ClothingShoesAccessories', 'commute', 'crime', 'DaytimePopulation', 'disability', 'disposableincome', 'DniRates', 'education', 'educationalattainment', 'ElectronicsInternet', 'employees', 'EmploymentUnemployment', 'entertainment', 'financial', 'FinancialInsurance', 'food', 'foodstampsSNAP', 'gender', 'Generations', 'GroceryAlcoholicBeverages', 'groupquarters', 'Health', 'healthinsurancecoverage', 'HealthPersonalCare', 'HealthPersonalCareCEX', 'heatingfuel', 'hispanicorigin', 'HistoricalHouseholds', 'HistoricalHousing', 'HistoricalPopulation', 'HomeImprovementGardenLawn', 'homevalue', 'HouseholdGoodsFurnitureAppliances', 'householdincome', 'households', 'householdsbyageofhouseholder', 'HouseholdsByIncome', 'householdsbyraceofhouseholder', 'householdsbysize', 'householdtotals', 'householdtype', 'housingbyageofhouseholder', 'housingbyraceofhouseholder', 'housingbysize', 'housingcosts', 'HousingHousehold', 'housingunittotals', 'incomebyage', 'industry', 'industrybynaicscode', 'industrybysiccode', 'InternetComputerUsage', 'KeyGlobalFacts', 'KeyUSFacts', 'language', 'LeisureActivitiesLifestyle', 'LifeInsurancePensions', 'lifemodegroupsNEW', 'maritalstatustotals', 'MediaMagazinesNewspapers', 'MediaRadioOtherAudio', 'MediaTVViewing', 'miscellaneous', 'networth', 'NonHispanicOrigin', 'occupation', 'OwnerRenter', 'PetsPetProducts', 'PhonesYellowPages', 'Policy', 'population', 'populationtotals', 'presenceofchildren', 'PsychographicsAdvertising', 'PsychographicsFood', 'PsychographicsLifestyle', 'PsychographicsMedia', 'PsychographicsShopping', 'RaceAndEthnicity', 'raceandhispanicorigin', 'restaurants', 'RetailDemandbyNAICS', 'sales', 'schoolenrollment', 'shopping', 'spendingFactsForMobileApps', 'SpendingTotal', 'sports', 'tapestryadultsNEW', 'tapestryhouseholdsNEW', 'TapestryNEW', 'transportation', 'TravelCEX', 'travelMPI', 'unitsinstructure', 'urbanizationgroupsNEW', 'vacant', 'vehiclesavailable', 'veterans', 'Wealth', 'women', 'yearbuilt', 'yearmovedin']
Items can be searched using alias field, for the related analysis variable name -- here as an example a variable with 'Nonprofit' is searched. Out of the these the relevant 'Nonprofit' data is to be selected.
df_usa_data[df_usa_data['alias'].str.contains('Nonprofit')] | dataCollectionID | analysisVariable | alias | fieldCategory | vintage | |
|---|---|---|---|---|---|
| 3840 | classofworker | classofworker.ACSMPRIVNP | 2021 Civ Male 16+:Priv Nonprofit (ACS 5-Yr) | 2017-2021 Class of Worker (ACS) | 2017-2021 |
| 3841 | classofworker | classofworker.MOEMPRIVNP | 2021 Civ Male 16+:Priv Nonprofit MOE (ACS 5-Yr) | 2017-2021 Class of Worker (ACS) | 2017-2021 |
| 3848 | classofworker | classofworker.RELMPRIVNP | 2021 Civ Male 16+:Priv Nonprofit REL (ACS 5-Yr) | 2017-2021 Class of Worker (ACS) | 2017-2021 |
| 3873 | classofworker | classofworker.ACSFPRIVNP | 2021 Civ Female 16+:Priv Nonprofit (ACS 5-Yr) | 2017-2021 Class of Worker (ACS) | 2017-2021 |
| 3874 | classofworker | classofworker.MOEFPRIVNP | 2021 Civ Female 16+:Priv Nonprofit MOE (ACS 5-Yr) | 2017-2021 Class of Worker (ACS) | 2017-2021 |
| 3875 | classofworker | classofworker.RELFPRIVNP | 2021 Civ Female 16+:Priv Nonprofit REL (ACS 5-Yr) | 2017-2021 Class of Worker (ACS) | 2017-2021 |
Adding data using enrichment - At this stage a literature study is undertaken to narrow down the various factors that might impact opening of new Airbnb properties in NYC.
Subsequently these factors are identified from the USA geoenrichment database as shown above. These variable names are then compiled in a dictionary for passing them to the enrichment tool.
enrichment_variables = {'classofworker.ACSCIVEMP': 'Employed Population Age 16+',
'classofworker.ACSMCIVEMP': 'Employed Male Pop Age 16+',
'classofworker.ACSMPRIVNP': 'Male 16+Priv Nonprofit',
'classofworker.ACSMEPRIVP': 'Male 16+:Priv Profit Empl',
'classofworker.ACSMSELFI': 'Male 16+:Priv Profit Self Empl',
'classofworker.ACSMSTGOV': 'Male 16+:State Govt Wrkr',
'classofworker.ACSMFEDGOV': 'Male 16+:Fed Govt Wrkr',
'classofworker.ACSMSELFNI': 'Male 16+:Self-Emp Not Inc',
'classofworker.ACSMUNPDFM': 'Male 16+:Unpaid Family Wrkr',
'classofworker.ACSFCIVEMP': 'Female Pop Age 16+',
'classofworker.ACSFEPRIVP': 'Female 16+:Priv Profit Empl',
'classofworker.ACSFSELFI': 'Female 16+:Priv Profit Self Empl',
'classofworker.ACSFPRIVNP': 'Female 16+:Priv Nonprofit',
'classofworker.ACSFLOCGOV': 'Female 16+:Local Govt Wrkr',
'classofworker.ACSFSTGOV': 'Female 16+:State Govt Wrkr',
'classofworker.ACSFFEDGOV': 'Female 16+:Fed Govt Wrkr',
'classofworker.ACSFSELFNI': 'Female 16+:Self-Emp Not Inc',
'classofworker.ACSFUNPDFM': 'Female 16+:Unpaid Family Wrkr',
'gender.MEDAGE_CY': '2019 Median Age',
'Generations.GENALPHACY': '2019 Generation Alpha Population',
'Generations.GENZ_CY': '2019 Generation Z Population',
'Generations.MILLENN_CY': '2019 Millennial Population',
'Generations.GENX_CY': '2019 Generation X Population',
'Generations.BABYBOOMCY': '2019 Baby Boomer Population',
'Generations.OLDRGENSCY': '2019 Silent & Greatest Generations Population',
'Generations.GENBASE_CY': '2019 Population by Generation Base',
'populationtotals.POPDENS_CY': '2019 Population Density',
'DaytimePopulation.DPOP_CY': '2019 Total Daytime Population',
'raceandhispanicorigin.WHITE_CY': '2019 White Population',
'raceandhispanicorigin.BLACK_CY': '2019 Black Population',
'raceandhispanicorigin.AMERIND_CY': '2019 American Indian Population',
'raceandhispanicorigin.ASIAN_CY': '2019 Asian Population',
'raceandhispanicorigin.PACIFIC_CY': '2019 Pacific Islander Population',
'raceandhispanicorigin.OTHRACE_CY': '2019 Other Race Population',
'raceandhispanicorigin.DIVINDX_CY': '2019 Diversity Index',
'households.ACSHHBPOV': 'HHs: Inc Below Poverty Level',
'households.ACSHHAPOV': 'HHs:Inc at/Above Poverty Level',
'households.ACSFAMHH': 'ACS Family Households',
'businesses.S01_BUS': 'Total Businesses (SIC)',
'businesses.N05_BUS': 'Construction Businesses (NAICS)',
'businesses.N08_BUS': 'Retail Trade Businesses (NAICS)',
'businesses.N21_BUS': 'Transportation/Warehouse Bus (NAICS)',
'ElectronicsInternet.MP09147a_B': 'Own any tablet',
'ElectronicsInternet.MP09148a_B': 'Own any e-reader',
'ElectronicsInternet.MP19001a_B': 'Have access to Internet at home',
'ElectronicsInternet.MP19070a_I': 'Index: Spend 0.5-0.9 hrs online(excl email/IM .',
'ElectronicsInternet.MP19071a_B': 'Spend <0.5 hrs online (excl email/IM time) daily',
'populationtotals.TOTPOP_CY': '2019 Total Population',
'gender.MALES_CY': '2019 Male Population',
'gender.FEMALES_CY': '2019 Female Population',
'industry.EMP_CY': '2019 Employed Civilian Pop 16+',
'industry.UNEMP_CY': '2019 Unemployed Population 16+',
'industry.UNEMPRT_CY': '2019 Unemployment Rate',
'commute.ACSWORKERS': 'ACS Workers Age 16+',
'commute.ACSDRALONE': 'ACS Workers 16+: Drove Alone',
'commute.ACSCARPOOL': 'ACS Workers 16+: Carpooled',
'commute.ACSPUBTRAN': 'ACS Workers 16+: Public Transportation',
'commute.ACSBUS': 'ACS Workers 16+: Bus',
'commute.ACSSTRTCAR': 'ACS Workers 16+: Streetcar',
'commute.ACSSUBWAY': 'ACS Workers 16+: Subway',
'commute.ACSRAILRD': 'ACS Workers 16+: Railroad',
'commute.ACSFERRY': 'ACS Workers 16+: Ferryboat',
'commute.ACSTAXICAB': 'ACS Workers 16+: Taxicab',
'commute.ACSMCYCLE': 'ACS Workers 16+: Motorcycle',
'commute.ACSBICYCLE': 'ACS Workers 16+: Bicycle',
'commute.ACSWALKED': 'ACS Workers 16+: Walked',
'commute.ACSOTHTRAN': 'ACS Workers 16+: Other Means',
'commute.ACSWRKHOME': 'ACS Wrkrs 16+: Worked at Home',
'OwnerRenter.OWNER_CY': '2019 Owner Occupied HUs',
'OwnerRenter.RENTER_CY': '2019 Renter Occupied HUs',
'vacant.VACANT_CY': '2019 Vacant Housing Units',
'homevalue.MEDVAL_CY': '2019 Median Home Value',
'housingunittotals.TOTHU_CY': '2019 Total Housing Units',
'yearbuilt.ACSMEDYBLT': 'ACS Median Year Structure Built: HUs',
'SpendingTotal.X1001_X': '2019 Annual Budget Exp',
'transportation.X6001_X': '2019 Transportation',
'households.ACSTOTHH': 'ACS Total Households',
'DaytimePopulation.DPOPWRK_CY': '2019 Daytime Pop: Workers',
'DaytimePopulation.DPOPRES_CY': '2019 Daytime Pop: Residents',
'DaytimePopulation.DPOPDENSCY': '2019 Daytime Pop Density',
'occupation.OCCPROT_CY': '2019 Occupation: Protective Service',
'occupation.OCCFOOD_CY': '2019 Occupation: Food Preperation',
'occupation.OCCPERS_CY': '2019 Occupation: Personal Care',
'occupation.OCCADMN_CY': '2019 Occupation: Office/Admin',
'occupation.OCCCONS_CY': '2019 Occupation: Construction/Extraction',
'occupation.OCCPROD_CY': '2019 Occupation: Production'
}# Enrichment operation using ArcGIS API for Python
enrichment_variables_df = pd.DataFrame.from_dict(enrichment_variables, orient='index',columns=['Variable Definition'])
enrichment_variables_df.reset_index(level=0, inplace=True)
enrichment_variables_df.columns = ['AnalysisVariable','Variable Definition']
enrichment_variables_df.head()
| AnalysisVariable | Variable Definition | |
|---|---|---|
| 0 | classofworker.ACSCIVEMP | Employed Population Age 16+ |
| 1 | classofworker.ACSMCIVEMP | Employed Male Pop Age 16+ |
| 2 | classofworker.ACSMPRIVNP | Male 16+Priv Nonprofit |
| 3 | classofworker.ACSMEPRIVP | Male 16+:Priv Profit Empl |
| 4 | classofworker.ACSMSELFI | Male 16+:Priv Profit Self Empl |
# Convertng the variables names to list for passing them to the enrichment tool
variable_names = enrichment_variables_df['AnalysisVariable'].tolist()
# checking the firt few values of the list
variable_names[1:5]['classofworker.ACSMCIVEMP', 'classofworker.ACSMPRIVNP', 'classofworker.ACSMEPRIVP', 'classofworker.ACSMSELFI']
# Data Enriching operation
airbnb_count_by_tract_enriched = enrich_layer(airbnb_count_by_tract,
analysis_variables = variable_names,
output_name='airbnb_tract_enrich1'+ str(dt.now().microsecond)){"messageCode": "AO_100047", "message": "Enrichment may not be available for some features."}
{"messageCode": "AO_100288", "message": "Unable to detect the country for one or more features."}
{"messageCode": "AO_100047", "message": "Enrichment may not be available for some features."}
{"messageCode": "AO_100000", "message": "Variables [commute.ACSRAILRD] are not defined for country 'US'."}
{"messageCode": "AO_100000", "message": "Variables [households.ACSFAMHH, households.ACSTOTHH] are not defined for country 'US'."}
{"cost": -1}
# Extracting the resulting enriched dataframe after the geoenrichment method
sdf_airbnb_count_by_tract_enriched = airbnb_count_by_tract_enriched.layers[0].query().sdf# Visualizing the data as a pandas dataframe
print(sdf_airbnb_count_by_tract_enriched.columns)
sdf_airbnb_count_by_tract_enriched_sorted = sdf_airbnb_count_by_tract_enriched.sort_values('geoid')
sdf_airbnb_count_by_tract_enriched_sorted.head()Index(['OBJECTID', 'statefp', 'countyfp', 'tractce', 'geoid', 'name',
'namelsad', 'mtfcc', 'funcstat', 'aland',
...
'DPOPWRK_CY', 'DPOPRES_CY', 'DPOPDENSCY', 'OCCPROT_CY', 'OCCFOOD_CY',
'OCCPERS_CY', 'OCCADMN_CY', 'OCCCONS_CY', 'OCCPROD_CY', 'SHAPE'],
dtype='object', length=106)
| OBJECTID | statefp | countyfp | tractce | geoid | name | namelsad | mtfcc | funcstat | aland | awater | intptlat | intptlon | Point_Count | AnalysisArea | ID | sourceCountry | ENRICH_FID | aggregationMethod | populationToPolygonSizeRating | apportionmentConfidence | HasData | ACSCIVEMP | ACSMCIVEMP | ACSMPRIVNP | ACSMEPRIVP | ACSMSELFI | ACSMSTGOV | ACSMFEDGOV | ACSMSELFNI | ACSMUNPDFM | ACSFCIVEMP | ACSFEPRIVP | ACSFSELFI | ACSFPRIVNP | ACSFLOCGOV | ACSFSTGOV | ACSFFEDGOV | ACSFSELFNI | ACSFUNPDFM | MEDAGE_CY | GENALPHACY | GENZ_CY | MILLENN_CY | GENX_CY | BABYBOOMCY | OLDRGENSCY | GENBASE_CY | POPDENS_CY | DPOP_CY | WHITE_CY | BLACK_CY | AMERIND_CY | ASIAN_CY | PACIFIC_CY | OTHRACE_CY | DIVINDX_CY | ACSHHBPOV | ACSHHAPOV | S01_BUS | N05_BUS | N08_BUS | N21_BUS | MP09147a_B | MP09148a_B | MP19001a_B | MP19070a_I | MP19071a_B | TOTPOP_CY | MALES_CY | FEMALES_CY | EMP_CY | UNEMP_CY | UNEMPRT_CY | ACSWORKERS | ACSDRALONE | ACSCARPOOL | ACSPUBTRAN | ACSBUS | ACSSTRTCAR | ACSSUBWAY | ACSFERRY | ACSTAXICAB | ACSMCYCLE | ACSBICYCLE | ACSWALKED | ACSOTHTRAN | ACSWRKHOME | OWNER_CY | RENTER_CY | VACANT_CY | MEDVAL_CY | TOTHU_CY | ACSMEDYBLT | X1001_X | X6001_X | DPOPWRK_CY | DPOPRES_CY | DPOPDENSCY | OCCPROT_CY | OCCFOOD_CY | OCCPERS_CY | OCCADMN_CY | OCCCONS_CY | OCCPROD_CY | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2095 | 2096 | 36 | 005 | 000100 | 36005000100 | 1 | Census Tract 1 | G5020 | S | 1579361 | 1125765 | +40.7934921 | -073.8835318 | 0 | 2.705062 | 45 | US | 2096 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 34.5 | 0.0 | 698.0 | 1997.0 | 921.0 | 127.0 | 5.0 | 3748.0 | 3588.6 | 663.0 | 629.0 | 2330.0 | 17.0 | 67.0 | 1.0 | 672.0 | 75.2 | 0.0 | 0.0 | 24.0 | 3.0 | 4.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3748.0 | 3407.0 | 341.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 663.0 | 0.0 | 634.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | {"rings": [[[-8226256.9418, 4982172.581], [-82... |
| 2059 | 2060 | 36 | 005 | 000200 | 36005000200 | 2 | Census Tract 2 | G5020 | S | 455322 | 926899 | +40.8045733 | -073.8568585 | 0 | 1.382228 | 9 | US | 2060 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 1664.0 | 1068.0 | 51.0 | 709.0 | 0.0 | 43.0 | 0.0 | 38.0 | 0.0 | 596.0 | 316.0 | 15.0 | 78.0 | 115.0 | 60.0 | 12.0 | 0.0 | 0.0 | 35.8 | 430.0 | 1218.0 | 1245.0 | 913.0 | 823.0 | 168.0 | 4797.0 | 8988.5 | 3210.0 | 438.0 | 1195.0 | 69.0 | 217.0 | 7.0 | 2150.0 | 83.6 | 278.0 | 1114.0 | 42.0 | 2.0 | 2.0 | 5.0 | 2177.0 | 437.0 | 3469.0 | 86.0 | 123.0 | 4797.0 | 2249.0 | 2548.0 | 1834.0 | 192.0 | 9.5 | 1664.0 | 766.0 | 13.0 | 619.0 | 235.0 | 0.0 | 362.0 | 22.0 | 39.0 | 0.0 | 0.0 | 200.0 | 0.0 | 27.0 | 767.0 | 766.0 | 78.0 | 558333.0 | 1611.0 | 1957.0 | 132707872.0 | 13576654.0 | 196.0 | 3014.0 | 6014.9 | 48.0 | 106.0 | 15.0 | 162.0 | 33.0 | 130.0 | {"rings": [[[-8222638.612, 4985024.3226], [-82... |
| 2067 | 2068 | 36 | 005 | 000400 | 36005000400 | 4 | Census Tract 4 | G5020 | S | 912392 | 602945 | +40.8089152 | -073.8504884 | 15 | 1.515336 | 17 | US | 2068 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 3128.0 | 1675.0 | 253.0 | 932.0 | 21.0 | 38.0 | 104.0 | 75.0 | 0.0 | 1453.0 | 804.0 | 37.0 | 276.0 | 281.0 | 16.0 | 39.0 | 0.0 | 0.0 | 35.7 | 506.0 | 1589.0 | 1589.0 | 1226.0 | 945.0 | 166.0 | 6021.0 | 10291.0 | 3758.0 | 641.0 | 1803.0 | 60.0 | 240.0 | 6.0 | 2278.0 | 85.4 | 107.0 | 2092.0 | 57.0 | 3.0 | 9.0 | 3.0 | 2754.0 | 730.0 | 4455.0 | 103.0 | 172.0 | 6021.0 | 2937.0 | 3084.0 | 2807.0 | 120.0 | 4.1 | 3082.0 | 1628.0 | 61.0 | 1077.0 | 250.0 | 0.0 | 776.0 | 33.0 | 0.0 | 0.0 | 0.0 | 130.0 | 64.0 | 122.0 | 1548.0 | 537.0 | 108.0 | 552034.0 | 2193.0 | 2001.0 | 197321413.0 | 20238565.0 | 471.0 | 3287.0 | 6423.1 | 239.0 | 83.0 | 96.0 | 429.0 | 99.0 | 42.0 | {"rings": [[[-8222012.885, 4985135.2266], [-82... |
| 1668 | 1669 | 36 | 005 | 001600 | 36005001600 | 16 | Census Tract 16 | G5020 | S | 485079 | 0 | +40.8188478 | -073.8580764 | 1 | 0.485076 | 18 | US | 1669 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 2513.0 | 959.0 | 31.0 | 620.0 | 29.0 | 0.0 | 18.0 | 20.0 | 0.0 | 1554.0 | 927.0 | 7.0 | 159.0 | 296.0 | 90.0 | 51.0 | 24.0 | 0.0 | 36.6 | 477.0 | 1384.0 | 1313.0 | 996.0 | 997.0 | 350.0 | 5517.0 | 29457.3 | 5334.0 | 497.0 | 2127.0 | 70.0 | 123.0 | 3.0 | 1900.0 | 84.6 | 526.0 | 1661.0 | 57.0 | 0.0 | 7.0 | 2.0 | 2392.0 | 491.0 | 3950.0 | 80.0 | 114.0 | 5517.0 | 2394.0 | 3123.0 | 2087.0 | 183.0 | 8.1 | 2422.0 | 880.0 | 73.0 | 1154.0 | 604.0 | 0.0 | 538.0 | 12.0 | 19.0 | 0.0 | 12.0 | 110.0 | 29.0 | 145.0 | 295.0 | 1712.0 | 103.0 | 650463.0 | 2110.0 | 1973.0 | 117903160.0 | 11830562.0 | 1831.0 | 3503.0 | 28480.2 | 101.0 | 104.0 | 35.0 | 299.0 | 3.0 | 21.0 | {"rings": [[[-8222181.7567, 4986069.1354], [-8... |
| 2127 | 2128 | 36 | 005 | 001900 | 36005001900 | 19 | Census Tract 19 | G5020 | S | 1643654 | 1139660 | +40.8009990 | -073.9093729 | 24 | 2.783331 | 27 | US | 2128 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 1790.0 | 887.0 | 144.0 | 580.0 | 46.0 | 0.0 | 7.0 | 41.0 | 17.0 | 903.0 | 585.0 | 15.0 | 133.0 | 64.0 | 17.0 | 0.0 | 89.0 | 0.0 | 36.1 | 362.0 | 946.0 | 1286.0 | 885.0 | 553.0 | 134.0 | 4166.0 | 3876.6 | 8595.0 | 637.0 | 1656.0 | 62.0 | 67.0 | 5.0 | 1236.0 | 85.8 | 323.0 | 938.0 | 409.0 | 75.0 | 45.0 | 26.0 | 1836.0 | 347.0 | 3093.0 | 80.0 | 94.0 | 4166.0 | 2182.0 | 1984.0 | 2152.0 | 114.0 | 5.0 | 1751.0 | 279.0 | 89.0 | 1054.0 | 142.0 | 14.0 | 898.0 | 0.0 | 16.0 | 0.0 | 21.0 | 75.0 | 35.0 | 182.0 | 118.0 | 1486.0 | 124.0 | 381395.0 | 1728.0 | 1964.0 | 118882651.0 | 12251786.0 | 6516.0 | 2079.0 | 7998.0 | 32.0 | 127.0 | 162.0 | 177.0 | 58.0 | 64.0 | {"rings": [[[-8230028.8927, 4984061.5402], [-8... |
The field name of the enriched dataframe are code words which needs to be elaborated. Hence these are renamed with their actual definition from the variable definition of the list that was first created during selection of the variables.
enrichment_variables_df.head()| AnalysisVariable | Variable Definition | |
|---|---|---|
| 0 | classofworker.ACSCIVEMP | Employed Population Age 16+ |
| 1 | classofworker.ACSMCIVEMP | Employed Male Pop Age 16+ |
| 2 | classofworker.ACSMPRIVNP | Male 16+Priv Nonprofit |
| 3 | classofworker.ACSMEPRIVP | Male 16+:Priv Profit Empl |
| 4 | classofworker.ACSMSELFI | Male 16+:Priv Profit Self Empl |
enrichment_variables_copy = enrichment_variables_df.copy()
enrichment_variables_copy.head(2)| AnalysisVariable | Variable Definition | |
|---|---|---|
| 0 | classofworker.ACSCIVEMP | Employed Population Age 16+ |
| 1 | classofworker.ACSMCIVEMP | Employed Male Pop Age 16+ |
enrichment_variables_copy['AnalysisVariable'] = enrichment_variables_copy.AnalysisVariable.str.split(pat='.', expand=True)[1]
enrichment_variables_copy| AnalysisVariable | Variable Definition | |
|---|---|---|
| 0 | ACSCIVEMP | Employed Population Age 16+ |
| 1 | ACSMCIVEMP | Employed Male Pop Age 16+ |
| 2 | ACSMPRIVNP | Male 16+Priv Nonprofit |
| 3 | ACSMEPRIVP | Male 16+:Priv Profit Empl |
| 4 | ACSMSELFI | Male 16+:Priv Profit Self Empl |
| ... | ... | ... |
| 81 | OCCFOOD_CY | 2019 Occupation: Food Preperation |
| 82 | OCCPERS_CY | 2019 Occupation: Personal Care |
| 83 | OCCADMN_CY | 2019 Occupation: Office/Admin |
| 84 | OCCCONS_CY | 2019 Occupation: Construction/Extraction |
| 85 | OCCPROD_CY | 2019 Occupation: Production |
86 rows × 2 columns
enrichment_variables_copy.set_index("AnalysisVariable", drop=True, inplace=True)
dictionary = enrichment_variables_copy.to_dict()
new_columns = dictionary['Variable Definition']# Field renamed and new dataframe visualized
pd.set_option('display.max_columns', 150)
sdf_airbnb_count_by_tract_enriched_sorted.rename(columns=new_columns, inplace=True)
sdf_airbnb_count_by_tract_enriched_sorted.head()| OBJECTID | statefp | countyfp | tractce | geoid | name | namelsad | mtfcc | funcstat | aland | awater | intptlat | intptlon | Point_Count | AnalysisArea | ID | sourceCountry | ENRICH_FID | aggregationMethod | populationToPolygonSizeRating | apportionmentConfidence | HasData | Employed Population Age 16+ | Employed Male Pop Age 16+ | Male 16+Priv Nonprofit | Male 16+:Priv Profit Empl | Male 16+:Priv Profit Self Empl | Male 16+:State Govt Wrkr | Male 16+:Fed Govt Wrkr | Male 16+:Self-Emp Not Inc | Male 16+:Unpaid Family Wrkr | Female Pop Age 16+ | Female 16+:Priv Profit Empl | Female 16+:Priv Profit Self Empl | Female 16+:Priv Nonprofit | Female 16+:Local Govt Wrkr | Female 16+:State Govt Wrkr | Female 16+:Fed Govt Wrkr | Female 16+:Self-Emp Not Inc | Female 16+:Unpaid Family Wrkr | 2019 Median Age | 2019 Generation Alpha Population | 2019 Generation Z Population | 2019 Millennial Population | 2019 Generation X Population | 2019 Baby Boomer Population | 2019 Silent & Greatest Generations Population | 2019 Population by Generation Base | 2019 Population Density | 2019 Total Daytime Population | 2019 White Population | 2019 Black Population | 2019 American Indian Population | 2019 Asian Population | 2019 Pacific Islander Population | 2019 Other Race Population | 2019 Diversity Index | HHs: Inc Below Poverty Level | HHs:Inc at/Above Poverty Level | Total Businesses (SIC) | Construction Businesses (NAICS) | Retail Trade Businesses (NAICS) | Transportation/Warehouse Bus (NAICS) | Own any tablet | Own any e-reader | Have access to Internet at home | Index: Spend 0.5-0.9 hrs online(excl email/IM . | Spend <0.5 hrs online (excl email/IM time) daily | 2019 Total Population | 2019 Male Population | 2019 Female Population | 2019 Employed Civilian Pop 16+ | 2019 Unemployed Population 16+ | 2019 Unemployment Rate | ACS Workers Age 16+ | ACS Workers 16+: Drove Alone | ACS Workers 16+: Carpooled | ACS Workers 16+: Public Transportation | ACS Workers 16+: Bus | ACS Workers 16+: Streetcar | ACS Workers 16+: Subway | ACS Workers 16+: Ferryboat | ACS Workers 16+: Taxicab | ACS Workers 16+: Motorcycle | ACS Workers 16+: Bicycle | ACS Workers 16+: Walked | ACS Workers 16+: Other Means | ACS Wrkrs 16+: Worked at Home | 2019 Owner Occupied HUs | 2019 Renter Occupied HUs | 2019 Vacant Housing Units | 2019 Median Home Value | 2019 Total Housing Units | ACS Median Year Structure Built: HUs | 2019 Annual Budget Exp | 2019 Transportation | 2019 Daytime Pop: Workers | 2019 Daytime Pop: Residents | 2019 Daytime Pop Density | 2019 Occupation: Protective Service | 2019 Occupation: Food Preperation | 2019 Occupation: Personal Care | 2019 Occupation: Office/Admin | 2019 Occupation: Construction/Extraction | 2019 Occupation: Production | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2095 | 2096 | 36 | 005 | 000100 | 36005000100 | 1 | Census Tract 1 | G5020 | S | 1579361 | 1125765 | +40.7934921 | -073.8835318 | 0 | 2.705062 | 45 | US | 2096 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 34.5 | 0.0 | 698.0 | 1997.0 | 921.0 | 127.0 | 5.0 | 3748.0 | 3588.6 | 663.0 | 629.0 | 2330.0 | 17.0 | 67.0 | 1.0 | 672.0 | 75.2 | 0.0 | 0.0 | 24.0 | 3.0 | 4.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3748.0 | 3407.0 | 341.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 663.0 | 0.0 | 634.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | {"rings": [[[-8226256.9418, 4982172.581], [-82... |
| 2059 | 2060 | 36 | 005 | 000200 | 36005000200 | 2 | Census Tract 2 | G5020 | S | 455322 | 926899 | +40.8045733 | -073.8568585 | 0 | 1.382228 | 9 | US | 2060 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 1664.0 | 1068.0 | 51.0 | 709.0 | 0.0 | 43.0 | 0.0 | 38.0 | 0.0 | 596.0 | 316.0 | 15.0 | 78.0 | 115.0 | 60.0 | 12.0 | 0.0 | 0.0 | 35.8 | 430.0 | 1218.0 | 1245.0 | 913.0 | 823.0 | 168.0 | 4797.0 | 8988.5 | 3210.0 | 438.0 | 1195.0 | 69.0 | 217.0 | 7.0 | 2150.0 | 83.6 | 278.0 | 1114.0 | 42.0 | 2.0 | 2.0 | 5.0 | 2177.0 | 437.0 | 3469.0 | 86.0 | 123.0 | 4797.0 | 2249.0 | 2548.0 | 1834.0 | 192.0 | 9.5 | 1664.0 | 766.0 | 13.0 | 619.0 | 235.0 | 0.0 | 362.0 | 22.0 | 39.0 | 0.0 | 0.0 | 200.0 | 0.0 | 27.0 | 767.0 | 766.0 | 78.0 | 558333.0 | 1611.0 | 1957.0 | 132707872.0 | 13576654.0 | 196.0 | 3014.0 | 6014.9 | 48.0 | 106.0 | 15.0 | 162.0 | 33.0 | 130.0 | {"rings": [[[-8222638.612, 4985024.3226], [-82... |
| 2067 | 2068 | 36 | 005 | 000400 | 36005000400 | 4 | Census Tract 4 | G5020 | S | 912392 | 602945 | +40.8089152 | -073.8504884 | 15 | 1.515336 | 17 | US | 2068 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 3128.0 | 1675.0 | 253.0 | 932.0 | 21.0 | 38.0 | 104.0 | 75.0 | 0.0 | 1453.0 | 804.0 | 37.0 | 276.0 | 281.0 | 16.0 | 39.0 | 0.0 | 0.0 | 35.7 | 506.0 | 1589.0 | 1589.0 | 1226.0 | 945.0 | 166.0 | 6021.0 | 10291.0 | 3758.0 | 641.0 | 1803.0 | 60.0 | 240.0 | 6.0 | 2278.0 | 85.4 | 107.0 | 2092.0 | 57.0 | 3.0 | 9.0 | 3.0 | 2754.0 | 730.0 | 4455.0 | 103.0 | 172.0 | 6021.0 | 2937.0 | 3084.0 | 2807.0 | 120.0 | 4.1 | 3082.0 | 1628.0 | 61.0 | 1077.0 | 250.0 | 0.0 | 776.0 | 33.0 | 0.0 | 0.0 | 0.0 | 130.0 | 64.0 | 122.0 | 1548.0 | 537.0 | 108.0 | 552034.0 | 2193.0 | 2001.0 | 197321413.0 | 20238565.0 | 471.0 | 3287.0 | 6423.1 | 239.0 | 83.0 | 96.0 | 429.0 | 99.0 | 42.0 | {"rings": [[[-8222012.885, 4985135.2266], [-82... |
| 1668 | 1669 | 36 | 005 | 001600 | 36005001600 | 16 | Census Tract 16 | G5020 | S | 485079 | 0 | +40.8188478 | -073.8580764 | 1 | 0.485076 | 18 | US | 1669 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 2513.0 | 959.0 | 31.0 | 620.0 | 29.0 | 0.0 | 18.0 | 20.0 | 0.0 | 1554.0 | 927.0 | 7.0 | 159.0 | 296.0 | 90.0 | 51.0 | 24.0 | 0.0 | 36.6 | 477.0 | 1384.0 | 1313.0 | 996.0 | 997.0 | 350.0 | 5517.0 | 29457.3 | 5334.0 | 497.0 | 2127.0 | 70.0 | 123.0 | 3.0 | 1900.0 | 84.6 | 526.0 | 1661.0 | 57.0 | 0.0 | 7.0 | 2.0 | 2392.0 | 491.0 | 3950.0 | 80.0 | 114.0 | 5517.0 | 2394.0 | 3123.0 | 2087.0 | 183.0 | 8.1 | 2422.0 | 880.0 | 73.0 | 1154.0 | 604.0 | 0.0 | 538.0 | 12.0 | 19.0 | 0.0 | 12.0 | 110.0 | 29.0 | 145.0 | 295.0 | 1712.0 | 103.0 | 650463.0 | 2110.0 | 1973.0 | 117903160.0 | 11830562.0 | 1831.0 | 3503.0 | 28480.2 | 101.0 | 104.0 | 35.0 | 299.0 | 3.0 | 21.0 | {"rings": [[[-8222181.7567, 4986069.1354], [-8... |
| 2127 | 2128 | 36 | 005 | 001900 | 36005001900 | 19 | Census Tract 19 | G5020 | S | 1643654 | 1139660 | +40.8009990 | -073.9093729 | 24 | 2.783331 | 27 | US | 2128 | BlockApportionment:US.BlockGroups;PointsLayer:... | 2.191 | 2.576 | 1 | 1790.0 | 887.0 | 144.0 | 580.0 | 46.0 | 0.0 | 7.0 | 41.0 | 17.0 | 903.0 | 585.0 | 15.0 | 133.0 | 64.0 | 17.0 | 0.0 | 89.0 | 0.0 | 36.1 | 362.0 | 946.0 | 1286.0 | 885.0 | 553.0 | 134.0 | 4166.0 | 3876.6 | 8595.0 | 637.0 | 1656.0 | 62.0 | 67.0 | 5.0 | 1236.0 | 85.8 | 323.0 | 938.0 | 409.0 | 75.0 | 45.0 | 26.0 | 1836.0 | 347.0 | 3093.0 | 80.0 | 94.0 | 4166.0 | 2182.0 | 1984.0 | 2152.0 | 114.0 | 5.0 | 1751.0 | 279.0 | 89.0 | 1054.0 | 142.0 | 14.0 | 898.0 | 0.0 | 16.0 | 0.0 | 21.0 | 75.0 | 35.0 | 182.0 | 118.0 | 1486.0 | 124.0 | 381395.0 | 1728.0 | 1964.0 | 118882651.0 | 12251786.0 | 6516.0 | 2079.0 | 7998.0 | 32.0 | 127.0 | 162.0 | 177.0 | 58.0 | 64.0 | {"rings": [[[-8230028.8927, 4984061.5402], [-8... |
The renamed data frame above is now self explanatory hence more interpretable.
Estimating distances of tracts from various city features
The next set of feature data set will be the distances of each of the tract from various city features. These distance variables accomplishes two important tasks.
First is that they include the spatial components of the Airbnb development phenomenon into the model.
Secondly each Airbnb properties are impacted by unique locational factors. This is reflected from the Airbnb reviews where the most highly rated in demand Airbnb property are located in neighbourhood with good transit accessibility. Hence these are accounted into the model by including the distances of different public transit options from the tracts.
The hypothesis formed here is that tracts located near transit hubs which could be subway station, bus stops, railroad lines, subway routes etc., might attract more Airbnb property. Similarly the central business district which for New York is located at lower Manhattan might also influence Airbnb properties, since this is the city's main business hub. In the following these various distances are estimated using ArcGIS API for Python proximity method.
gis.content.search('NYCBusStop owner:api_data_owner')[]
busi_distr = gis.content.search('BusinessDistricts owner:api_data_owner', 'feature layer')[0]
cbd = gis.content.search('NYCBD owner:api_data_owner', 'feature layer')[0]
bus_stop = gis.content.search('NYCBusStop owner:api_data_owner', 'feature layer')[0]
hotels = gis.content.search('NYCHotels owner:api_data_owner', 'feature layer')[0]
railroad = gis.content.search('NYCRailroad owner:api_data_owner', 'feature layer')[0]
subwy_rt = gis.content.search('NYCSubwayRoutes owner:api_data_owner', 'feature layer')[0]
subwy_stn = gis.content.search('NYCSubwayStation owner:api_data_owner', 'feature layer')[0]# accessing the various city feature shapefile from arcgis portal
busi_distr, cbd, bus_stop, hotels, railroad, subwy_rt, subwy_stn (<Item title:"tract_busi_distrs_dist874392" type:Feature Layer Collection owner:api_data_owner>, <Item title:"NYCBD" type:Feature Layer Collection owner:api_data_owner>, <Item title:"ny_tract_bus_stop_dist452536" type:Feature Layer Collection owner:api_data_owner>, <Item title:"ny_tract_hotel_dist128626" type:Feature Layer Collection owner:api_data_owner>, <Item title:"tract_railroad_dist613260" type:Feature Layer Collection owner:api_data_owner>, <Item title:"ny_tract_subway_routes_dist709262" type:Feature Layer Collection owner:api_data_owner>, <Item title:"ny_tract_subway_station_dist691504" type:Feature Layer Collection owner:api_data_owner>)
bus_stop_lyr = bus_stop.layers[0]
cbd_lyr = cbd.layers[0]
hotels_lyr = hotels.layers[0]
subwy_stn_lyr =subwy_stn.layers[0]
subwy_rt_lyr = subwy_rt.layers[0]
railroad_lyr = railroad.layers[0]
busi_distrs_lyr = busi_distr.layers[0] # Avoid warning for chain operation
pd.set_option('mode.chained_assignment', None)
# Estimating Tract to hotel distances
tract_hotel_dist = use_proximity.find_nearest(nyc_tracts_layer,
hotels_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='ny_tract_hotel_dist1' + str(dt.now().microsecond)){"cost": 2.555}
tract_hotel_dist.layers[<FeatureLayer url:"https://services7.arcgis.com/JEwYeAy2cc8qOe3o/arcgis/rest/services/ny_tract_hotel_dist1396959/FeatureServer/0">, <FeatureLayer url:"https://services7.arcgis.com/JEwYeAy2cc8qOe3o/arcgis/rest/services/ny_tract_hotel_dist1396959/FeatureServer/1">]
tract_hotel_dist_lyr = tract_hotel_dist.layers[1]
sdf_tract_hotel_dist_lyr = pd.DataFrame.spatial.from_layer(tract_hotel_dist_lyr)
sdf_tract_hotel_dist_lyr.head()| From_ID | From_Name | From_aland | From_awater | From_countyfp | From_funcstat | From_geoid | From_intptlat | From_intptlon | From_mtfcc | From_namelsad | From_statefp | From_tractce | NearRank | OBJECTID | SHAPE | To_ACRES | To_ADD_ADDR | To_ADD_CITY | To_ADD_OWNER | To_ADD_POBOX | To_ADD_STATE | To_ADD_ZIP | To_AGDISTCODE | To_AGDISTNAME | To_BLDG_DESC | To_BLDG_STYLE | To_BOOK | To_CALC_ACRES | To_COUNTY | To_CT_NAME | To_CT_SWIS | To_DEPTH | To_DUP_GEO | To_FRONT | To_FUEL_DESC | To_FUEL_TYPE | To_FULL_MV | To_GRID_EAST | To_GRID_NORTH | To_HEAT_DESC | To_HEAT_TYPE | To_ID | To_LAND_AV | To_LOC_STREET | To_LOC_ST_NBR | To_LOC_UNIT | To_LOC_ZIP | To_MAIL_ADDR | To_MAIL_CITY | To_MAIL_STATE | To_MAIL_ZIP | To_MUNI_NAME | To_MUNI_PCLID | To_NAMESOURCE | To_NBR_BEDRM | To_NBR_F_BATH | To_NBR_KITCHN | To_NYS_NAME | To_ORIG_FID | To_OWNER_TYPE | To_PAGE | To_PARCELADDR | To_PO_BOX | To_PRINT_KEY | To_PRMY_OWNER | To_PROP_CLASS | To_ROLL_SECT | To_ROLL_YR | To_SBL | To_SCH_CODE | To_SCH_NAME | To_SEWER_DESC | To_SEWER_TYPE | To_SPATIAL_YR | To_SQFT_LIV | To_SQ_FT | To_SWIS | To_SWISPKID | To_SWISSBLID | To_Shape__Area | To_Shape__Length | To_TOTAL_AV | To_USEDASCODE | To_USEDASDESC | To_UTILITIES | To_UTIL_DESC | To_WATER_DESC | To_WATER_SUPP | To_YR_BLT | Total_Miles | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1332 | 227.03 | 41502 | 0 | 005 | S | 36005022703 | +40.8440198 | -073.9104999 | G5020 | Census Tract 227.03 | 36 | 022703 | 1 | 1 | {"paths": [[[-8227552.1448, 4989516.0602], [-8... | 0.0 | Miscellaneous | H9 | 0 | 0.162924 | Bronx | Bronx | 600100 | 159 | 42 | 0.0 | 1011886.0 | 248352.0 | 237 | 202500.0 | WEBSTER AVENUE | 1930 | 10457 | Bronx | 0 | 0 | 0 | 30 | 8 | 0 | 1930 WEBSTER AVENUE | WEBSTER TREMONT EQUIT | 05 | 2017 | 2030270010 | 09 | 2017 | 19110.0 | 6753.0 | 600100 | 6001002030270010 | 1154.0625 | 166.305662 | 1531800.0 | 1931 | 0.519338 | ||||||||||||||||||||||||||||||||||
| 1 | 501 | 207.01 | 47273 | 0 | 061 | S | 36061020701 | +40.8089775 | -073.9584600 | G5020 | Census Tract 207.01 | 36 | 020701 | 1 | 2 | None | 0.0 | Dormitories | H8 | 0 | 0.237481 | New York | Manhattan | 620100 | 100 | 101 | 0.0 | 995721.0 | 234272.0 | 231 | 389700.0 | AMSTERDAM AVENUE | 1235 | 10027 | Manhattan | 0 | 0 | 0 | 701 | 8 | 0 | 1235 AMSTERDAM AVENUE | BARNARD COLLEGE | 08 | 2017 | 1019630030 | 03 | 2017 | 79036.0 | 10092.0 | 620100 | 6201001019630030 | 1680.277344 | 163.99296 | 6787350.0 | 1968 | 0.0 | ||||||||||||||||||||||||||||||||||
| 2 | 469 | 174.02 | 50730 | 0 | 061 | S | 36061017402 | +40.7968026 | -073.9471624 | G5020 | Census Tract 174.02 | 36 | 017402 | 1 | 3 | None | 0.0 | Dormitories | H8 | 0 | 0.338975 | New York | Manhattan | 620100 | 101 | 142 | 0.0 | 998966.0 | 229316.0 | 273 | 1291050.0 | EAST 110 STREET | 55 | 10029 | Manhattan | 0 | 0 | 0 | 695 | 8 | 0 | 55 EAST 110 STREET | EDWIN GOULD RESIDENCE | 08 | 2017 | 1016160024 | 04 | 2017 | 37570.0 | 14347.0 | 620100 | 6201001016160024 | 2397.410156 | 198.095165 | 3051450.0 | 2004 | 0.0 | ||||||||||||||||||||||||||||||||||
| 3 | 454 | 160.02 | 51422 | 0 | 061 | S | 36061016002 | +40.7878787 | -073.9536853 | G5020 | Census Tract 160.02 | 36 | 016002 | 1 | 4 | None | 0.0 | Dormitories | H8 | 0 | 0.742213 | New York | Manhattan | 620100 | 101 | 305 | 0.0 | 997421.0 | 226355.0 | 366 | 6925950.0 | EAST 98 STREET | 50 | 10029 | Manhattan | 0 | 0 | 0 | 689 | 8 | 0 | 50 EAST 98 STREET | MSMC RESIDENTIAL REAL | 08 | 2017 | 1016030039 | 02 | 2017 | 240000.0 | 30781.0 | 620100 | 6201001016030039 | 5248.046875 | 332.868992 | 8974350.0 | 1984 | 0.0 | ||||||||||||||||||||||||||||||||||
| 4 | 440 | 150.01 | 51643 | 0 | 061 | S | 36061015001 | +40.7801987 | -073.9592834 | G5020 | Census Tract 150.01 | 36 | 015001 | 1 | 5 | {"paths": [[[-8232878.2271, 4979973.2013], [-8... | 0.0 | Transient Occupancy - Midtown Manhattan Area | H3 | 0 | 0.036426 | New York | Manhattan | 620100 | 101 | 26 | 0.0 | 996841.0 | 223341.0 | 29 | 1395000.0 | EAST 87 STREET | 164 | 10128 | Manhattan | 0 | 0 | 0 | 687 | 8 | 0 | 164 EAST 87 STREET | 164 EAST 87TH ST LLC | 05 | 2017 | 1015150045 | 02 | 2017 | 18300.0 | 2571.0 | 620100 | 6201001015150045 | 257.5 | 94.764453 | 4627350.0 | 1930 | 0.139874 |
In the above dataframe the Total_Miles field returns the distances of the tract from hotels in miles. Hence this field is converted into feet and retained. This is then repeated for each of the other distance estimation.
# Final hotel Distances in feet — Here in each row column "hotel_dist" returns the distance of the nearest hotel from that tract indicated by its geoids.
# For example in the first row the tract with ID 36005000100 has a nearest hotel at 5571.75 feet away from it.
sdf_tract_hotel_dist_lyr_new = sdf_tract_hotel_dist_lyr[['From_geoid', 'Total_Miles']]
# 1 mile = 5280 feet
sdf_tract_hotel_dist_lyr_new['hotel_dist'] = round(sdf_tract_hotel_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_hotel_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | hotel_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 1.055256 | 5571.75 |
| 2059 | 36005000200 | 1.039099 | 5486.44 |
| 2067 | 36005000400 | 0.472664 | 2495.67 |
| 1668 | 36005001600 | 0.585977 | 3093.96 |
| 2127 | 36005001900 | 0.0 | 0.0 |
# Estimating Busstop distances from tracts
tract_bustop_dist = use_proximity.find_nearest(nyc_tracts_layer,
bus_stop_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='ny_tract_bus_stop_dist'+ str(dt.now().microsecond))
tract_bustop_dist_lyr = tract_bustop_dist.layers[1]
sdf_tract_bustop_dist_lyr =tract_bustop_dist_lyr.query().sdf{"cost": 3.846}
sdf_tract_bustop_dist_lyr| OBJECTID | From_ID | To_ID | NearRank | From_statefp | From_countyfp | From_tractce | From_geoid | From_Name | From_namelsad | From_mtfcc | From_funcstat | From_aland | From_awater | From_intptlat | From_intptlon | To_CounDist | To_BoroCD | To_AssemDist | To_the_geom | To_CongDist | To_StSenDist | To_SHELTER_ID | To_LOCATION | To_AT_BETWEEN | To_LONGITUDE | To_LATITUDE | To_AssetID | To_BoroCode | To_BoroName | To_Street | To_SegmentID | To_PhysicalID | To_NODEID | To_ORIG_FID | Total_Miles | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1332 | 1049 | 1 | 36 | 005 | 022703 | 36005022703 | 227.03 | Census Tract 227.03 | G5020 | S | 41502 | 0 | +40.8440198 | -073.9104999 | 16 | 204 | 77 | POINT (-73.91154799999998 40.84352500000006) | 15 | 33 | BX0293 | Grand Concourse | MT EDEN AV EAST | -73.911548 | 40.843525 | 966 | 2 | Bronx | GRAND CONCOURSE | 190988 | 166310 | 0 | 1969 | 0.0 | None |
| 1 | 2 | 501 | 35 | 1 | 36 | 061 | 020701 | 36061020701 | 207.01 | Census Tract 207.01 | G5020 | S | 47273 | 0 | +40.8089775 | -073.9584600 | 7 | 109 | 70 | POINT (-73.95978799999995 40.80835700000006) | 10 | 30 | MN0273 | AMSTERDAM AV | W 118 ST | -73.959788 | 40.808357 | 2049 | 1 | Manhattan | AMSTERDAM AVENUE | 38361 | 3837 | 0 | 49 | 0.0 | None |
| 2 | 3 | 469 | 413 | 1 | 36 | 061 | 017402 | 36061017402 | 174.02 | Census Tract 174.02 | G5020 | S | 50730 | 0 | +40.7968026 | -073.9471624 | 8 | 111 | 68 | POINT (-73.94691999999998 40.796970000000044) | 13 | 30 | MN01334 | MADISON AV | E 111 ST | -73.94692 | 40.79697 | 1783 | 1 | Manhattan | MADISON AVENUE | 37970 | 3538 | 0 | 784 | 0.0 | None |
| 3 | 4 | 454 | 108 | 1 | 36 | 061 | 016002 | 36061016002 | 160.02 | Census Tract 160.02 | G5020 | S | 51422 | 0 | +40.7878787 | -073.9536853 | 4 | 111 | 68 | POINT (-73.95376199999998 40.787168000000065) | 12 | 29 | MN0868 | E 96 ST | MADISON AV | -73.953762 | 40.787168 | 2201 | 1 | Manhattan | EAST 96 STREET | 294131 | 172107 | 9045175 | 201 | 0.0 | None |
| 4 | 5 | 440 | 398 | 1 | 36 | 061 | 015001 | 36061015001 | 150.01 | Census Tract 150.01 | G5020 | S | 51643 | 0 | +40.7801987 | -073.9592834 | 5 | 108 | 76 | POINT (-73.95346799999999 40.779304000000025) | 12 | 28 | MN01271 | 3 AV | E 87 ST | -73.953468 | 40.779304 | 1739 | 1 | Manhattan | 3 AVENUE | 37669 | 3682 | 23647 | 740 | 0.204742 | {"paths": [[[-8232878.2271, 4979973.2013], [-8... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2162 | 2163 | 2037 | 1653 | 1 | 36 | 081 | 071600 | 36081071600 | 716 | Census Tract 716 | G5020 | S | 18242414 | 1117802 | +40.6476943 | -073.7860589 | 31 | 413 | 31 | POINT (-73.77444099999997 40.660487000000046) | 5 | 10 | QN04677 | ROCKAWAY BLVD | 147 AV | -73.774441 | 40.660487 | 2913 | 4 | Queens | ROCKAWAY BOULEVARD | 59422 | 8417 | 0 | 3341 | 0.035317 | {"paths": [[[-8212568.4035, 4962325.3532], [-8... |
| 2163 | 2164 | 287 | 973 | 1 | 36 | 047 | 990100 | 36047990100 | 9901 | Census Tract 9901 | G5020 | S | 0 | 17793513 | +40.5649933 | -074.0148865 | 43 | 311 | 46 | POINT (-73.99949999999995 40.595282000000054) | 11 | 23 | BR0471 | SHORE PKWY | BAY PKWY | -73.9995 | 40.595282 | 845 | 3 | Brooklyn | SHORE PARKWAY | 9009667 | 167800 | 0 | 1847 | 0.33537 | {"paths": [[[-8238249.5277, 4952568.7722], [-8... |
| 2164 | 2165 | 2145 | 238 | 1 | 36 | 081 | 107202 | 36081107202 | 1072.02 | Census Tract 1072.02 | G5020 | S | 7504745 | 16636750 | +40.6252538 | -073.8137646 | 32 | 414 | 23 | POINT (-73.82648099999994 40.58301400000005) | 5 | 15 | QN04053 | ROCKAWAY BEACH BLVD | BEACH 105 ST | -73.826481 | 40.583014 | 2390 | 4 | Queens | ROCKAWAY BEACH BOULEVARD | 147266 | 14870 | 0 | 390 | 0.332147 | {"paths": [[[-8218474.4488, 4951720.8592], [-8... |
| 2165 | 2166 | 691 | 1445 | 1 | 36 | 085 | 990100 | 36085990100 | 9901 | Census Tract 9901 | G5020 | S | 0 | 80255169 | +40.5255512 | -074.1085829 | 50 | 595 | 64 | POINT (-74.07749299999995 40.57932000000005) | 11 | 24 | SI05038 | FR CAPODANNO BLVD | SEAVIEW AV | -74.077493 | 40.57932 | 3280 | 5 | Staten Island | FR CAPODANNO BOULEVARD | 145481 | 44856 | 92770 | 2780 | 0.433019 | {"paths": [[[-8245592.2067, 4949864.8834], [-8... |
| 2166 | 2167 | 581 | 1620 | 1 | 36 | 081 | 990100 | 36081990100 | 9901 | Census Tract 9901 | G5020 | S | 0 | 122602887 | +40.5401732 | -073.8909698 | 32 | 414 | 23 | POINT (-73.86499899999995 40.56884100000008) | 5 | 15 | QN04568 | ROCKAWAY BEACH BLVD | BEACH 149 ST | -73.864999 | 40.568841 | 2820 | 4 | Queens | ROCKAWAY BEACH BOULEVARD | 114195 | 15135 | 0 | 3248 | 0.54502 | {"paths": [[[-8222119.6803, 4947903.8282], [-8... |
2167 rows × 37 columns
# Final Bustop Distances in feet — Here in each row column "busstop_dist" returns the distance of the nearest bus stop
# from that tract indicated by its geoids
sdf_tract_bustop_dist_lyr_new = sdf_tract_bustop_dist_lyr[['From_geoid', 'Total_Miles']]
sdf_tract_bustop_dist_lyr_new['busstop_dist'] = round(sdf_tract_bustop_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_bustop_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | busstop_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 0.744344 | 3930.14 |
| 2059 | 36005000200 | 0.005983 | 31.59 |
| 2067 | 36005000400 | 0.0 | 0.0 |
| 1668 | 36005001600 | 0.0 | 0.0 |
| 2127 | 36005001900 | 0.0 | 0.0 |
# estimating number of bus stops per tract
num_bustops_tracts = summarize_data.aggregate_points(point_layer=bus_stop_lyr,
polygon_layer=nyc_tracts_layer,
output_name='bustops_by_tracts'+ str(dt.now().microsecond)) {"cost": 3.846}
num_bustops_tracts_lyr = num_bustops_tracts.layers[0]
sdf_num_bustops_tracts_lyr = pd.DataFrame.spatial.from_layer(num_bustops_tracts_lyr)
sdf_num_bustops_tracts_lyr.head()| AnalysisArea | OBJECTID | Point_Count | SHAPE | aland | awater | countyfp | funcstat | geoid | intptlat | intptlon | mtfcc | name | namelsad | statefp | tractce | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.016024 | 1 | 1 | {"rings": [[[-8227813.3004, 4989345.3624], [-8... | 41502 | 0 | 005 | S | 36005022703 | +40.8440198 | -073.9104999 | G5020 | 227.03 | Census Tract 227.03 | 36 | 022703 |
| 1 | 0.018252 | 2 | 1 | {"rings": [[[-8233183.0202, 4984115.3687], [-8... | 47273 | 0 | 061 | S | 36061020701 | +40.8089775 | -073.9584600 | G5020 | 207.01 | Census Tract 207.01 | 36 | 020701 |
| 2 | 0.019587 | 3 | 1 | {"rings": [[[-8231989.6748, 4982433.1457], [-8... | 50730 | 0 | 061 | S | 36061017402 | +40.7968026 | -073.9471624 | G5020 | 174.02 | Census Tract 174.02 | 36 | 017402 |
| 3 | 0.019854 | 4 | 1 | {"rings": [[[-8232691.8783, 4981159.0609], [-8... | 51422 | 0 | 061 | S | 36061016002 | +40.7878787 | -073.9536853 | G5020 | 160.02 | Census Tract 160.02 | 36 | 016002 |
| 4 | 0.019939 | 5 | 0 | {"rings": [[[-8233292.0018, 4980071.8459], [-8... | 51643 | 0 | 061 | S | 36061015001 | +40.7801987 | -073.9592834 | G5020 | 150.01 | Census Tract 150.01 | 36 | 015001 |
# Number of Bus stops per tract — Here in each row column "num_bustop" returns the number of bus stops inside respective tracts
sdf_num_bustops_tracts_lyr_new = sdf_num_bustops_tracts_lyr[['geoid', 'Point_Count']]
sdf_num_bustops_tracts_lyr_new = sdf_num_bustops_tracts_lyr_new.rename(columns={'Point_Count':'num_bustop'})
sdf_num_bustops_tracts_lyr_new.sort_values('geoid').head()| geoid | num_bustop | |
|---|---|---|
| 2095 | 36005000100 | 0 |
| 2059 | 36005000200 | 0 |
| 2067 | 36005000400 | 1 |
| 1668 | 36005001600 | 1 |
| 2127 | 36005001900 | 1 |
# estimating tracts distances from CBD
tract_cbd_dist=use_proximity.find_nearest(nyc_tracts_layer,
cbd_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='ny_tract_cbd_dist'+ str(dt.now().microsecond))
tract_cbd_dist_lyr = tract_cbd_dist.layers[1]
sdf_tract_cbd_dist_lyr = tract_cbd_dist_lyr.query().sdf
sdf_tract_cbd_dist_lyr.head(){"cost": 2.168}
| OBJECTID | From_ID | To_ID | NearRank | From_statefp | From_countyfp | From_tractce | From_geoid | From_Name | From_namelsad | From_mtfcc | From_funcstat | From_aland | From_awater | From_intptlat | From_intptlon | To_bid | To_borough | To_date_creat | To_time_creat | To_date_modif | To_time_modif | To_objectid | To_shape_area | To_shape_len | Total_Miles | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1332 | 1 | 1 | 36 | 005 | 022703 | 36005022703 | 227.03 | Census Tract 227.03 | G5020 | S | 41502 | 0 | +40.8440198 | -073.9104999 | Bryant Park BID | Manhattan | 2008-11-19 | 00:00:00.000 | 2016-10-31 | 00:00:00.000 | 58.0 | 1225783.27084 | 5837.603557 | 7.102363 | {"paths": [[[-8227840.685, 4989242.9453], [-82... |
| 1 | 2 | 501 | 1 | 1 | 36 | 061 | 020701 | 36061020701 | 207.01 | Census Tract 207.01 | G5020 | S | 47273 | 0 | +40.8089775 | -073.9584600 | Bryant Park BID | Manhattan | 2008-11-19 | 00:00:00.000 | 2016-10-31 | 00:00:00.000 | 58.0 | 1225783.27084 | 5837.603557 | 3.809966 | {"paths": [[[-8233012.3673, 4983978.5918], [-8... |
| 2 | 3 | 469 | 1 | 1 | 36 | 061 | 017402 | 36061017402 | 174.02 | Census Tract 174.02 | G5020 | S | 50730 | 0 | +40.7968026 | -073.9471624 | Bryant Park BID | Manhattan | 2008-11-19 | 00:00:00.000 | 2016-10-31 | 00:00:00.000 | 58.0 | 1225783.27084 | 5837.603557 | 3.363737 | {"paths": [[[-8231927.236, 4982389.3817], [-82... |
| 3 | 4 | 454 | 1 | 1 | 36 | 061 | 016002 | 36061016002 | 160.02 | Census Tract 160.02 | G5020 | S | 51422 | 0 | +40.7878787 | -073.9536853 | Bryant Park BID | Manhattan | 2008-11-19 | 00:00:00.000 | 2016-10-31 | 00:00:00.000 | 58.0 | 1225783.27084 | 5837.603557 | 2.658677 | {"paths": [[[-8232719.7081, 4981110.3946], [-8... |
| 4 | 5 | 440 | 1 | 1 | 36 | 061 | 015001 | 36061015001 | 150.01 | Census Tract 150.01 | G5020 | S | 51643 | 0 | +40.7801987 | -073.9592834 | Bryant Park BID | Manhattan | 2008-11-19 | 00:00:00.000 | 2016-10-31 | 00:00:00.000 | 58.0 | 1225783.27084 | 5837.603557 | 2.055165 | {"paths": [[[-8233341.205, 4979982.316], [-823... |
# Final CBD distances in feet — Here in each row the column "cbd_dst" returns the distance of the CBD from respective tracts
sdf_tract_cbd_dist_lyr_new = sdf_tract_cbd_dist_lyr[['From_geoid', 'Total_Miles']]
sdf_tract_cbd_dist_lyr_new['cbd_dist'] = round(sdf_tract_cbd_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_cbd_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | cbd_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 4.999247 | 26396.02 |
| 2059 | 36005000200 | 6.858514 | 36212.95 |
| 2067 | 36005000400 | 7.321927 | 38659.77 |
| 1668 | 36005001600 | 7.525535 | 39734.83 |
| 2127 | 36005001900 | 4.33359 | 22881.35 |
# Estimating NYCSubwayStation distances from tracts
tract_subwy_stn_dist = use_proximity.find_nearest(nyc_tracts_layer,
subwy_stn_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='ny_tract_subway_station_dist'+ str(dt.now().microsecond))
tract_subwy_stn_dist_lyr = tract_subwy_stn_dist.layers[1]
sdf_tract_subwy_stn_dist_lyr = pd.DataFrame.spatial.from_layer(tract_subwy_stn_dist_lyr)
sdf_tract_subwy_stn_dist_lyr.head(){"cost": 2.599}
| From_ID | From_Name | From_aland | From_awater | From_countyfp | From_funcstat | From_geoid | From_intptlat | From_intptlon | From_mtfcc | From_namelsad | From_statefp | From_tractce | NearRank | OBJECTID | SHAPE | To_ID | To_Name | To_ORIG_FID | To_line | To_notes | To_objectid | To_url | Total_Miles | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1332 | 227.03 | 41502 | 0 | 005 | S | 36005022703 | +40.8440198 | -073.9104999 | G5020 | Census Tract 227.03 | 36 | 022703 | 1 | 1 | {"paths": [[[-8227646.1872, 4989522.1588], [-8... | 21 | 174th-175th Sts | 21 | B-D | B-rush hours, D-all times, skips rush hours AM... | 21.0 | http://web.mta.info/nyct/service/ | 0.054525 |
| 1 | 501 | 207.01 | 47273 | 0 | 061 | S | 36061020701 | +40.8089775 | -073.9584600 | G5020 | Census Tract 207.01 | 36 | 020701 | 1 | 2 | {"paths": [[[-8233201.4992, 4984081.6891], [-8... | 159 | 116th St - Columbia University | 167 | 1 | 1-all times | 167.0 | http://web.mta.info/nyct/service/ | 0.211254 |
| 2 | 469 | 174.02 | 50730 | 0 | 061 | S | 36061017402 | +40.7968026 | -073.9471624 | G5020 | Census Tract 174.02 | 36 | 017402 | 1 | 3 | {"paths": [[[-8231617.2328, 4982254.7552], [-8... | 413 | 110th St | 450 | 4-6-6 Express | 4 nights, 6-all times, 6 Express-weekdays AM s... | 450.0 | http://web.mta.info/nyct/service/ | 0.09727 |
| 3 | 454 | 160.02 | 51422 | 0 | 061 | S | 36061016002 | +40.7878787 | -073.9536853 | G5020 | Census Tract 160.02 | 36 | 016002 | 1 | 4 | {"paths": [[[-8232360.48, 4980909.7037], [-823... | 33 | 96th St | 33 | 4-6-6 Express | 4 nights, 6-all times, 6 Express-weekdays AM s... | 33.0 | http://web.mta.info/nyct/service/ | 0.098659 |
| 4 | 440 | 150.01 | 51643 | 0 | 061 | S | 36061015001 | +40.7801987 | -073.9592834 | G5020 | Census Tract 150.01 | 36 | 015001 | 1 | 5 | {"paths": [[[-8232878.9945, 4979971.8169], [-8... | 414 | 86th St | 451 | 4-5-6-6 Express | 4,6-all times, 5-all times exc nights, 6 Expre... | 451.0 | http://web.mta.info/nyct/service/ | 0.09711 |
# Final Tract to NYC Subway Station distances in feet — Here in each row, column "subwy_stn_dist" returns the distance of
# the nearest subway station from that tract
sdf_tract_subwy_stn_dist_lyr_new = sdf_tract_subwy_stn_dist_lyr[['From_geoid', 'Total_Miles']]
sdf_tract_subwy_stn_dist_lyr_new['subwy_stn_dist'] = round(sdf_tract_subwy_stn_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_subwy_stn_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | subwy_stn_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 0.946226 | 4996.07 |
| 2059 | 36005000200 | 1.108173 | 5851.15 |
| 2067 | 36005000400 | 1.191505 | 6291.15 |
| 1668 | 36005001600 | 0.729661 | 3852.61 |
| 2127 | 36005001900 | 0.080063 | 422.73 |
# Estimating distances to NYCSubwayRoutes
tract_subwy_rt_dist=use_proximity.find_nearest(nyc_tracts_layer,
subwy_rt_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='ny_tract_subway_routes_dist'+ str(dt.now().microsecond))
tract_subwy_rt_dist_lyr = tract_subwy_rt_dist.layers[1]
sdf_tract_subwy_rt_dist_lyr = tract_subwy_rt_dist_lyr.query().sdf
sdf_tract_subwy_rt_dist_lyr.head(){"cost": 2.191}
| OBJECTID | From_ID | To_ID | NearRank | From_statefp | From_countyfp | From_tractce | From_geoid | From_Name | From_namelsad | From_mtfcc | From_funcstat | From_aland | From_awater | From_intptlat | From_intptlon | To_route_id | To_route_shor | To_route_long | To_group_ | To_Shape__Length | To_ORIG_FID | Total_Miles | SHAPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1332 | 19 | 1 | 36 | 005 | 022703 | 36005022703 | 227.03 | Census Tract 227.03 | G5020 | S | 41502 | 0 | +40.8440198 | -073.9104999 | B | B | 6 Avenue Express | BDFM | 51293.284426 | 12 | 0.0 | None |
| 1 | 2 | 501 | 9 | 1 | 36 | 061 | 020701 | 36061020701 | 207.01 | Census Tract 207.01 | G5020 | S | 47273 | 0 | +40.8089775 | -073.9584600 | 1 | 1 | Broadway - 7 Avenue Local | 123 | 31208.137831 | 3 | 0.169658 | {"paths": [[[-8233150.5149, 4984174.9334], [-8... |
| 2 | 3 | 469 | 10 | 1 | 36 | 061 | 017402 | 36061017402 | 174.02 | Census Tract 174.02 | G5020 | S | 50730 | 0 | +40.7968026 | -073.9471624 | 6 | 6 | Lexington Avenue Express/Local | 456 | 31863.545339 | 9 | 0.09692 | {"paths": [[[-8231635.9013, 4982220.9583], [-8... |
| 3 | 4 | 454 | 10 | 1 | 36 | 061 | 016002 | 36061016002 | 160.02 | Census Tract 160.02 | G5020 | S | 51422 | 0 | +40.7878787 | -073.9536853 | 6 | 6 | Lexington Avenue Express/Local | 456 | 31863.545339 | 9 | 0.096942 | {"paths": [[[-8232305.5995, 4981008.652], [-82... |
| 4 | 5 | 440 | 10 | 1 | 36 | 061 | 015001 | 36061015001 | 150.01 | Census Tract 150.01 | G5020 | S | 51643 | 0 | +40.7801987 | -073.9592834 | 6 | 6 | Lexington Avenue Express/Local | 456 | 31863.545339 | 9 | 0.096767 | {"paths": [[[-8232878.2271, 4979973.2013], [-8... |
# Final Tract to NYCSubwayRoutes distances in feet — Here in each row, column "subwy_rt_dist" returns the distance of
# the nearest subway route from that tract
sdf_tract_subwy_rt_dist_lyr_new = sdf_tract_subwy_rt_dist_lyr[['From_geoid', 'Total_Miles']]
sdf_tract_subwy_rt_dist_lyr_new['subwy_rt_dist'] = round(sdf_tract_subwy_rt_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_subwy_rt_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | subwy_rt_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 0.90531 | 4780.04 |
| 2059 | 36005000200 | 1.108726 | 5854.07 |
| 2067 | 36005000400 | 1.192022 | 6293.88 |
| 1668 | 36005001600 | 0.724321 | 3824.42 |
| 2127 | 36005001900 | 0.002853 | 15.06 |
# Estimating distances to NYCRailroad
tract_railroad_dist = use_proximity.find_nearest(nyc_tracts_layer,
railroad_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='tract_railroad_dist'+ str(dt.now().microsecond))
tract_railroad_dist_lyr = tract_railroad_dist.layers[1]
sdf_tract_railroad_dist_lyr = pd.DataFrame.spatial.from_layer(tract_railroad_dist_lyr)
sdf_tract_railroad_dist_lyr.head(){"cost": 2.168}
| From_ID | From_Name | From_aland | From_awater | From_countyfp | From_funcstat | From_geoid | From_intptlat | From_intptlon | From_mtfcc | From_namelsad | From_statefp | From_tractce | NearRank | OBJECTID | SHAPE | To_ID | To_Id_Orig | To_ORIG_FID | To_Shape__Length | Total_Miles | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1332 | 227.03 | 41502 | 0 | 005 | S | 36005022703 | +40.8440198 | -073.9104999 | G5020 | Census Tract 227.03 | 36 | 022703 | 1 | 1 | {"paths": [[[-8227770.665, 4989475.2983], [-82... | 1 | 0 | 1 | 2194198.77038 | 0.140554 |
| 1 | 501 | 207.01 | 47273 | 0 | 061 | S | 36061020701 | +40.8089775 | -073.9584600 | G5020 | Census Tract 207.01 | 36 | 020701 | 1 | 2 | {"paths": [[[-8232997.3392, 4984450.7008], [-8... | 1 | 0 | 1 | 2194198.77038 | 0.166535 |
| 2 | 469 | 174.02 | 50730 | 0 | 061 | S | 36061017402 | +40.7968026 | -073.9471624 | G5020 | Census Tract 174.02 | 36 | 017402 | 1 | 3 | None | 1 | 0 | 1 | 2194198.77038 | 0.0 |
| 3 | 454 | 160.02 | 51422 | 0 | 061 | S | 36061016002 | +40.7878787 | -073.9536853 | G5020 | Census Tract 160.02 | 36 | 016002 | 1 | 4 | None | 1 | 0 | 1 | 2194198.77038 | 0.0 |
| 4 | 440 | 150.01 | 51643 | 0 | 061 | S | 36061015001 | +40.7801987 | -073.9592834 | G5020 | Census Tract 150.01 | 36 | 015001 | 1 | 5 | {"paths": [[[-8232883.8965, 4979976.3551], [-8... | 1 | 0 | 1 | 2194198.77038 | 0.559931 |
# Final Tract to NYCRailroad distances in feet — Here in each row, column "railroad_dist" returns the distance of
# the nearest rail road route from that tract
sdf_tract_railroad_dist_lyr_new = sdf_tract_railroad_dist_lyr[['From_geoid', 'Total_Miles']]
sdf_tract_railroad_dist_lyr_new['railroad_dist'] = round(sdf_tract_railroad_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_railroad_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | railroad_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 0.403054 | 2128.12 |
| 2059 | 36005000200 | 0.215395 | 1137.29 |
| 2067 | 36005000400 | 0.708551 | 3741.15 |
| 1668 | 36005001600 | 0.614506 | 3244.59 |
| 2127 | 36005001900 | 0.0 | 0.0 |
# Estimating distances to NYC Business Districts
tract_busi_distrs_dist = use_proximity.find_nearest(nyc_tracts_layer,
busi_distrs_lyr,
measurement_type='StraightLine',
max_count=1,
output_name='tract_busi_distrs_dist'+ str(dt.now().microsecond))
tract_busi_distrs_dist_lyr = tract_busi_distrs_dist.layers[1]
sdf_tract_busi_distrs_dist_lyr = pd.DataFrame.spatial.from_layer(tract_busi_distrs_dist_lyr)
sdf_tract_busi_distrs_dist_lyr.head(){"cost": 2.241}
| From_ID | From_Name | From_aland | From_awater | From_countyfp | From_funcstat | From_geoid | From_intptlat | From_intptlon | From_mtfcc | From_namelsad | From_statefp | From_tractce | NearRank | OBJECTID | SHAPE | To_ID | To_ORIG_FID | To_Shape__Area | To_Shape__Length | To_bid | To_borough | To_date_creat | To_date_modif | To_objectid | To_time_creat | To_time_modif | Total_Miles | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1332 | 227.03 | 41502 | 0 | 005 | S | 36005022703 | +40.8440198 | -073.9104999 | G5020 | Census Tract 227.03 | 36 | 022703 | 1 | 1 | {"paths": [[[-8227809.0396, 4989358.3475], [-8... | 15 | 14 | 180282.226562 | 3281.5747 | Washington Heights BID | Manhattan | 2008-11-19 | 2016-10-25 | 69.0 | 00:00:00.000 | 00:00:00.000 | 1.034897 |
| 1 | 501 | 207.01 | 47273 | 0 | 061 | S | 36061020701 | +40.8089775 | -073.9584600 | G5020 | Census Tract 207.01 | 36 | 020701 | 1 | 2 | {"paths": [[[-8232865.8707, 4984369.9553], [-8... | 29 | 16 | 269468.507812 | 4849.117421 | 125th Street BID | Manhattan | 2008-11-19 | 2016-10-25 | 67.0 | 00:00:00.000 | 00:00:00.000 | 0.159359 |
| 2 | 469 | 174.02 | 50730 | 0 | 061 | S | 36061017402 | +40.7968026 | -073.9471624 | G5020 | Census Tract 174.02 | 36 | 017402 | 1 | 3 | {"paths": [[[-8231888.4853, 4982612.3984], [-8... | 29 | 16 | 269468.507812 | 4849.117421 | 125th Street BID | Manhattan | 2008-11-19 | 2016-10-25 | 67.0 | 00:00:00.000 | 00:00:00.000 | 0.604451 |
| 3 | 454 | 160.02 | 51422 | 0 | 061 | S | 36061016002 | +40.7878787 | -073.9536853 | G5020 | Census Tract 160.02 | 36 | 016002 | 1 | 4 | {"paths": [[[-8232539.9271, 4981009.3871], [-8... | 65 | 70 | 409639.414062 | 8507.99606 | Madison Avenue BID | Manhattan | 2008-11-19 | 2016-10-26 | 64.0 | 00:00:00.000 | 00:00:00.000 | 0.502002 |
| 4 | 440 | 150.01 | 51643 | 0 | 061 | S | 36061015001 | +40.7801987 | -073.9592834 | G5020 | Census Tract 150.01 | 36 | 015001 | 1 | 5 | None | 65 | 70 | 409639.414062 | 8507.99606 | Madison Avenue BID | Manhattan | 2008-11-19 | 2016-10-26 | 64.0 | 00:00:00.000 | 00:00:00.000 | 0.0 |
# Final Tract to NYC Businesss Districts distances in feet — Here in each row, column "busi_distr_dist" returns the distance of the CBD from respective tracts
sdf_tract_busi_distrs_dist_lyr_new = sdf_tract_busi_distrs_dist_lyr[['From_geoid', 'Total_Miles']]
sdf_tract_busi_distrs_dist_lyr_new['busi_distr_dist'] = round(sdf_tract_busi_distrs_dist_lyr_new['Total_Miles'] * 5280, 2)
sdf_tract_busi_distrs_dist_lyr_new.sort_values('From_geoid').head()| From_geoid | Total_Miles | busi_distr_dist | |
|---|---|---|---|
| 2095 | 36005000100 | 1.308636 | 6909.6 |
| 2059 | 36005000200 | 1.292505 | 6824.43 |
| 2067 | 36005000400 | 1.596395 | 8428.97 |
| 1668 | 36005001600 | 1.23762 | 6534.63 |
| 2127 | 36005001900 | 0.510611 | 2696.02 |
Importing Borough Info for each Tracts
# Name of the borough, inside which the tracts are located
ny_tract_boro = gis.content.search('NYCTractBorough owner:api_data_owner', 'feature layer')[0]
ny_tract_boro_lyr = ny_tract_boro.layers[0]
sdf_ny_tract_boro_lyr = pd.DataFrame.spatial.from_layer(ny_tract_boro_lyr)
sdf_ny_tract_boro_lyr_new = sdf_ny_tract_boro_lyr[['geoid', 'boro_name']]
sdf_ny_tract_boro_lyr_new.sort_values('geoid').head()| geoid | boro_name | |
|---|---|---|
| 0 | 36005000100 | Bronx |
| 2 | 36005000200 | Bronx |
| 5 | 36005000400 | Bronx |
| 7 | 36005001600 | Bronx |
| 9 | 36005001900 | Bronx |
Merging all the above estimated data set of features
tract_merge_dist = sdf_tract_hotel_dist_lyr_new.merge(sdf_tract_subwy_rt_dist_lyr_new,
on='From_geoid', suffixes=('_left1', '_right1')).merge(sdf_tract_railroad_dist_lyr_new,
on='From_geoid', suffixes=('_left2', '_right2')).merge(sdf_tract_subwy_stn_dist_lyr_new,
on='From_geoid', suffixes=('_left3', '_right3')).merge(sdf_tract_busi_distrs_dist_lyr_new,
on='From_geoid', suffixes=('_left4', '_right4')).merge(sdf_tract_cbd_dist_lyr_new, on='From_geoid')
tract_merge_dist_new = tract_merge_dist[['From_geoid',
'hotel_dist',
'subwy_rt_dist',
'railroad_dist',
'subwy_stn_dist',
'busi_distr_dist',
'cbd_dist']]
tract_merge_dist_new = tract_merge_dist_new.rename(columns={'From_geoid':'geoid'})
tract_merge_dist_new.sort_values('geoid').head()| geoid | hotel_dist | subwy_rt_dist | railroad_dist | subwy_stn_dist | busi_distr_dist | cbd_dist | |
|---|---|---|---|---|---|---|---|
| 2095 | 36005000100 | 5571.75 | 4780.04 | 2128.12 | 4996.07 | 6909.6 | 26396.02 |
| 2059 | 36005000200 | 5486.44 | 5854.07 | 1137.29 | 5851.15 | 6824.43 | 36212.95 |
| 2067 | 36005000400 | 2495.67 | 6293.88 | 3741.15 | 6291.15 | 8428.97 | 38659.77 |
| 1668 | 36005001600 | 3093.96 | 3824.42 | 3244.59 | 3852.61 | 6534.63 | 39734.83 |
| 2127 | 36005001900 | 0.0 | 15.06 | 0.0 | 422.73 | 2696.02 | 22881.35 |
# merging number of bus stop and borough name
tract_merge_dist_new = tract_merge_dist_new.merge(sdf_num_bustops_tracts_lyr_new,
on='geoid').merge(sdf_ny_tract_boro_lyr_new,
on='geoid')
tract_merge_dist_new = tract_merge_dist_new.sort_values('geoid')
tract_merge_dist_new.head()| geoid | hotel_dist | subwy_rt_dist | railroad_dist | subwy_stn_dist | busi_distr_dist | cbd_dist | num_bustop | boro_name | |
|---|---|---|---|---|---|---|---|---|---|
| 2095 | 36005000100 | 5571.75 | 4780.04 | 2128.12 | 4996.07 | 6909.6 | 26396.02 | 0 | Bronx |
| 2059 | 36005000200 | 5486.44 | 5854.07 | 1137.29 | 5851.15 | 6824.43 | 36212.95 | 0 | Bronx |
| 2067 | 36005000400 | 2495.67 | 6293.88 | 3741.15 | 6291.15 | 8428.97 | 38659.77 | 1 | Bronx |
| 1668 | 36005001600 | 3093.96 | 3824.42 | 3244.59 | 3852.61 | 6534.63 | 39734.83 | 1 | Bronx |
| 2127 | 36005001900 | 0.0 | 15.06 | 0.0 | 422.73 | 2696.02 | 22881.35 | 1 | Bronx |
# Accessing the airbnb count for each tract
sdf_airbnb_count_by_tract_new = sdf_airbnb_count_by_tract[['geoid','Point_Count']]
sdf_airbnb_count_by_tract_new = sdf_airbnb_count_by_tract_new.rename(columns={'Point_Count':'total_airbnb'})
sdf_airbnb_count_by_tract_new.head()| geoid | total_airbnb | |
|---|---|---|
| 2095 | 36005000100 | 0 |
| 2059 | 36005000200 | 0 |
| 2067 | 36005000400 | 15 |
| 1668 | 36005001600 | 1 |
| 2127 | 36005001900 | 24 |
# preparing the final distance table with airbnb count by tract
tract_merge_dist_all = sdf_airbnb_count_by_tract_new.merge(tract_merge_dist_new, on='geoid')
tract_merge_dist_all.head()| geoid | total_airbnb | hotel_dist | subwy_rt_dist | railroad_dist | subwy_stn_dist | busi_distr_dist | cbd_dist | num_bustop | boro_name | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 36005000100 | 0 | 5571.75 | 4780.04 | 2128.12 | 4996.07 | 6909.6 | 26396.02 | 0 | Bronx |
| 1 | 36005000200 | 0 | 5486.44 | 5854.07 | 1137.29 | 5851.15 | 6824.43 | 36212.95 | 0 | Bronx |
| 2 | 36005000400 | 15 | 2495.67 | 6293.88 | 3741.15 | 6291.15 | 8428.97 | 38659.77 | 1 | Bronx |
| 3 | 36005001600 | 1 | 3093.96 | 3824.42 | 3244.59 | 3852.61 | 6534.63 | 39734.83 | 1 | Bronx |
| 4 | 36005001900 | 24 | 0.0 | 15.06 | 0.0 | 422.73 | 2696.02 | 22881.35 | 1 | Bronx |
tract_merge_dist_all.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 2167 entries, 0 to 2166 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 geoid 2167 non-null string 1 total_airbnb 2167 non-null Int32 2 hotel_dist 2167 non-null Float64 3 subwy_rt_dist 2167 non-null Float64 4 railroad_dist 2167 non-null Float64 5 subwy_stn_dist 2167 non-null Float64 6 busi_distr_dist 2167 non-null Float64 7 cbd_dist 2167 non-null Float64 8 num_bustop 2167 non-null Int32 9 boro_name 2167 non-null string dtypes: Float64(6), Int32(2), string(2) memory usage: 169.4 KB
Borough column being an important location indicator is converted into numerical variable and inlcuded in the feature data
tract_merge_dist_final = pd.get_dummies(tract_merge_dist_all, columns=['boro_name'])
tract_merge_dist_final.head()| geoid | total_airbnb | hotel_dist | subwy_rt_dist | railroad_dist | subwy_stn_dist | busi_distr_dist | cbd_dist | num_bustop | boro_name_Bronx | boro_name_Brooklyn | boro_name_Manhattan | boro_name_Queens | boro_name_Staten Island | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 36005000100 | 0 | 5571.75 | 4780.04 | 2128.12 | 4996.07 | 6909.6 | 26396.02 | 0 | True | False | False | False | False |
| 1 | 36005000200 | 0 | 5486.44 | 5854.07 | 1137.29 | 5851.15 | 6824.43 | 36212.95 | 0 | True | False | False | False | False |
| 2 | 36005000400 | 15 | 2495.67 | 6293.88 | 3741.15 | 6291.15 | 8428.97 | 38659.77 | 1 | True | False | False | False | False |
| 3 | 36005001600 | 1 | 3093.96 | 3824.42 | 3244.59 | 3852.61 | 6534.63 | 39734.83 | 1 | True | False | False | False | False |
| 4 | 36005001900 | 24 | 0.0 | 15.06 | 0.0 | 422.73 | 2696.02 | 22881.35 | 1 | True | False | False | False | False |
Adding census data 2019 obtained using geoenrichment
The above distance data set is now added with the census data to form the final feature set for the model
sdf_airbnb_count_by_tract_enriched_sorted_new = sdf_airbnb_count_by_tract_enriched_sorted.drop(['AnalysisArea',
'ENRICH_FID',
'HasData',
'ID',
'OBJECTID',
'Point_Count',
'SHAPE',
'aggregationMethod',
'aland',
'apportionmentConfidence',
'awater',
'countyfp',
'funcstat',
'intptlat',
'intptlon',
'mtfcc',
'name',
'namelsad',
'populationToPolygonSizeRating',
'sourceCountry',
'statefp','tractce'], axis=1)
sdf_airbnb_count_by_tract_enriched_sorted_new.shape(2167, 84)
# checking the rows of the table for nan values
row_with_null = sdf_airbnb_count_by_tract_enriched_sorted_new.isnull().any(axis=1)
# printing the row which has nan values
sdf_airbnb_count_by_tract_enriched_sorted_new[row_with_null]| geoid | Employed Population Age 16+ | Employed Male Pop Age 16+ | Male 16+Priv Nonprofit | Male 16+:Priv Profit Empl | Male 16+:Priv Profit Self Empl | Male 16+:State Govt Wrkr | Male 16+:Fed Govt Wrkr | Male 16+:Self-Emp Not Inc | Male 16+:Unpaid Family Wrkr | Female Pop Age 16+ | Female 16+:Priv Profit Empl | Female 16+:Priv Profit Self Empl | Female 16+:Priv Nonprofit | Female 16+:Local Govt Wrkr | Female 16+:State Govt Wrkr | Female 16+:Fed Govt Wrkr | Female 16+:Self-Emp Not Inc | Female 16+:Unpaid Family Wrkr | 2019 Median Age | 2019 Generation Alpha Population | 2019 Generation Z Population | 2019 Millennial Population | 2019 Generation X Population | 2019 Baby Boomer Population | 2019 Silent & Greatest Generations Population | 2019 Population by Generation Base | 2019 Population Density | 2019 Total Daytime Population | 2019 White Population | 2019 Black Population | 2019 American Indian Population | 2019 Asian Population | 2019 Pacific Islander Population | 2019 Other Race Population | 2019 Diversity Index | HHs: Inc Below Poverty Level | HHs:Inc at/Above Poverty Level | Total Businesses (SIC) | Construction Businesses (NAICS) | Retail Trade Businesses (NAICS) | Transportation/Warehouse Bus (NAICS) | Own any tablet | Own any e-reader | Have access to Internet at home | Index: Spend 0.5-0.9 hrs online(excl email/IM . | Spend <0.5 hrs online (excl email/IM time) daily | 2019 Total Population | 2019 Male Population | 2019 Female Population | 2019 Employed Civilian Pop 16+ | 2019 Unemployed Population 16+ | 2019 Unemployment Rate | ACS Workers Age 16+ | ACS Workers 16+: Drove Alone | ACS Workers 16+: Carpooled | ACS Workers 16+: Public Transportation | ACS Workers 16+: Bus | ACS Workers 16+: Streetcar | ACS Workers 16+: Subway | ACS Workers 16+: Ferryboat | ACS Workers 16+: Taxicab | ACS Workers 16+: Motorcycle | ACS Workers 16+: Bicycle | ACS Workers 16+: Walked | ACS Workers 16+: Other Means | ACS Wrkrs 16+: Worked at Home | 2019 Owner Occupied HUs | 2019 Renter Occupied HUs | 2019 Vacant Housing Units | 2019 Median Home Value | 2019 Total Housing Units | ACS Median Year Structure Built: HUs | 2019 Annual Budget Exp | 2019 Transportation | 2019 Daytime Pop: Workers | 2019 Daytime Pop: Residents | 2019 Daytime Pop Density | 2019 Occupation: Protective Service | 2019 Occupation: Food Preperation | 2019 Occupation: Personal Care | 2019 Occupation: Office/Admin | 2019 Occupation: Construction/Extraction | 2019 Occupation: Production | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2163 | 36047990100 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| 2165 | 36085990100 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
# checking total number of nan values
nan_test = sdf_airbnb_count_by_tract_enriched_sorted_new.drop(['geoid'], axis=1)
np.isnan(nan_test).sum().sum()0
These two tracts area actually are water areas within NYC, hence have nan values and are filled with zeros
sdf_airbnb_count_by_tract_enriched_sorted_fill = sdf_airbnb_count_by_tract_enriched_sorted_new.fillna(0)
#nan rechecked
nan_test = sdf_airbnb_count_by_tract_enriched_sorted_fill.drop(['geoid'], axis=1)
np.isnan(nan_test).sum().sum()0
Merging the distance data with the enriched data
final_df = pd.merge(tract_merge_dist_final,
sdf_airbnb_count_by_tract_enriched_sorted_fill,
left_on = 'geoid',
right_on = 'geoid',
how = 'left')
print(final_df.shape)
final_df.head()(2167, 97)
| geoid | total_airbnb | hotel_dist | subwy_rt_dist | railroad_dist | subwy_stn_dist | busi_distr_dist | cbd_dist | num_bustop | boro_name_Bronx | boro_name_Brooklyn | boro_name_Manhattan | boro_name_Queens | boro_name_Staten Island | Employed Population Age 16+ | Employed Male Pop Age 16+ | Male 16+Priv Nonprofit | Male 16+:Priv Profit Empl | Male 16+:Priv Profit Self Empl | Male 16+:State Govt Wrkr | Male 16+:Fed Govt Wrkr | Male 16+:Self-Emp Not Inc | Male 16+:Unpaid Family Wrkr | Female Pop Age 16+ | Female 16+:Priv Profit Empl | Female 16+:Priv Profit Self Empl | Female 16+:Priv Nonprofit | Female 16+:Local Govt Wrkr | Female 16+:State Govt Wrkr | Female 16+:Fed Govt Wrkr | Female 16+:Self-Emp Not Inc | Female 16+:Unpaid Family Wrkr | 2019 Median Age | 2019 Generation Alpha Population | 2019 Generation Z Population | 2019 Millennial Population | 2019 Generation X Population | 2019 Baby Boomer Population | 2019 Silent & Greatest Generations Population | 2019 Population by Generation Base | 2019 Population Density | 2019 Total Daytime Population | 2019 White Population | 2019 Black Population | 2019 American Indian Population | 2019 Asian Population | 2019 Pacific Islander Population | 2019 Other Race Population | 2019 Diversity Index | HHs: Inc Below Poverty Level | HHs:Inc at/Above Poverty Level | Total Businesses (SIC) | Construction Businesses (NAICS) | Retail Trade Businesses (NAICS) | Transportation/Warehouse Bus (NAICS) | Own any tablet | Own any e-reader | Have access to Internet at home | Index: Spend 0.5-0.9 hrs online(excl email/IM . | Spend <0.5 hrs online (excl email/IM time) daily | 2019 Total Population | 2019 Male Population | 2019 Female Population | 2019 Employed Civilian Pop 16+ | 2019 Unemployed Population 16+ | 2019 Unemployment Rate | ACS Workers Age 16+ | ACS Workers 16+: Drove Alone | ACS Workers 16+: Carpooled | ACS Workers 16+: Public Transportation | ACS Workers 16+: Bus | ACS Workers 16+: Streetcar | ACS Workers 16+: Subway | ACS Workers 16+: Ferryboat | ACS Workers 16+: Taxicab | ACS Workers 16+: Motorcycle | ACS Workers 16+: Bicycle | ACS Workers 16+: Walked | ACS Workers 16+: Other Means | ACS Wrkrs 16+: Worked at Home | 2019 Owner Occupied HUs | 2019 Renter Occupied HUs | 2019 Vacant Housing Units | 2019 Median Home Value | 2019 Total Housing Units | ACS Median Year Structure Built: HUs | 2019 Annual Budget Exp | 2019 Transportation | 2019 Daytime Pop: Workers | 2019 Daytime Pop: Residents | 2019 Daytime Pop Density | 2019 Occupation: Protective Service | 2019 Occupation: Food Preperation | 2019 Occupation: Personal Care | 2019 Occupation: Office/Admin | 2019 Occupation: Construction/Extraction | 2019 Occupation: Production | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 36005000100 | 0 | 5571.75 | 4780.04 | 2128.12 | 4996.07 | 6909.6 | 26396.02 | 0 | True | False | False | False | False | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 34.5 | 0.0 | 698.0 | 1997.0 | 921.0 | 127.0 | 5.0 | 3748.0 | 3588.6 | 663.0 | 629.0 | 2330.0 | 17.0 | 67.0 | 1.0 | 672.0 | 75.2 | 0.0 | 0.0 | 24.0 | 3.0 | 4.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3748.0 | 3407.0 | 341.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 663.0 | 0.0 | 634.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 36005000200 | 0 | 5486.44 | 5854.07 | 1137.29 | 5851.15 | 6824.43 | 36212.95 | 0 | True | False | False | False | False | 1664.0 | 1068.0 | 51.0 | 709.0 | 0.0 | 43.0 | 0.0 | 38.0 | 0.0 | 596.0 | 316.0 | 15.0 | 78.0 | 115.0 | 60.0 | 12.0 | 0.0 | 0.0 | 35.8 | 430.0 | 1218.0 | 1245.0 | 913.0 | 823.0 | 168.0 | 4797.0 | 8988.5 | 3210.0 | 438.0 | 1195.0 | 69.0 | 217.0 | 7.0 | 2150.0 | 83.6 | 278.0 | 1114.0 | 42.0 | 2.0 | 2.0 | 5.0 | 2177.0 | 437.0 | 3469.0 | 86.0 | 123.0 | 4797.0 | 2249.0 | 2548.0 | 1834.0 | 192.0 | 9.5 | 1664.0 | 766.0 | 13.0 | 619.0 | 235.0 | 0.0 | 362.0 | 22.0 | 39.0 | 0.0 | 0.0 | 200.0 | 0.0 | 27.0 | 767.0 | 766.0 | 78.0 | 558333.0 | 1611.0 | 1957.0 | 132707872.0 | 13576654.0 | 196.0 | 3014.0 | 6014.9 | 48.0 | 106.0 | 15.0 | 162.0 | 33.0 | 130.0 |
| 2 | 36005000400 | 15 | 2495.67 | 6293.88 | 3741.15 | 6291.15 | 8428.97 | 38659.77 | 1 | True | False | False | False | False | 3128.0 | 1675.0 | 253.0 | 932.0 | 21.0 | 38.0 | 104.0 | 75.0 | 0.0 | 1453.0 | 804.0 | 37.0 | 276.0 | 281.0 | 16.0 | 39.0 | 0.0 | 0.0 | 35.7 | 506.0 | 1589.0 | 1589.0 | 1226.0 | 945.0 | 166.0 | 6021.0 | 10291.0 | 3758.0 | 641.0 | 1803.0 | 60.0 | 240.0 | 6.0 | 2278.0 | 85.4 | 107.0 | 2092.0 | 57.0 | 3.0 | 9.0 | 3.0 | 2754.0 | 730.0 | 4455.0 | 103.0 | 172.0 | 6021.0 | 2937.0 | 3084.0 | 2807.0 | 120.0 | 4.1 | 3082.0 | 1628.0 | 61.0 | 1077.0 | 250.0 | 0.0 | 776.0 | 33.0 | 0.0 | 0.0 | 0.0 | 130.0 | 64.0 | 122.0 | 1548.0 | 537.0 | 108.0 | 552034.0 | 2193.0 | 2001.0 | 197321413.0 | 20238565.0 | 471.0 | 3287.0 | 6423.1 | 239.0 | 83.0 | 96.0 | 429.0 | 99.0 | 42.0 |
| 3 | 36005001600 | 1 | 3093.96 | 3824.42 | 3244.59 | 3852.61 | 6534.63 | 39734.83 | 1 | True | False | False | False | False | 2513.0 | 959.0 | 31.0 | 620.0 | 29.0 | 0.0 | 18.0 | 20.0 | 0.0 | 1554.0 | 927.0 | 7.0 | 159.0 | 296.0 | 90.0 | 51.0 | 24.0 | 0.0 | 36.6 | 477.0 | 1384.0 | 1313.0 | 996.0 | 997.0 | 350.0 | 5517.0 | 29457.3 | 5334.0 | 497.0 | 2127.0 | 70.0 | 123.0 | 3.0 | 1900.0 | 84.6 | 526.0 | 1661.0 | 57.0 | 0.0 | 7.0 | 2.0 | 2392.0 | 491.0 | 3950.0 | 80.0 | 114.0 | 5517.0 | 2394.0 | 3123.0 | 2087.0 | 183.0 | 8.1 | 2422.0 | 880.0 | 73.0 | 1154.0 | 604.0 | 0.0 | 538.0 | 12.0 | 19.0 | 0.0 | 12.0 | 110.0 | 29.0 | 145.0 | 295.0 | 1712.0 | 103.0 | 650463.0 | 2110.0 | 1973.0 | 117903160.0 | 11830562.0 | 1831.0 | 3503.0 | 28480.2 | 101.0 | 104.0 | 35.0 | 299.0 | 3.0 | 21.0 |
| 4 | 36005001900 | 24 | 0.0 | 15.06 | 0.0 | 422.73 | 2696.02 | 22881.35 | 1 | True | False | False | False | False | 1790.0 | 887.0 | 144.0 | 580.0 | 46.0 | 0.0 | 7.0 | 41.0 | 17.0 | 903.0 | 585.0 | 15.0 | 133.0 | 64.0 | 17.0 | 0.0 | 89.0 | 0.0 | 36.1 | 362.0 | 946.0 | 1286.0 | 885.0 | 553.0 | 134.0 | 4166.0 | 3876.6 | 8595.0 | 637.0 | 1656.0 | 62.0 | 67.0 | 5.0 | 1236.0 | 85.8 | 323.0 | 938.0 | 409.0 | 75.0 | 45.0 | 26.0 | 1836.0 | 347.0 | 3093.0 | 80.0 | 94.0 | 4166.0 | 2182.0 | 1984.0 | 2152.0 | 114.0 | 5.0 | 1751.0 | 279.0 | 89.0 | 1054.0 | 142.0 | 14.0 | 898.0 | 0.0 | 16.0 | 0.0 | 21.0 | 75.0 | 35.0 | 182.0 | 118.0 | 1486.0 | 124.0 | 381395.0 | 1728.0 | 1964.0 | 118882651.0 | 12251786.0 | 6516.0 | 2079.0 | 7998.0 | 32.0 | 127.0 | 162.0 | 177.0 | 58.0 | 64.0 |
# rechecking nan values of the final dataframe
final_nan_test = final_df.drop('geoid', axis=1)
np.isnan(final_nan_test).sum().sum()0
Model Building
The goal here is to find the factors contributing towards the development of new Airbnb properties in New York City. Thus a model is fitted predicting the number of Airbnb properties per tract with the feature set composed of the distance and demographics characteristics of each tract. Once a good fit is obtained the most important predictors of the model are estimated which is our main ask.
# Creating feature data
X = final_df.drop(['geoid','total_airbnb'], axis=1)
# Creating target data -- the number airbnb per tract
y = pd.DataFrame(final_df['total_airbnb'])split the dataframe into train - test of 90% to 10%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.10, random_state = 20)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# Converting the target into 1d array
y_train_array = y_train.values.flatten()
y_test_array = y_test.values.flatten()
print(y_train_array.shape)
print(y_test_array.shape)(1950, 95) (1950, 1) (217, 95) (217, 1) (1950,) (217,)
As a best practice since scaled data performs well for model fitting, the features are normalized using Robust scaler
scaler = preprocessing.RobustScaler()
X_train_scaled = pd.DataFrame(scaler.fit_transform(X_train), columns = X_train.columns)
X_test_scaled = pd.DataFrame(scaler.fit_transform(X_test), columns=X_test.columns)RandomForest Regressor Model
The modelling is first started using a linear regression. However the linear model was failing to fit the data well. Hence it was carried out with a non linear algorithm as follows. This could be tested by the user to see the improvement of using Random Forest over a linear regression.
The accuracy metrics of mean absoute error and r-square is used
# Random forest with scaled data
# for the best parameters a grid search could be done which could take some time
# however this model uses the default parameters of RF algorithm, while the estimators are changed till the best fit is obtained
model_RF = RandomForestRegressor(n_estimators = 500, random_state=43)
# Train the model
model_RF.fit(X_train_scaled, y_train_array)
# Training metrics for Random forest model
print('Training metrics for Random forest model using scaled data')
ypred_RF_train = model_RF.predict(X_train_scaled)
print('r-square_RF_Train: ', round(model_RF.score(X_train_scaled, y_train_array), 2))
mse_RF_train = metrics.mean_squared_error(y_train_array, ypred_RF_train)
print('RMSE_RF_train: ', round(np.sqrt(mse_RF_train),4))
mean_absolute_error_RF_train = metrics.mean_absolute_error(y_train_array, ypred_RF_train)
print('MAE_RF_train: ', round(mean_absolute_error_RF_train, 4))
# Test metrics for Random Forest model
print('\nTest metrics for Random Forest model scaled data')
ypred_RF_test = model_RF.predict(X_test_scaled)
print('r-square_RF_test: ', round(model_RF.score(X_test_scaled, y_test_array), 2))
mse_RF_test = metrics.mean_squared_error(y_test_array, ypred_RF_test)
print('RMSE_RF_test: ', round(np.sqrt(mse_RF_test), 4))
mean_absolute_error_RF_test = metrics.mean_absolute_error(y_test_array, ypred_RF_test)
print('MAE_RF_test: ', round(mean_absolute_error_RF_test, 4))Training metrics for Random forest model using scaled data r-square_RF_Train: 0.97 RMSE_RF_train: 6.9747 MAE_RF_train: 3.4844 Test metrics for Random Forest model scaled data r-square_RF_test: 0.77 RMSE_RF_test: 22.2146 MAE_RF_test: 10.2689
The result shows that the model is returning an r-square of 0.85 with a mean absolute error of 9.28
Feature importance for the RF model
feature_imp_RF = model_RF.feature_importances_
#relative feature importance
rel_feature_imp = 100 * (feature_imp_RF / max(feature_imp_RF))
rel_feature_imp = pd.DataFrame({'features':list(X_train.columns),
'rel_importance':rel_feature_imp })
rel_feature_imp = rel_feature_imp.sort_values('rel_importance', ascending=False)
#plotting the top twenty important features
top20_features = rel_feature_imp.head(20)
plt.figure(figsize=[20,10])
plt.yticks(fontsize=15)
ax = sns.barplot(x="rel_importance", y="features",
data=top20_features,
palette="Accent_r")
plt.xlabel("Relative Importance", fontsize=25)
plt.ylabel("Features", fontsize=25)
plt.show()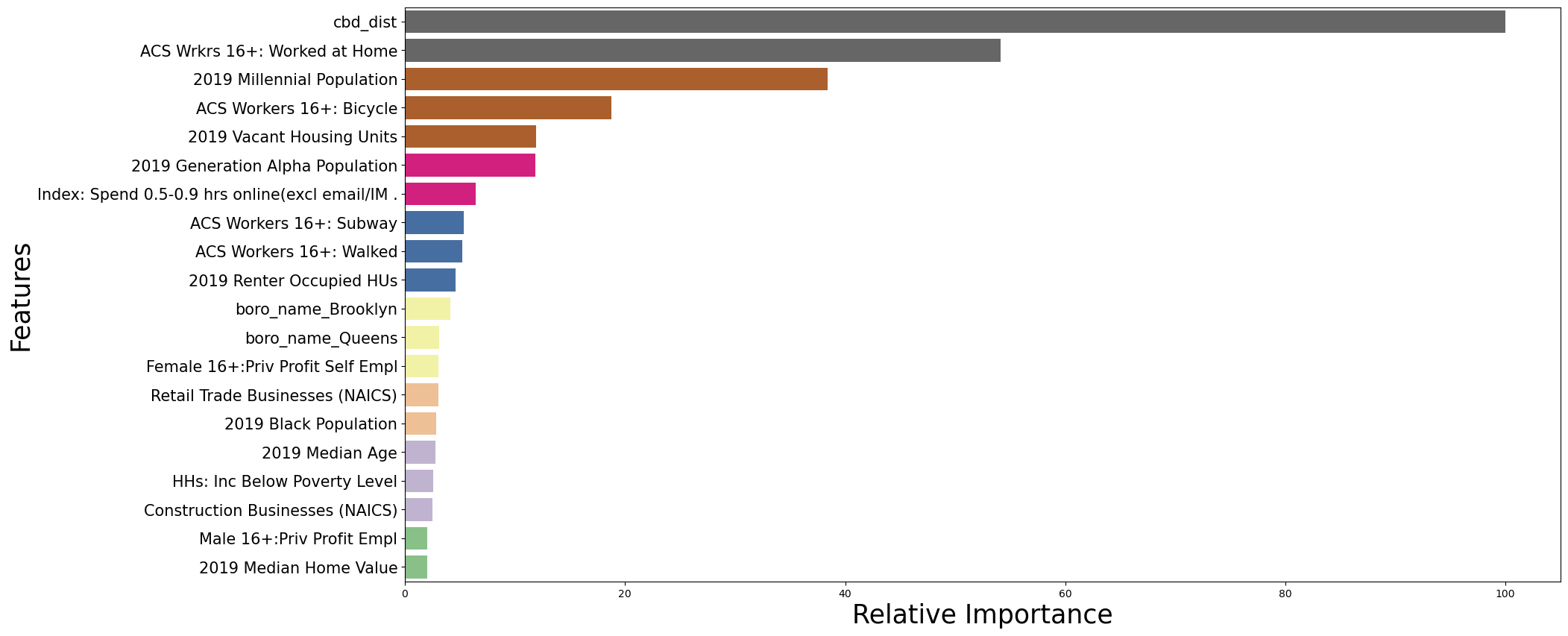
rel_feature_imp.head()| features | rel_importance | |
|---|---|---|
| 5 | cbd_dist | 100.000000 |
| 77 | ACS Wrkrs 16+: Worked at Home | 54.125825 |
| 33 | 2019 Millennial Population | 38.377447 |
| 74 | ACS Workers 16+: Bicycle | 18.789531 |
| 80 | 2019 Vacant Housing Units | 11.898179 |
The feature importance plot reveals that distance from the city centre (cbd_dist) is the most important predictor of the number of Airbnb formation in NYC. This is expected since hotel rents near the cbd are quite high, rental income from Airbnb properties would be high as well, hence setting up Airbnb property would be a lucrative option, compared to long term rental income in areas near the cbd.
This is followed by the number of millennial population, or the tracts having most number of people in the age group of 25 to 40 years old. One reason might be that these group of population are more active online and are comfortable with internet technologies which is in a way a necessary prerequisite for setting up Airbnb properties. This is supported by the presence of another interesting predictor variable of -- 0.5-0.9 hrs online activity, in the top twenty.
This is followed by the tracts having workers who commute by bicycle and is the third most important predictor, which is followed by the number of generation alpha population, who are person born after 2011, and then by tracts having people commuting by subway, and so on. The median home value of the tracts is also an interesting predictor.
Gradient Boosting Regressor Model
Here trial shows that the gradient boosting model performs better with non scale data
# GradientBoosting with non scaled data
# this model uses the default parameters of GB algorithm, while the estimators are changed to obtain the best fit
model_GB_nonscale = GradientBoostingRegressor(n_estimators=500, random_state=60)
# Train the model
model_GB_nonscale.fit(X_train, y_train_array)
# Training metrics for Gradient Boosting Regressor model
print('Training metrics for Gradient Boosting Regressor model using scaled data')
ypred_GB_train = model_GB_nonscale.predict(X_train)
print('r-square_GB_Train: ', round(model_GB_nonscale.score(X_train, y_train_array), 2))
mse_RF_train = metrics.mean_squared_error(y_train_array, ypred_GB_train)
print('RMSE_GB_Train: ', round(np.sqrt(mse_RF_train), 4))
mean_absolute_error_RF_train = metrics.mean_absolute_error(y_train_array, ypred_GB_train)
print('MAE_GB_Train: ', round(mean_absolute_error_RF_train, 4))
#Test metrics for Gradient Boosting Regressor model
print('\nTest metrics for Gradient Boosting Regressor model using scaled data')
ypred_GB_test = model_GB_nonscale.predict(X_test)
print('r-square_GB_Test: ', round(model_GB_nonscale.score(X_test, y_test_array),2))
mse_RF_Test = metrics.mean_squared_error(y_test_array, ypred_GB_test)
print('RMSE_GB_Test: ', round(np.sqrt(mse_RF_Test),4))
mean_absolute_error_GB_Test = metrics.mean_absolute_error(y_test_array, ypred_GB_test)
print('MAE_GB_Test: ', round(mean_absolute_error_GB_Test, 4))Training metrics for Gradient Boosting Regressor model using scaled data r-square_GB_Train: 0.99 RMSE_GB_Train: 3.1363 MAE_GB_Train: 2.3217 Test metrics for Gradient Boosting Regressor model using scaled data r-square_GB_Test: 0.81 RMSE_GB_Test: 20.0925 MAE_GB_Test: 9.5355
The result shows that the Gradient boosting regressor model is performing slightly better both in terms of Mean Absolute error and r-square than the random forest model.
Feature Importance of Gradient Boosting Model
#checking the feature importance for the Gradient Boosting regressor
feature_imp_GB = model_GB_nonscale.feature_importances_
rel_feature_imp_GB = 100 * feature_imp_GB / max(feature_imp_GB)
rel_feature_imp_GB = pd.DataFrame({'features':list(X_train.columns),
'rel_importance':rel_feature_imp_GB})
rel_feature_imp_GB = rel_feature_imp_GB.sort_values('rel_importance', ascending=False)
rel_feature_imp_GB.head()| features | rel_importance | |
|---|---|---|
| 5 | cbd_dist | 100.000000 |
| 77 | ACS Wrkrs 16+: Worked at Home | 57.804037 |
| 74 | ACS Workers 16+: Bicycle | 48.524487 |
| 33 | 2019 Millennial Population | 37.625884 |
| 80 | 2019 Vacant Housing Units | 24.284889 |
# Plot feature importance for the Gradient Boosting regressor
top20_features_GB = rel_feature_imp_GB.head(20)
plt.figure(figsize=[20,10])
plt.yticks(fontsize=15)
ax = sns.barplot(x="rel_importance", y="features", data = top20_features_GB, palette="Accent_r")
plt.xlabel("Relative Importance", fontsize=25)
plt.ylabel("Features", fontsize=25)
plt.show()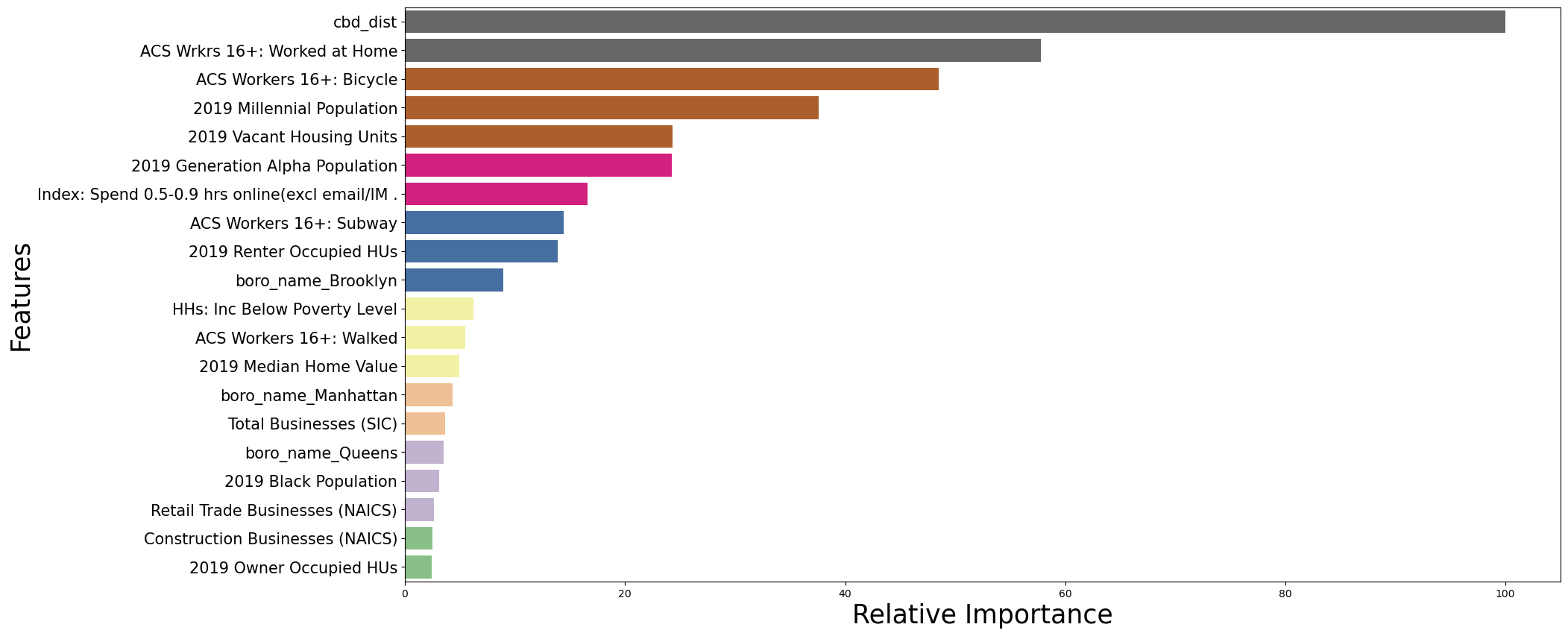
The feature importance shown by the Gradient boosting model are almost identical to the one returned by the random forest model, which is expected.
Running cross validation
The above model is fitted and accuracy measured on a particular train and test split of the data. However the model accuracy for multiple split of the data remains to be seen. This is accomplished using k fold cross validation which splits the data into k different train-test splits and fit the model for each of them. Hence a 10 fold cross validation is run to check the overall model accuracy which is measured here as the mean absolute error for model fit accross the 10 different splits.
# Validating with a 10 fold cross validation for the Gradient Boosting models
y_array = y.values.flatten()
modelGB_cross_val = GradientBoostingRegressor(n_estimators=500, random_state=60)
modelGB_cross_val_scores = cross_val_score(modelGB_cross_val,
X,
y_array,
cv=10,
scoring='neg_mean_absolute_error')
print("All Model Scores: ", modelGB_cross_val_scores)
print("Negative Mean Absolute Error: {}".format(np.mean(modelGB_cross_val_scores)))All Model Scores: [ -6.8058649 -11.62520912 -11.02025161 -21.53356819 -4.63056795 -41.11872138 -14.46560863 -9.15669676 -6.10330726 -4.9869393 ] Negative Mean Absolute Error: -13.1446735095419
# Validating with a 10 fold cross validation for the Random forest models
y_array = y.values.flatten()
modelRF_cross_val = RandomForestRegressor(n_estimators=500, random_state=43)
modelRF_cross_val_scores = cross_val_score(modelRF_cross_val,
X,
y_array,
cv=10,
scoring='neg_mean_absolute_error')
print("All Model Scores: ", modelRF_cross_val_scores)
print("Negative Mean Absolute Error: {}".format(np.mean(modelRF_cross_val_scores)))All Model Scores: [-10.648 -9.98169585 -10.22411982 -22.20942857 -4.53489401 -37.69979724 -16.13404608 -12.30612963 -6.35166667 -4.42249074] Negative Mean Absolute Error: -13.45122686038573
Final Result Visualization
# Plotting a kernel density map of the predicted vs. observed data
plt.figure(figsize=[15,5])
# plotting the prediction
sns.kdeplot(ypred_RF_test, label = 'Predictions', color = 'orange')
y_observed = np.array(y_test).reshape((-1, ))
sns.kdeplot(y_observed, label = 'Observation', color = 'green')
# label the plot
plt.xlabel('No. of Airbnb listings per census tract', fontsize=15)
plt.ylabel('Density', fontsize=15)
plt.title('Density Plot: Predicted vs Observed', fontsize=15)
plt.xticks(range(0,500,25), fontsize=10)
plt.yticks(fontsize=10)
plt.legend(fontsize=15)
plt.show()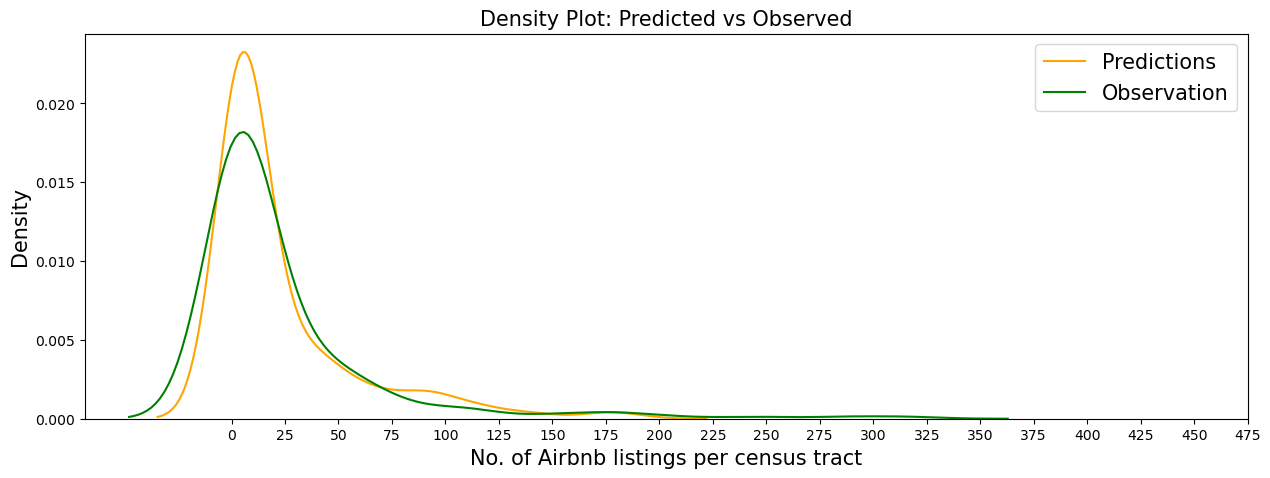
# Converting the predicted and observed values to dataframe and plotting the observed vs predicted
y_test_df = y_test.copy()
y_test_df['Predicted'] = (ypred_RF_test)
y_test_df.head()| total_airbnb | Predicted | |
|---|---|---|
| 20 | 4 | 6.006 |
| 910 | 6 | 3.980 |
| 685 | 2 | 4.572 |
| 450 | 1 | 2.000 |
| 1044 | 2 | 8.080 |
# plotting the actual observed vs predicted airbnb properties by tract
plt.figure(figsize = [25,12])
sns.set(style = 'whitegrid')
sns.lineplot(data = y_test_df, markers=True)
#label the plot
plt.xlabel('Tract ID', fontsize=15)
plt.ylabel('Total No. of Airbnb', fontsize=15)
plt.title('Actual No. of Airbnb by Tract: Predicted vs Observed', fontsize=15)
plt.xticks(range(0,2000,100), fontsize=15)
plt.yticks(fontsize=15)
plt.legend(fontsize='x-large', title_fontsize='10')
plt.legend(fontsize=15)
plt.show()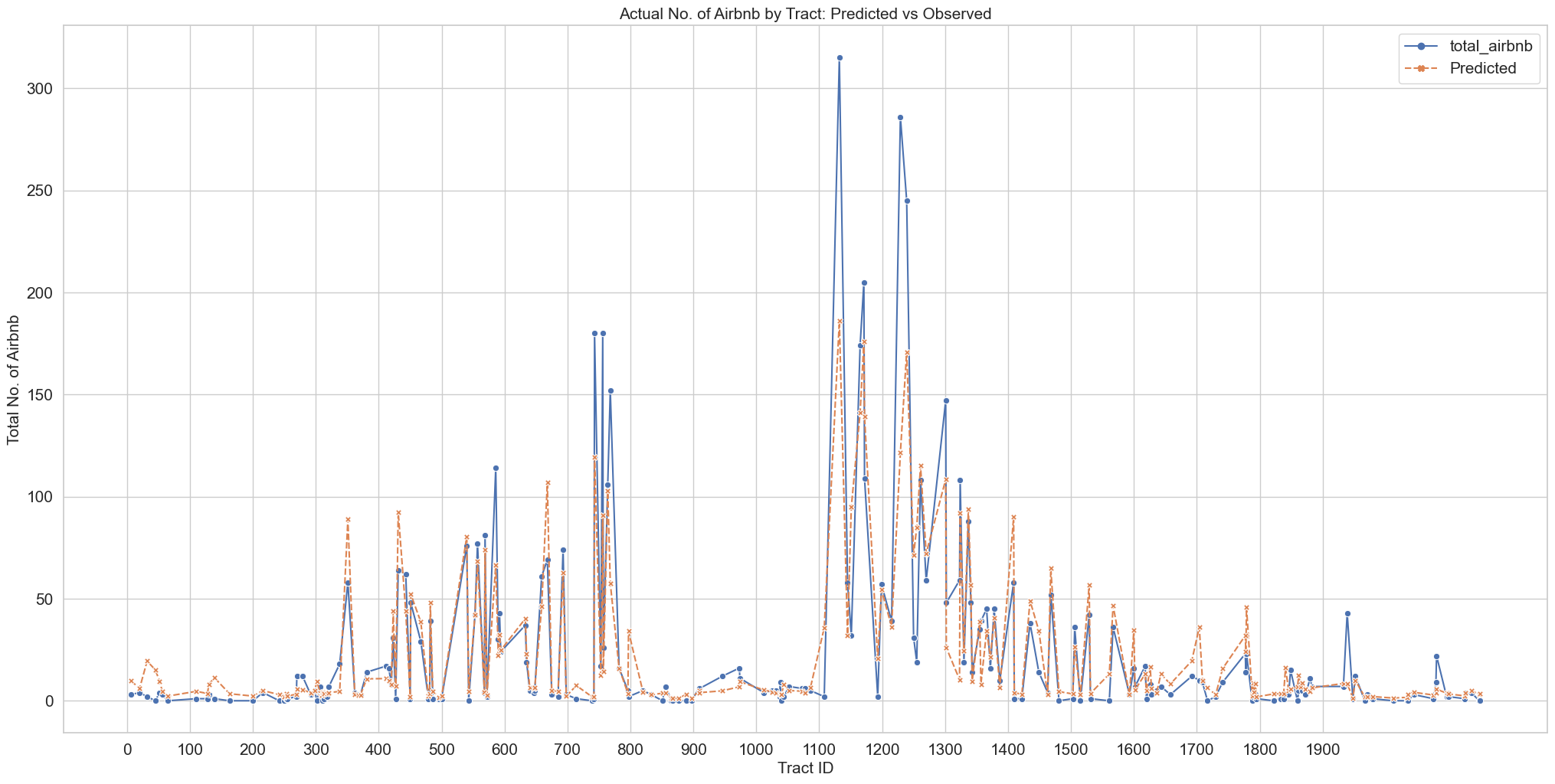
The plot shows that the predicted values closely matches the observed values. However there are instances of underprediction for tracts with extremely high number of airbnb properties, and also overprediction instances for some tracts with comparatively lower number of airbnb properties.
Conclusion
The study shows that the location factor of distance from CBD is the foremost important factor which stimulates creation of Airbnb properties.
The proximity tool from the ArcGIS API for Python was used to perform this significant task for all the distance estimation. Other factors as returned by the feature importance result could be dealt individually. Another interesting capability of Esri utilized in the study is that of Esri's data repository, elaborated here via the geoenrichment services. The data enrichment service could provide the analyst an wide array of data that could be used for critical analysis. Further analysis would be done in the next study on this dataset.
Summary of methods used
| Method | Question | Examples |
|---|---|---|
| aggregate_points | How many points within each polygon? | Counting the number of airbnb rentals within each NYC tracts |
| Data Enrichment | Which demographic attribute are relevant for the problem? | Population of Millennials for each tract |
| find_nearest | Which distances from city features are relevant for the problem? | Distance of the CBD from each tract |